最近在学习潭州教育的大数据课程, 对课堂笔记稍作整理
基础环境
- centos7 64位 5台(bigdata01~05)
- 安装JDK (java变量在最前面 PATH=$JAVA_HOME/bin:$PATH)
- 安装Hadoop2.7.3 、HBase、Hive
- 安装Spark 2.1.0 以及 Scala 2.11.8
Linux基础
- 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
- 设置主机名和IP的对应关系
vi /etc/hosts
192.168.199.201 bigdata201
- tmp目录
- 一旦linux重启, 该目录下所有数据会删除
- HDFS默认的数据保存目录
- ls、ll、ls -a、ls -la
- mkdir、mkdir -p(父目录一齐创建)
- echo 查看环境变量
- cat 第一行开始 、tac 最后一行开始
- cp 复制
- rm -r 删除该目录下的所有文件 -f 强制删除文件和目录
- ps -ef 使用标准格式显示每个进程的信息 |grep 查询(后面紧跟参数)
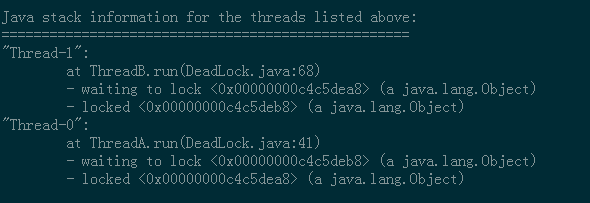
- kill -9 强制杀死 -3 打印java进程的Thread Dump (死锁分析)
- tar 文件、目录打(解)包
| 项目 | 说明 |
|---|
| 隐藏文件 | /root/.bash_profile 环境变量(用户级) |
| 隐藏目录 | /root/.ssh 配置免密码登录(Hadoop和Spark)->公钥和私钥 |
| hdfs dfs -ls / | 查看HDFS的根目录 |
| hdfs dfs -mkdir /input | 创建HDFS输入目录 |
| hdfs dfs -cat /input/data.txt | 查勘HDFS文件内容 |
| hdfs dfs -cp /input/data.txt /input/data2.txt | 复制文件 |
| hdfs dfs -rmr /input/data.txt | 删除文件,hdfs有回收站默认是关闭的 |
| ps -ef|grep redis-server | 查redis-server进程 |
| hdfs dfs -chmod 764 /input/data.txt | 在HDFS中改变文件权限 |
- Linux的权限管理(非常类似HDFS的权限管理)
- r读、w写、x执行(文件目录的权限通过ll、ls -l)共10位
- 第一位-表示文件 d表示目录
- 后9位分成三组表示权限
| 项目 | 说明 | rwx表示 | 二进制表示 | 十进制表示 |
|---|
| 第一组 | 当前用户(读写) | rw- | 110 | 6 |
| 第二组 | 同组的用户(读) | r-- | 100 | 4 |
| 第三组 | 其他人(读) | r-- | 100 | 4 |
- 改变权限: chmod 777 文件名( hdfs dfs -chmod 764 /input/data.txt)
JAVA基础
- JavaSE: 面向对象,I/O输入和输出(HDFS),反射和泛型(MapReduce),JDBC(Hive)
- 死锁分析 线程A等线程B,线程B等线程A
- JDK head dump: 分析OOM的问题 JDK Thread Dump 分析性能瓶颈(线程信息)
- jps命令 打印java程序和进程号
- 得到Thread Dump -> kill -3 PID(子窗口执行,父窗口打印)
- windows ctrl+break(Fn+B)
SQL基础
Hadoop基础
- 数据存储: HDFS
- 数据计算: MapReduce(2.x以后运行在Yarn容器中实现离线计算)
- Hive: 基于HDFS之上的数据仓库,支持SQL
- HBase: 基于HDFS之上的NoSQL数据库
- ZooKeeper: 实现HA(高可用), 实现秒杀
- Sqoop: 数据采集引擎
- Flume: 数据采集引擎
- Pig: 数据分析引擎
实时计算基础
- Redis: 内存NoSQL数据库, Redis Cluster 分布式解决方案
- Storm: 进行实时计算(流式计算,存储到redis)
Spark
- 只有数据计算,没有数据存储(依赖HDFS)
- Scala编程语言: 多范式的编程语言(支持多种方式编程1. 面向对象 2. 函数式编程)
- Spark Core: 内核,相当于MapReduce, 最重要的概念RDD(弹性分布式数据集)
- Spark SQL: 类似Hive, 支持SQL
- Spark Streaming: 处理流式计算的模块,类似Storm






















 3005
3005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









