






Php爬虫,最简单的小demo
最重要的两点,第一必须在命令行中输入,windows+R,输入cmd,先查看自己的电脑中有没有composer依赖包。
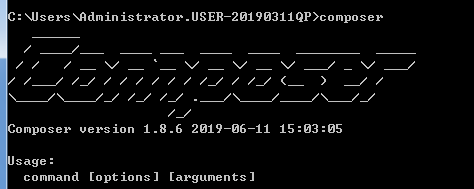
这是安装成功的。
然后安装phpspider,这个是php支持写爬虫的依赖包。
进入到你的项目路径,我这个是放在了tp框架里,可以随意的修改项目路径。
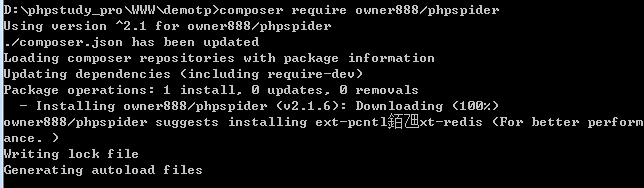
第一种方法:输入:composer require owoner888/phpspider
下载好了:用时大概1小时
第二种办法:去github上下载了这个phpspider包。
百度搜索:https://github.com/owner888/phpspider
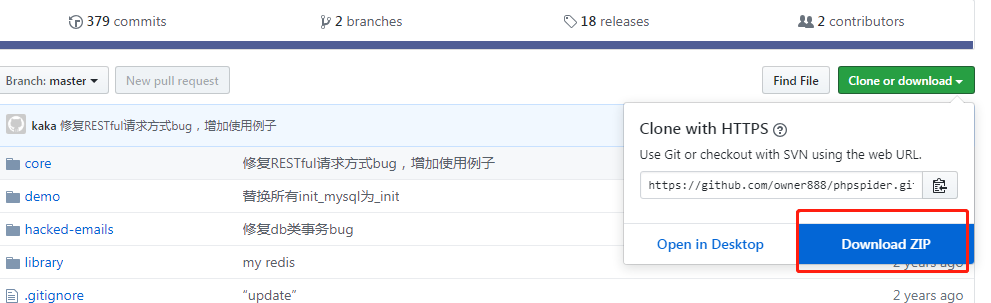
点击下载这个依赖包,可以直接引用。
解压到你的项目路径中,因为我们写的php代码是需要读取这个依赖包。
开始编写代码:
新建一个数据库,和数据表。
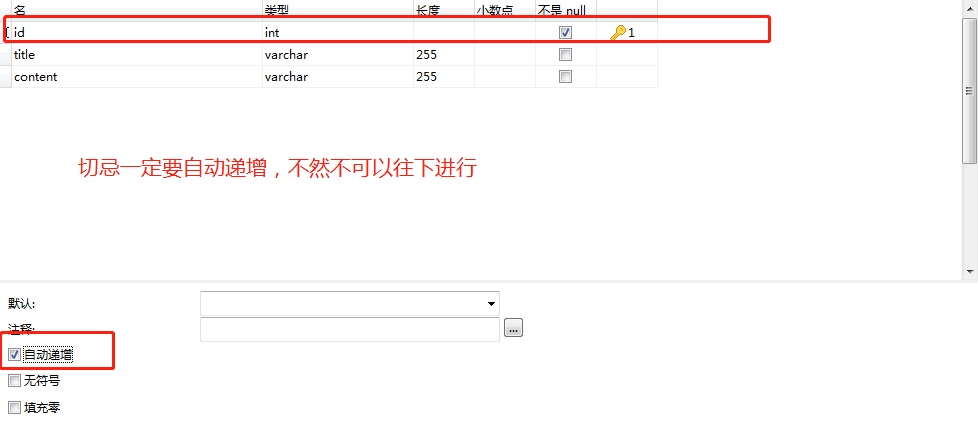
数据表:jianshu
新建一个demo.php(随意命名)。
Php代码:
<?php
require './phpspider-master/autoloader.php';
use phpspider\core\phpspider;
/* Do NOT delete this comment */
/* 不要删除这段注释 */
// 不清楚他这个意思,不知道为啥不能删除
//定义一个数组
$configs = array(
'name' => '简书',
'log_show' => false,
'tasknum' => 1,
// 数据库配置
'db_config' => array(
// 数据url地址
'host' => '127.0.0.1',
// 数据库端口
'port' => 3306,
// 数据库登录账号
'user' => 'root',
// 密码
'pass' => '',
// 数据库名 切记这个是数据库的名字要一致。可以随意更改,但是要和数据库的名字一致
'name' => 'demo'
),
'export' => array(
'type' => 'db',
'table' => 'jianshu' //添加表, jianshu ,
),
// 爬取的页面
'domains' => array(
'jianshu',
'www.jianshu.com'
),
// 抓取的起点
'scan_urls' => array(
'https://www.jianshu.com/c/V2CqjW?utm_medium=index-collections&utm_source=desktop'
),
// 列表页实例
'list_url_regexes' => array(
"https://www.jianshu.com/c/\d+"
),
//内容页实例
'content_url_regexes' => array(
"https://www.jianshu.com/p/\d+"
),
'max_try' => 5,
'fields' => array(
// 表结构,也就是表字段
array(
'name' => 'title',
'selector' => "//h1[@class='title']",
//获取所有class值为title的h1节点
'required' => true
),
array(
'name' => 'content',
//获取所有class值为show-content-free的div节点
'selector' => "//div[@class='show-content-free']",
'required' => true
),
),
);
$spider = new phpspider($configs);
$spider->start();
?>
然后打开cmd:
进入到你的项目目录:输入 php -f demo.php
![]()
爬取成功:
php也算第一次爬取成功了,效仿大佬。哈哈哈,第一次用PHP写爬虫感觉其实也没啥不一样的,基本上都是互通的,学好一个基本都会了,好好学习















 1183
1183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









