










前面两篇博客介绍了一下内部排序,也就是待排序的文件或数据可以一次加载进内存,之后进行排序;
读者可以参考之前的博客:
http://blog.csdn.net/chengzi_comm/article/details/51429165
http://blog.csdn.net/chengzi_comm/article/details/51494251
与之相对的就是外排序,即文件很大,不能一次性加载进内存,这时候怎么对这个文件进行排序呢?
今天介绍一下自己实现的一个外排序:
外排序(External sorting)是指能够处理极大量数据的排序算法。通常来说,外排序处理的数据不能一次装入内存,只能放在读写较慢的外存储器(通常是硬盘)上。
比如,要对900 MB的数据进行排序,但机器上只有100 MB的可用内存时,就可以把大文件分多次读入内存,并对对如的数据进行排序,之后写到一个临时文件中,经过多次之后,得到若干有序的小文件,这时对这些小文件进行归并排序就,把结果再写回文件,可以达到对大文件排序的效果。
下面是外排序的思想,这幅图能很好地反映外排序的过程,自己也基本按照这个流程来的,只不过在合并文件上,与图中所示的稍有差别。
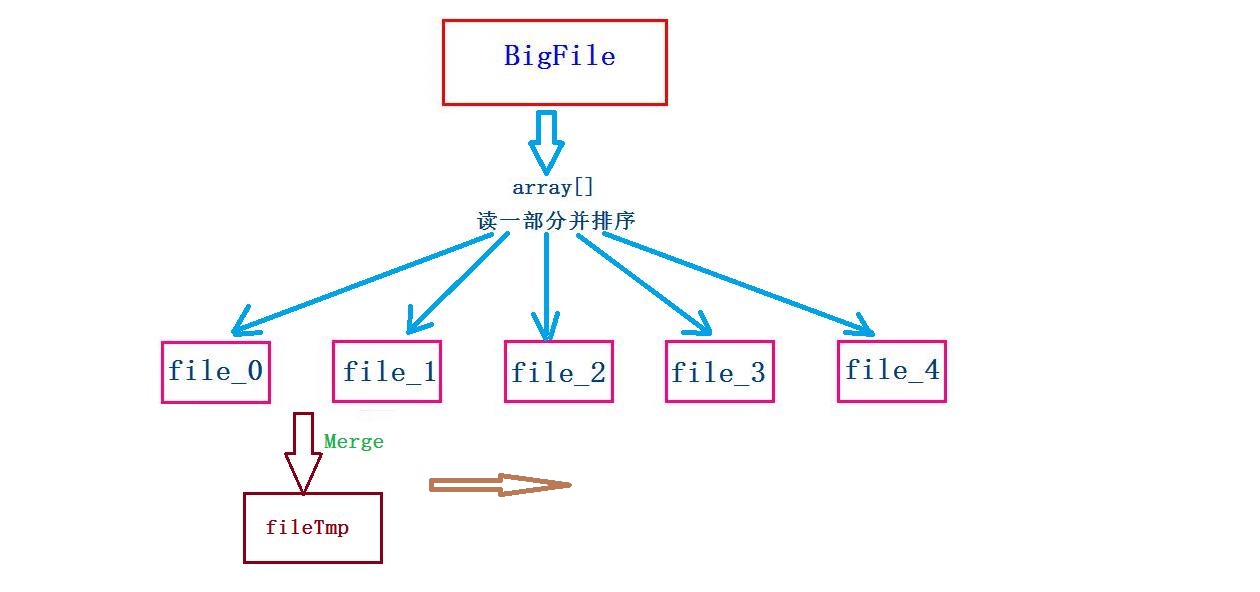
下面给出外排序的实现:
(释较详细,我就不一一解释了)
/*************************************************************************************
> File Name: ExternalSort.cpp
> Author: common
> Mail: yp_abc2015@163.com
> Created Time: Вс. 17 апр. 2016 19:38:27
************************************************************************************/
#include <iostream>
#include <stdio.h>
#include <assert.h>
#include <errno.h>
#include <error.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
using namespace std;
const int TOTAL_SIZE = 100000; //大文件中数字的个数
const int NAME_SIZE = 20; //文件名的最大长度
const int MAX_MEM = 50; //内存每次最多能放MAX_MEM个整型数据
int FILE_NAME = 0; //外部排序需要很多临时文件,这个变量用于每个文件后面的标识, 例如: file_0, file_1
bool END_OF_FILE = false; //文件是否读到尾
bool FP1_END = false; //归并时,文件1是否读到尾
bool FP2_END = false; //归并时,文件2是否读到尾
bool NULL_ARRAY = false; //当TOTAL_SIZE是MAX_MEM的整数倍时,最后可能会生成一个空文件,用这个判断,防止空文件产生(强迫症)
const int MAXLINE = 20; //每行读取的最多字符数
char *buf[MAXLINE]; //读一行到buf中
int STDOUT_BACKUP = -1; //程序中用了很多的重定向,这个变量用于记录最开始的状态,以便重定向之后恢复,稍后讲
//单向的快速排序,只需要一个指针从前往后扫描, 该方法特别适合链表的排序 ******
void QuickSort_OneWay(int *arr, int begin, int end) // [begin, end]
{
if(NULL == arr || begin >= end)
return ;
int index = begin+1; //往后找比key小的数******
int key = arr[begin]; //相当于枢轴
int mid = begin; //相当于partition,用于标记左右有序的分界******
for(index=begin+1 ; index <= end; ++index)
{
if(arr[index] < key) //找小
{
if(++mid != index) //防止自己跟自己交换
std::swap(arr[index], arr[mid]);
}
}
std::swap(arr[begin], arr[mid]); //mid位置处放入枢轴
QuickSort_OneWay(arr, begin, mid-1); //递归排序左半部分
QuickSort_OneWay(arr, mid+1, end); //递归排序左半部分
}
//从fd里面每次读一行字符到readbuf中, 返回读到的字符个数
int readline(int fd, char *readbuf)
{
char *ptr = readbuf;
char ch = '\0';
int sz = 0;
int retSum = 0;
while(1)
{
again:
if((sz = read(fd, &ch, 1)) < 0) //error
{
if(errno = EINTR)
goto again;
return -1;
}
else if(sz > 0 && ch != '\n')
{
*ptr++ = ch;
retSum += sz;
}
else //EOF || ch == '\n'
{
break;
}
}
ptr[retSum] = '\0';
return retSum; //返回读到的字符个数
}
//从fd文件所指的文件中读取一个数字
int GetNum(int fd)
{
assert(fd);
int num = -1;
char str[MAXLINE];
bzero(str, sizeof(str));
int sz = 0;
if ((sz = readline(fd, str)) < 0) //Error
{
perror("GetNum");
exit(1);
}
else if(sz > 0) //OK, 得到一个数
{
num = atoi(str); //得到的是一个字符串,需转化成一个整型
}
else //EOF
{
END_OF_FILE = true; //文件读完了
}
return num;
}
//从bigfile所指向的文件中每次读取MAX_MEM个数字,并把它们排好序写到一个临时文件 file_x 中( x == 0.1.2 ... )
void ReadFromBigFileThenSort(int bigfile)
{
int array[MAX_MEM] = {0}; //临时数组 用于接收从文件中读到的数并排序用
int realLen = 0; //数组的实际元素个数,可能读不满就把文件读完了
int tmp = -1;
for(int i = 0; i < MAX_MEM; ++i)
{
tmp = GetNum(bigfile);
if(!END_OF_FILE) //没读到文件尾,说明tmp存放的是有效数据
{
array[i] = tmp;
++realLen;
}
else //读到了文件尾,直接break;
break;
}
if(realLen == 0) //刚好一个数都没有读到,就到文件尾
{
NULL_ARRAY = true; //空数组的条件
return ;
}
QuickSort_OneWay(array, 0, realLen-1); //对数组使用快速排序进行排序
char *path = new char[10];
sprintf(path, "./file_%d", FILE_NAME++); //构造一个有序的临时文件名
creat(path, S_IWUSR | S_IRUSR);
int fileno = -1;
if( (fileno = open(path, O_RDWR)) < 0) //创建临时文件
{
perror("open");
exit(1);
}
dup2(fileno, STDOUT_FILENO);
for(int i = 0; i<realLen; ++i)
cout<<array[i]<<endl; //把数组中已经排好序的数字写到临时文件中
fflush(stdout);
dup2(STDOUT_BACKUP, STDOUT_FILENO); //恢复重定向
delete[] path;
close(fileno);
}
//归并两个文件到另一个文件
void MergeFile(int fp1, int fp2, int fp) //合并fp1,fp2到fp
{
assert((fp1 || fp2) && fp);
FP1_END = false; //fp1没有读到文件尾
FP2_END = false; //fp2没有读到文件尾
bool F1GoOn = true; //fp1可以往下读一个数
bool F2GoOn = true; //fp2可以往下读一个数
lseek(fp, 0, SEEK_SET); //fp可能的指针可能不在文件开始处,因为要拷贝到fp中,所以需要把指针重定位到开始处
dup2(fp, STDOUT_FILENO);
int num1 = -1, num2 = -1;
while(!FP1_END && !FP2_END)
{
if(F1GoOn && (num1 = GetNum(fp1)) < 0) //fp1可以往下读一个数,并且fp1数据已经读完 (读到文件尾时,GetNum返回-1)
{
FP1_END = true;
break;
}
if(F2GoOn && (num2 = GetNum(fp2)) < 0)
{
FP2_END = true;
break;
}
if(num1 <= num2) //插入二者当中较小的一个
{
F1GoOn = true; //下一次循环,fp1可以往下读数据
F2GoOn = false; //fp2暂时不能往下读
cout<<num1<<endl; //把较小者写入文件
}
else
{
F2GoOn = true;
F1GoOn = false;
cout<<num2<<endl;
}
fflush(stdout);
}
if(num1 >= 0) //可能fp2已经读完数据,此时num1中仍保留一个有效数据
{
cout<<num1<<endl;
fflush(stdout);
}
while(!FP1_END) //插入fp1中剩下的数据
{
if((num1 = GetNum(fp1)) < 0)
{
FP1_END = true;
break;
}
cout<<num1<<endl;
fflush(stdout);
}
if(num2 >= 0) //可能fp1已经读完数据,此时num2中仍保留一个有效数据
{
cout<<num2<<endl;
fflush(stdout);
}
while(!FP2_END) //插入fp2中剩下的数据
{
if((num2 = GetNum(fp2)) < 0)
{
FP2_END = true;
break;
}
cout<<num2<<endl;
fflush(stdout);
}
}
//void CopyFile(int src, int dst) //从src --> dst
//{
// assert(src && dst);
//
// END_OF_FILE = false;
// lseek(src, 0, SEEK_SET);
// lseek(dst, 0, SEEK_SET); //文件位置重定位到开始处
//
// dup2(dst, STDOUT_FILENO); //重定向
//
// int num = -1;
// while(!END_OF_FILE)
// {
// if((num = GetNum(src)) < 0)
// {
// END_OF_FILE = true;
// break;
// }
// cout<<num<<endl;
// fflush(stdout);
// }
//}
int main()
{
int bigfile = -1; //大文件的文件描述符
STDOUT_BACKUP = dup(STDOUT_FILENO); //保存当前的标准输出
int fnum = 0; //小文件个数
if((bigfile = open("./BigFile", O_RDWR )) == -1) //BigFile为可读可写打开
{
perror("open");
exit(1);
}
dup2(bigfile, STDOUT_FILENO);
for(int i = 0; i < TOTAL_SIZE; ++i)//产生一系列随机数
{
long int num = (random() % TOTAL_SIZE);
cout<<num<<endl;
}
dup2(STDOUT_BACKUP, STDOUT_FILENO);
lseek(bigfile, 0, SEEK_SET); //大文件接下来就要读,所以先重定位到文件开始处
while(!END_OF_FILE) //大文件分成小文件, 并且排序
{
ReadFromBigFileThenSort(bigfile);
if(NULL_ARRAY) //不是空数组时,才把文件数加 1
break;
++fnum;
}
int fp[fnum] = {0}; //临时小文件file_0, file_1 ... 文件描述符数组
int file = -1, fileTmp = -1; //最后生成的有序文件文件描述符, 临时文件文件描述符
creat("./File", S_IWUSR | S_IRUSR); //创建File
if( (file = open("./File", O_RDWR)) == -1)
{
perror("open");
close(bigfile);
exit(1);
}
creat("./fileTmp", S_IWUSR | S_IRUSR); //创建fileTmp
if( (fileTmp = open("./fileTmp", O_RDWR)) == -1)
{
perror("open");
close(bigfile);
close(file);
exit(1);
}
char path[NAME_SIZE] = {0};
for(int fileIndex = 0; fileIndex < fnum; ++fileIndex)
{
bzero(path, sizeof(path));
sprintf(path, "./file_%d", fileIndex);
if((fp[fileIndex] = open(path, O_RDONLY)) == -1) //依次打开临时小文件
{
perror("open");
close(bigfile);
close(file);
close(fileTmp);
exit(1);
}
MergeFile(file, fp[fileIndex], fileTmp); //合并临时小文件到fileTmp中
remove("File"); //删除File
rename("fileTmp", "File"); //把fileTmp重命名尾File
file = open("./File", O_RDONLY); //重命名之后还是要重新打开文件
creat("./fileTmp", S_IWUSR | S_IRUSR); //创建一个临时文件,保存两次合并的数,(删除、重命名、建立新文件比在文件间拷贝数据要快)
if( (fileTmp = open("./fileTmp", O_RDWR)) == -1)
{
perror("open");
close(bigfile);
close(file);
exit(1);
}
}
close(bigfile);
close(fileTmp);
return 0;
}
运行程序前,程序目录下必须有一个名为 BigFile 的空文件 :)!!!
















 1905
1905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









