






一、整体架构
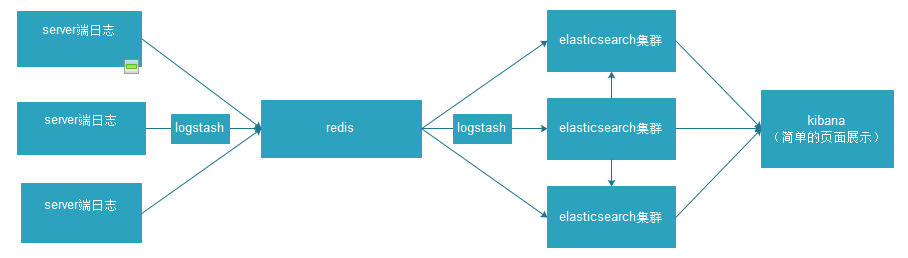
二、整体概述:
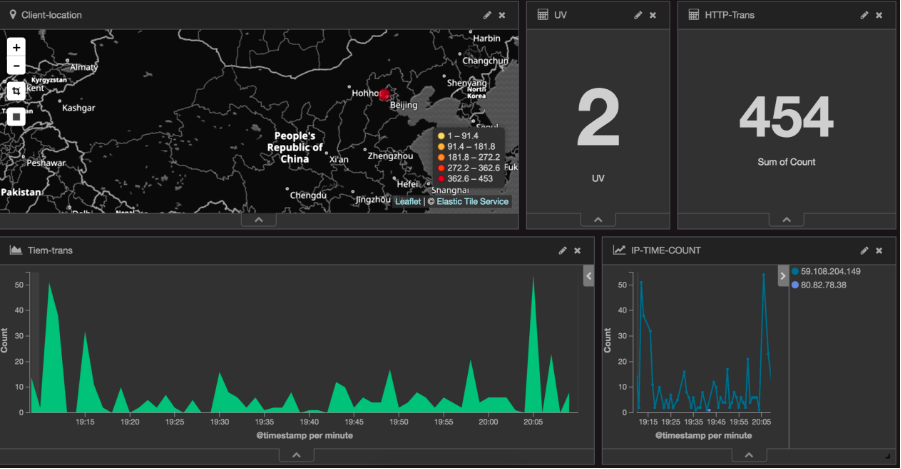
从上图可以看出,日志首先被收集到redis当中,进行缓冲,再通过logstash收集到elasticsearch集群进行索引创建,根据需求进行维度上的组合,最后kibana实现elasticsearch的restful风格接口,将传回的数据进行图形化展示,形成多种图表,放到DashBoard上面进行展示,如下图:
三、集群搭建
开始前,首先要考虑到版本的兼容性,很多版本与版本之间不能进行组合,而且稳定性和实用性也要考虑在内,所以我在这个架构中选择了elasticsearch-2.0.0.tar、logstash-2.0.0.tar、kibana-4.2.1-linux-x64.tar,以下为具体下载地址: https://www.elastic.co/products(里面介绍很详细,而且网站风格简洁明了)
1.在这里我采用的是三个节点,具体分配如下图:

node3节点主要作用是搭建elsticsearch集群,让效率更加高效,提供更多的空间资源;node2显得尤为重要,一方面要去node1节点中的redis拉去数据,还要与node3组合成elasticsearch集群,最后还要配置kibana进行页面展示,所以node2节点性能需要选一个较优的机器;node1节点负责收集日志信息,并通过logstash导入redis中。
将下载好的压缩包放到具体的节点,并解压,这个无需多说,重点在于配置信息。
2.配置详解:
①.logstash主要用来收集日志,功能很强大,里面有很多plugin,主要分为三部分(当然还有codec),一部分是input、filter、output,input和output定义输入和输出的位置,基本上可以满足绝大部分需求。filter是logstash强大的主要原因之一,可以进行日志匹配进行过滤,这一步可以看做是数据清洗。分析你想得到的日志,剔除不符合要求的数据,还可以进行日志截取,条件判断等等操作
进入到解压后的logstash的bin目录,运行 ./plugin list 命令可以看到目前能安装的插件,选择你能用到的插件,通过 ./plugin install 插件名 来安装插件即可,配置文件需要手动创建,名字自己定义即可,下面是具体的配置信息,node1的logstash配置文件如图所示:

node2的logstash配置文件如图所示:

配置文件根据具体的情况具体分析,选择合适的input、output、filter、codec,如果感兴趣可以从这个网站进行学习:https://www.elastic.co/guide/index.html,里面有ELK的讲解。
bin/logstash -f logstash.conf 启动logstash
logstash.conf是前面提到的自定义的配置文件
②elasticsearch主要将日志进行索引,方便查询,查询速度上要比solr快很多,所以很多企业都选用elasticsearch作为搜索引擎,不管是elasticsearch还是solr底层都是Lucene。
首先将elasticsearch进行解压,并进入config目录,修改elasticsearch.yml文件,具体如下图所示:
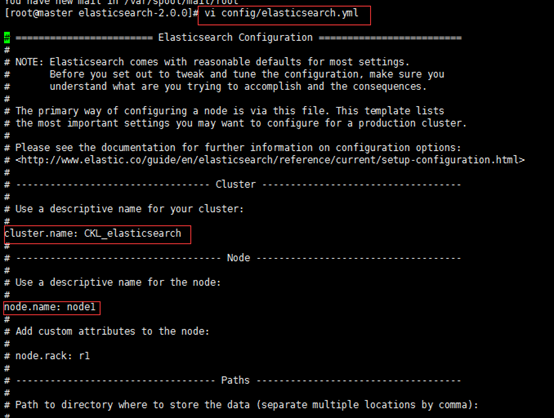
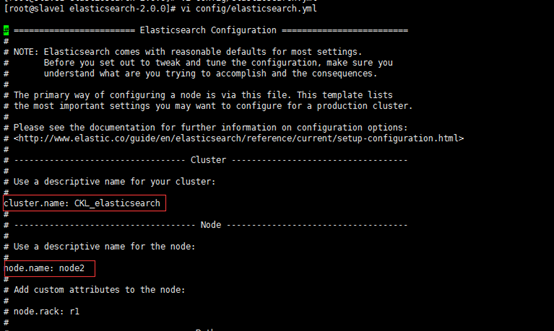
如果要配置集群需要两个节点上的elasticsearch配置的cluster.name相同,都启动可以自动组成集群,这里如果不改cluster.name则默认是cluster.name=elasticsearch,nodename随意取但是集群内的各节点不能相同,下图为node3节点的elasticsearch配置:
安装marvel插件,用于查看集群的运行状态
执行如下命令:
bin/plugin install license
bin/plugin install marvel-agent
bin/elasticsearch 启动elasticsearch
还有一个问题就是elasticsearch的脑裂问题(乍一听还挺吓人),在这里不多做解释,简单来说就是节点找不到master节点进行分裂重新组合,具体参考以下网址:
http://blog.csdn.net/cnweike/article/details/39083089
启动elasticsearch集群最好不要用root用户,因为elasticsearch有远程执行脚本的功能所以容易中木马病毒,所以最好手动创建另外一个用户,并给其足够的权限。
注:如果创建了用户还是启动不了,采用以下命令(允许root用户启动),不过不建议
./elasticsearch -Des.insecure.allow.root=true
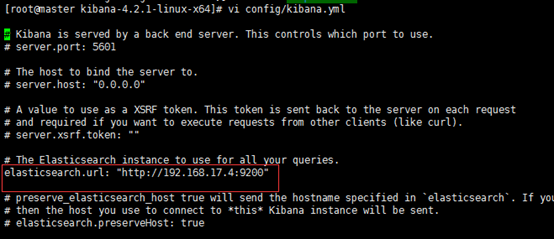
③将kibana压缩文件进行解压,修改config下面的kibana.yml文件,修改elasticsearch.url属性即可,具体如下图所示:
将marvel插件与kibana进行整合,运行以下命令:
bin/kibana plugin --install elasticsearch/marvel/2.0.0
bin/kibana 启动kibana
进入 http://localhost:5601/即可对kibana进行操作,也可以通过marvel查看elasticsearch集群的运行状态,启动logstash即可在kibana中查看到创建logstash-*索引库,根据自身的业务场景选取不同的图形进行展示,提供给大家一个网址进行参考,里面有一些简单的业务分析,选择合适的维度组合最重要,http://www.cnblogs.com/hanyifeng/p/5860731.html
四、总结:
ELK的架构基本可以解决很多日志分析问题,关键在于如何运用,选用适当的logstash-filter可以对数据进行清洗和复杂的数据处理,根据不同的业务场景选取不同的维度组合,通过kibana进行页面展示,kibana的图形展示在处理简单的需求条件上还算可以(可惜的是地图功能不支持了),加上elasticsearch的高性能,基本上可以说是实时的数据处理,如果要是对数据安全性要求较高,而且并发数据较大的情况下,建议选取kafka+storm做实时处理,可以参考的网站:http://shiyanjun.cn/archives/934.html。
虽说ELK也有自身的不足,例如图像库没有high-charts、e-charts丰富(毕竟专长不在于展示,在于日志分析),但是kibana提供的图形足以让你进行简单的业务分析了,而且ELK轻量级,比其他一些复杂的框架比起来还是比较容易上手。如果你的数据量不是太大,业务场景不是太复杂,ELK是个不错的选择!















 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









