







目录
1.3JanusGraph 与 Apache Cassandra 的优势
JanusGraph 和 Gremlin-Python 入门
1.介绍
1.1 JanusGraph 的好处
JanusGraph 旨在支持处理如此大的图,以至于它们需要超出单台机器所能提供的存储和计算能力。为实时遍历和分析查询扩展图数据处理是 JanusGraph 的基本优势。本节将讨论 JanusGraph 及其底层支持的持久性解决方案的各种具体优势。
1.2JanusGraph 的一般优势
- 支持非常大的图形。JanusGraph 图形随集群中的机器数量而变化。
- 支持非常多的并发事务和操作图处理。JanusGraph 的事务容量随着集群中机器的数量而扩展,并在几毫秒内回答大型图上的复杂遍历查询。
- 通过 Hadoop 框架支持全局图分析和批处理图。
- 支持在非常大的图形上对顶点和边进行地理、数字范围和全文搜索。
- 对Apache TinkerPop公开的流行属性图数据模型的本机支持 。
- 对图遍历语言Gremlin 的本机支持 。
- 许多图形级配置提供了用于调整性能的旋钮。
- 以顶点为中心的索引提供顶点级查询以缓解臭名昭著的超级节点问题。
- 提供优化的磁盘表示,以允许有效使用存储和访问速度。
- 在自由的Apache 2 许可下开源。
1.3JanusGraph 与 Apache Cassandra 的优势
- 持续可用 ,无单点故障。
-
由于没有主/从架构,因此图没有读/写瓶颈。
-
弹性可扩展性允许引入和移除机器。
- 缓存层确保持续访问的数据在内存中可用。
- 通过向集群添加更多机器来增加缓存的大小。
- 与Apache Hadoop 的集成。
- 在自由的 Apache 2 许可下开源。
1.4JanusGraph 与 HBase 的好处

- 与Apache Hadoop生态系统紧密集成。
- 本机支持强一致性。
- 添加更多机器后的线性可扩展性。
- 严格一致的读取和写入。
- 使用 HBase 表支持 Hadoop MapReduce作业的便捷基类 。
- 支持通过JMX导出指标 。
- 在自由的 Apache 2 许可下开源。
1.5JanusGraph 和 CAP 定理
尽管您尽了最大努力,您的系统仍会遇到足够多的故障,以至于它必须在减少产量(即停止响应请求)和减少收获(即根据不完整数据给出答案)之间做出选择。这个决定应该基于业务需求。
- 尾声黑尔
使用数据库时,要充分考虑CAP定理(C=Consistency,A=Availability,P=Partitionability)。JanusGraph 分布有 3 个支持后端:Apache Cassandra、 Apache HBase和Oracle Berkeley DB Java 版。请注意,BerkeleyDB JE 是一个非分布式数据库,通常仅与 JanusGraph 一起用于测试和探索目的。
HBase 以牺牲收益为代价优先考虑一致性,即完成请求的概率。Cassandra 以牺牲收获为代价优先考虑可用性,即查询答案的完整性(可用数据/完整数据)。
2.入门
2.1安装
在 Docker 容器中运行 JanusGraph
为了虚拟化和轻松访问,JanusGraph 提供了一个Docker 镜像。Docker 可以更轻松地在一台机器上运行服务器和客户端,而无需处理多个安装。有关安装和使用 Docker 的说明,请参阅docker 指南。让我们尝试在 Docker 中运行一个简单的 JanusGraph 实例:
$ docker run -it -p 8182:8182 janusgraph/janusgraph
我们以交互方式运行映像并请求 Docker 使容器的端口8182可供我们查看。服务器可能需要几秒钟才能启动,因此请耐心等待相应的日志消息出现。
示例日志
我们现在可以在本地设备上启动 Gremlin 控制台并尝试连接到新服务器:
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
gremlin> :remote connect tinkerpop.server conf/remote.yaml
==>Configured localhost/127.0.0.1:8182
请注意,在没有 Docker 的情况下在本地运行客户端和服务器时,客户端的工作方式与之前完全相同。
方便的是,还可以在单独的 Docker 容器中同时运行服务器和客户端。因此,我们为服务器实例化一个容器:
$ docker run --name janusgraph-default janusgraph/janusgraph:latest
我们现在可以指示 Docker 为客户端启动第二个容器并将其链接到已经运行的服务器。
$ docker run --rm --link janusgraph-default:janusgraph -e GREMLIN_REMOTE_HOSTS=janusgraph \
-it janusgraph/janusgraph:latest ./bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
gremlin> :remote connect tinkerpop.server conf/remote.yaml
==>Configured janusgraph/172.17.0.2:8182
请注意无需绑定任何端口即可使此示例正常工作。如需进一步阅读,请参阅JanusGraph 服务器部分以及JanusGraph Docker 文档。
本地安装
为了运行 JanusGraph,需要 Java 8 SE。确保$JAVA_HOME环境变量指向安装 JRE 或 JDK 的正确位置。JanusGraph 可以从项目存储库的Releases部分下载为 .zip 存档。
$ unzip janusgraph-0.6.0.zip
Archive: janusgraph-0.6.0.zip
creating: janusgraph-0.6.0/
...
解压缩下载的存档后,您就可以开始使用了。
运行 Gremlin 控制台
Gremlin 控制台是一个交互式外壳,可让您访问由 JanusGraph 管理的数据。您可以通过运行gremlin.sh位于项目bin目录中的脚本来访问它。
$ cd janusgraph-0.6.0
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
09:12:24 INFO org.apache.tinkerpop.gremlin.hadoop.structure.HadoopGraph - HADOOP_GREMLIN_LIBS is set to: /usr/local/janusgraph/lib
plugin activated: tinkerpop.hadoop
plugin activated: janusgraph.imports
gremlin>
Gremlin 控制台使用Apache Groovy解释命令,它是 Java 的超集。Gremlin-Groovy 通过提供一组用于基本和高级图遍历功能的方法来扩展 Groovy。要更深入地了解 Gremlin 语言的功能,请参阅我们对 Gremlin的介绍。
运行 JanusGraph 服务器
在大多数实际用例中,对数据库的查询不会从存储数据的完全相同的服务器运行。相反,会有某种客户端-服务器层次结构,其中服务器运行数据库并处理请求,而多个客户端创建这些请求,从而相互独立地在数据库中读取和写入条目。使用 JanusGraph 也可以实现这种行为。
为了在本地机器上启动服务器,只需运行janusgraph-server.sh脚本而不是gremlin.sh脚本。您可以选择将配置文件作为参数传递。默认配置位于conf/gremlin-server/gremlin-server.yaml。
$ ./bin/janusgraph-server.sh start
或者
$ ./bin/janusgraph-server.sh console ./conf/gremlin-server/gremlin-server-[...].yaml
信息
默认配置 ( gremlin-server.yaml) 使用它自己的内存后端而不是专用的数据库服务器。默认情况下不使用搜索后端,因此不支持混合索引,因为未指定搜索后端(如果您遵循基本用法示例,请确保您使用的是GraphOfTheGodsFactory.loadWithoutMixedIndex(graph, true)而不是)。有关存储后端的更多信息,请访问文档的相应部分。GraphOfTheGodsFactory.load(graph)
Gremlin 服务器现在正在您的本地机器上运行并等待客户端连接到默认端口8182。要实例化一个客户端——就像之前所做的那样——运行gremlin.sh脚本。同样,将显示本地 Gremlin 控制台。这一次,我们不是在本地使用它,而是将 Gremlin 控制台连接到远程服务器,并将它的所有查询重定向到该服务器。这是通过使用以下:remote命令完成的:
gremlin> :remote connect tinkerpop.server conf/remote.yaml
==>Configured localhost/127.0.0.1:8182
正如您可能从日志中看出的那样,在这种情况下,客户端和服务器在同一台机器上运行。当使用不同的设置时,您所要做的就是修改conf/remote.yaml文件中的参数。
警告
上面的命令只建立到服务器的连接。默认情况下它不会将以下命令转发到服务器!因此,除非前面有 ,否则其他命令仍将在本地执行:>。
要将每个命令转发到远程服务器,请使用该:remote console命令。更多文档可以在TinkerPop 参考文档中找到
使用预打包分发
笔记
从 0.5.1 开始,这需要下载janusgraph-full-0.6.0.zip而不是默认的janusgraph-0.6.0.zip.
JanusGraph 版本预配置为开箱即用地运行 JanusGraph Server,利用示例 Cassandra 和 Elasticsearch 配置允许用户快速开始使用 JanusGraph Server。此配置默认为客户端应用程序,可以使用自定义子协议通过 WebSocket 连接到 JanusGraph 服务器。有许多用不同语言开发的客户端来帮助支持子协议。使用 WebSocket 接口最熟悉的客户端是 Gremlin 控制台。快速入门包并不打算代表生产安装,但确实提供了一种使用 JanusGraph Server 执行开发、运行测试并查看组件如何连接在一起的方法。要使用此默认配置:
-
janusgraph-full-$VERSION.zip从“发布”页面下载当前文件的副本 -
解压并进入
janusgraph--full-$VERSION目录 -
运行
bin/janusgraph.sh start。这一步将启动 Gremlin Server,并将 Cassandra/ES 分叉到一个单独的进程中。出于安全原因请注意 Elasticsearch,因此janusgraph.sh必须在非 root 帐户下运行。
$ bin/janusgraph.sh start
Forking Cassandra...
Running `nodetool statusthrift`.. OK (returned exit status 0 and printed string "running").
Forking Elasticsearch...
Connecting to Elasticsearch (127.0.0.1:9300)... OK (connected to 127.0.0.1:9300).
Forking Gremlin-Server...
Connecting to Gremlin-Server (127.0.0.1:8182)... OK (connected to 127.0.0.1:8182).
Run gremlin.sh to connect.
预打包分发后的清理
如果您想重新开始并删除数据库和日志,您可以使用带有janusgraph.sh. 在运行清理操作之前应该停止服务器。
$ cd /Path/to/janusgraph/janusgraph-{project.version}/
$ ./bin/janusgraph.sh stop
Killing Gremlin-Server (pid 91505)...
Killing Elasticsearch (pid 91402)...
Killing Cassandra (pid 91219)...
$ ./bin/janusgraph.sh clean
Are you sure you want to delete all stored data and logs? [y/N] y
Deleted data in /Path/to/janusgraph/janusgraph-{project.version}/db
Deleted logs in /Path/to/janusgraph/janusgraph-{project.version}/log2.2基本用法
本节非常简短地介绍了 Gremlin 的功能集。要详细了解该主题,请参阅Gremlin 查询语言。
本节中的示例广泛使用了与 JanusGraph 一起分发的玩具图,称为The Graph of the Gods。该图如下图所示。抽象数据模型被称为 属性图模型 ,这个特定的实例描述了罗马万神殿的众生和地点之间的关系。此外,图表中的特殊文本和符号修饰符(例如粗体、下划线等)表示图表中的不同原理图/类型。

| 视觉符号 | 意义 |
|---|---|
| 加粗键 | 图形索引键 |
| 带星号的粗体键 | 必须具有唯一值的图形索引键 |
| 下划线键 | 以顶点为中心的索引键 |
| 空头边缘 | 功能性/独特的优势(无重复) |
| 尾交叉边缘 | 单向边(只能在一个方向上遍历) |
将众神图加载到 JanusGraph 中
下面的示例将打开一个 JanusGraph 图形实例并加载上图所示的 Gods数据集的图形。JanusGraphFactory 提供了一组静态open方法,每个方法都以一个配置作为参数并返回一个图实例。本教程演示了使用GraphOfTheGodsFactory具有不同配置的帮助器类加载The Graph of the Gods。本节跳过配置详细信息,但有关存储后端、索引后端及其配置的其他信息可在存储后端、索引后端和 配置参考中找到。
使用索引后端加载
下面的示例open在使用BerkeleyDB存储后端和 Elasticsearch索引后端的配置上调用这些方法之一:
gremlin> graph = JanusGraphFactory.open('conf/janusgraph-berkeleyje-es.properties')
==>standardjanusgraph[berkeleyje:../db/berkeley]
gremlin> GraphOfTheGodsFactory.load(graph)
==>null
gremlin> g = graph.traversal()
==>graphtraversalsource[standardjanusgraph[berkeleyje:../db/berkeley], standard]
这些JanusGraphFactory.open() and GraphOfTheGodsFactory.load()方法在返回之前对新构造的图执行以下操作:
- 在图形上创建全局索引和以顶点为中心的索引的集合。
- 将所有顶点及其属性添加到图中。
- 将所有边及其属性添加到图中。
有关详细信息,请参阅GraphOfTheGodsFactory 源代码。
对于那些使用 JanusGraph/Cassandra(或 JanusGraph/HBase)的人,一定要使用conf/janusgraph-cql-es.properties(或 conf/janusgraph-hbase-es.properties) 和 GraphOfTheGodsFactory.load().
gremlin> graph = JanusGraphFactory.open('conf/janusgraph-cql-es.properties')
==>standardjanusgraph[cql:[127.0.0.1]]
gremlin> GraphOfTheGodsFactory.load(graph)
==>null
gremlin> g = graph.traversal()
==>graphtraversalsource[standardjanusgraph[cql:[127.0.0.1]], standard]
在没有索引后端的情况下加载
您也可以使用conf/janusgraph-cql.properties, conf/janusgraph-berkeleyje.properties,conf/janusgraph-hbase.properties,或conf/janusgraph-inmemory.properties配置文件来打开图形没有配置的索引后端。在这种情况下,您将需要使用该GraphOfTheGodsFactory.loadWithoutMixedIndex()方法加载众神图,以便它不会尝试使用索引后端。
gremlin> graph = JanusGraphFactory.open('conf/janusgraph-cql.properties')
==>standardjanusgraph[cql:[127.0.0.1]]
gremlin> GraphOfTheGodsFactory.loadWithoutMixedIndex(graph, true)
==>null
gremlin> g = graph.traversal()
==>graphtraversalsource[standardjanusgraph[cql:[127.0.0.1]], standard]
信息
使用任何配置文件,但conf/janusgraph-inmemory.properties 要求您配置并运行专用后端。如果您只想快速打开一个图实例并探索一些 JanusGraph 功能,您可以简单地选择conf/janusgraph-inmemory.properties打开一个 内存后端。
全局图形索引
访问图形数据库中数据的典型模式是首先使用图形索引定位图形的入口点。该入口点是一个元素(或一组元素)——即一个顶点或边。从入口元素开始,Gremlin 路径描述描述了如何通过显式图结构遍历图中的其他元素。
鉴于name属性上有一个唯一索引,可以检索土星顶点。然后可以检查属性映射(即土星的键/值对)。如图所示,土星顶点有一个name“土星”、一个age10000 和一个type“泰坦”。可以通过遍历来检索 Saturn 的孙子:“谁是 Saturn 的孙子?” (“父亲”的反义词是“孩子”)。结果是赫拉克勒斯。
gremlin> saturn = g.V().has('name', 'saturn').next()
==>v[256]
gremlin> g.V(saturn).valueMap()
==>[name:[saturn], age:[10000]]
gremlin> g.V(saturn).in('father').in('father').values('name')
==>hercules
该属性place也在图形索引中。该属性place是边缘属性。因此,JanusGraph 可以索引图索引中的边。可以查询The Graph of the Gods了解雅典50 公里范围内发生的所有事件 (纬度:37.97,经度:23.72)。然后,根据这些信息,哪些顶点参与了这些事件。
gremlin> g.E().has('place', geoWithin(Geoshape.circle(37.97, 23.72, 50)))
==>e[a9x-co8-9hx-39s][16424-battled->4240]
==>e[9vp-co8-9hx-9ns][16424-battled->12520]
gremlin> g.E().has('place', geoWithin(Geoshape.circle(37.97, 23.72, 50))).as('source').inV().as('god2').select('source').outV().as('god1').select('god1', 'god2').by('name')
==>[god1:hercules, god2:hydra]
==>[god1:hercules, god2:nemean]
g.V)或所有边()。JanusGraph 中索引的第二个方面被称为以顶点为中心的索引。以顶点为中心的索引用于加速图内部的遍历。稍后描述以顶点为中心的索引。
g.E
has
interval
图遍历示例
赫拉克勒斯,朱庇特和阿尔克墨涅的儿子 ,拥有超人的力量。赫拉克勒斯是半 神,因为他的父亲是神,他的母亲是人。 朱庇特的妻子朱诺对朱庇特的不忠感到愤怒。作为报复,她用暂时的精神错乱使赫拉克勒斯失明,并让他杀死了他的妻子和孩子。为了赎罪,德尔斐神谕命令赫拉克勒斯 为欧律斯透斯服务。欧律斯透斯任命赫拉克勒斯进行 12 次劳动。
在上一节中,证明了土星的孙子是大力士。这可以用 表示loop。本质上,赫拉克勒斯是沿in('father') 路径距离土星 2 步的顶点。
gremlin> hercules = g.V(saturn).repeat(__.in('father')).times(2).next()
==>v[1536]
赫拉克勒斯是半神。为了证明赫拉克勒斯是半人半神,必须检查他父母的出身。可以从赫拉克勒斯顶点穿越到他的母亲和父亲。最后,可以确定type它们中的每一个——产生“上帝”和“人类”。
gremlin> g.V(hercules).out('father', 'mother')
==>v[1024]
==>v[1792]
gremlin> g.V(hercules).out('father', 'mother').values('name')
==>jupiter
==>alcmene
gremlin> g.V(hercules).out('father', 'mother').label()
==>god
==>human
gremlin> hercules.label()
==>demigod
迄今为止的例子都是关于罗马万神殿中不同角色的遗传谱系。该物业图模型 是表现足以代表多种类型的事物和关系。就这样,《众神图》也鉴定了赫拉克勒斯的各种英雄功绩——他著名的十二功。在上一节中,人们发现赫拉克勒斯参与了雅典附近的两场战斗。可以通过遍历battledHercules 顶点之外的边来探索这些事件。
gremlin> g.V(hercules).out('battled')
==>v[2304]
==>v[2560]
==>v[2816]
gremlin> g.V(hercules).out('battled').valueMap()
==>[name:[nemean]]
==>[name:[hydra]]
==>[name:[cerberus]]
gremlin> g.V(hercules).outE('battled').has('time', gt(1)).inV().values('name')
==>cerberus
==>hydra
边缘属性time上battled边缘通过一个顶点的顶点为中心的索引编入索引。battled根据约束/过滤器检索与 Hercules 相关的边缘time比对所有边缘进行线性扫描和过滤(通常为O(log n),其中n是入射边缘的数量)更快。JanusGraph 足够智能,可以在可用时使用以顶点为中心的索引。toString()Gremlin 表达式的A显示分解为各个步骤。
gremlin> g.V(hercules).outE('battled').has('time', gt(1)).inV().values('name').toString()
==>[GraphStep([v[24744]],vertex), VertexStep(OUT,[battled],edge), HasStep([time.gt(1)]), EdgeVertexStep(IN), PropertiesStep([name],value)]
更复杂的图遍历示例
在 Tartarus 的深处住着冥王星。由于赫拉克勒斯与他的宠物塞伯鲁斯战斗,他与赫拉克勒斯的关系变得紧张。然而,赫拉克勒斯是他的侄子——他该如何让赫拉克勒斯为他的傲慢付出代价?
下面的 Gremlin 遍历提供了更多关于The Graph of the Gods 的例子。每次遍历的解释在前一行中作为//注释提供。
塔尔塔罗斯的同居者
gremlin> pluto = g.V().has('name', 'pluto').next()
==>v[2048]
gremlin> // who are pluto's cohabitants?
gremlin> g.V(pluto).out('lives').in('lives').values('name')
==>pluto
==>cerberus
gremlin> // pluto can't be his own cohabitant
gremlin> g.V(pluto).out('lives').in('lives').where(is(neq(pluto))).values('name')
==>cerberus
gremlin> g.V(pluto).as('x').out('lives').in('lives').where(neq('x')).values('name')
==>cerberus
冥王星的兄弟
gremlin> // where do pluto's brothers live?
gremlin> g.V(pluto).out('brother').out('lives').values('name')
==>sky
==>sea
gremlin> // which brother lives in which place?
gremlin> g.V(pluto).out('brother').as('god').out('lives').as('place').select('god', 'place')
==>[god:v[1024], place:v[512]]
==>[god:v[1280], place:v[768]]
gremlin> // what is the name of the brother and the name of the place?
gremlin> g.V(pluto).out('brother').as('god').out('lives').as('place').select('god', 'place').by('name')
==>[god:jupiter, place:sky]
==>[god:neptune, place:sea]
最后,冥王星住在塔尔塔罗斯,因为他对死亡毫不关心。另一方面,他的兄弟们根据他们对这些地点的某些品质的热爱来选择他们的地点。!
gremlin> g.V(pluto).outE('lives').values('reason')
==>no fear of death
gremlin> g.E().has('reason', textContains('loves'))
==>e[6xs-sg-m51-e8][1024-lives->512]
==>e[70g-zk-m51-lc][1280-lives->768]
gremlin> g.E().has('reason', textContains('loves')).as('source').values('reason').as('reason').select('source').outV().values('name').as('god').select('source').inV().values('name').as('thing').select('god', 'reason', 'thing')
==>[god:neptune, reason:loves waves, thing:sea]
==>[god:jupiter, reason:loves fresh breezes, thing:sky]2.3Gremlin 查询语言
Gremlin是 JanusGraph 的查询语言,用于从图中检索数据和修改数据。Gremlin 是一种面向路径的语言,它简洁地表达了复杂的图遍历和变异操作。Gremlin 是一种函数式语言,其中遍历运算符链接在一起以形成类似路径的表达式。例如,“从 Hercules,遍历到他的父亲,然后是他父亲的父亲,然后返回祖父的名字。”
Gremlin 是Apache TinkerPop 的一个组件。它是独立于 JanusGraph 开发的,被大多数图数据库支持。通过使用 Gremlin 查询语言在 JanusGraph 之上构建应用程序,用户可以避免供应商锁定,因为他们的应用程序可以迁移到其他支持 Gremlin 的图形数据库。
本节是 Gremlin 查询语言的简要概述。有关 Gremlin 的更多信息,请参阅以下资源:
-
Practical Gremlin:Kelvin R. Lawrence 的在线书籍,深入概述了 Gremlin 及其与 JanusGraph 的交互。
-
完整的 Gremlin 手册:所有 Gremlin 步骤的参考手册。
-
Gremlin 控制台教程:了解如何有效地使用 Gremlin 控制台以交互方式遍历和分析图形。
-
Gremlin Recipes:Gremlin最佳实践和常见遍历模式的集合。
-
Gremlin 语言驱动程序:连接到具有不同编程语言的 Gremlin 服务器,包括 Go、JavaScript、.NET/C#、PHP、Python、Ruby、Scala 和 TypeScript。
-
Gremlin 语言变体:了解如何将 Gremlin 嵌入到宿主编程语言中。
-
面向 SQL 开发人员的Gremlin:使用使用 SQL 查询数据时发现的典型模式来学习 Gremlin。
除了这些资源之外,连接到 JanusGraph 还解释了如何在不同的编程语言中使用 Gremlin 来查询 JanusGraph 服务器。
介绍性遍历
Gremlin 查询是从左到右计算的一系列操作/函数。下面提供了对入门中讨论的 Gods数据集图形的简单祖父查询。
gremlin> g.V().has('name', 'hercules').out('father').out('father').values('name')
==>saturn
上面的查询可以阅读:
g: 用于当前图遍历。V: 对于图中的所有顶点has('name', 'hercules'):将顶点过滤为具有名称属性“hercules”的顶点(只有一个)。out('father'): 从 Hercules 遍历传出的父亲边缘。- 'out('father')`:从 Hercules 的父亲的顶点(即木星)遍历出父亲边缘。
name: 获取“hercules”顶点祖父的 name 属性。
综合起来,这些步骤形成了一个类似路径的遍历查询。每个步骤都可以分解并展示其结果。这种构建遍历/查询的风格在构建更大、更复杂的查询链时很有用。
gremlin> g
==>graphtraversalsource[janusgraph[cql:127.0.0.1], standard]
gremlin> g.V().has('name', 'hercules')
==>v[24]
gremlin> g.V().has('name', 'hercules').out('father')
==>v[16]
gremlin> g.V().has('name', 'hercules').out('father').out('father')
==>v[20]
gremlin> g.V().has('name', 'hercules').out('father').out('father').values('name')
==>saturn
对于健全性检查,通常最好查看每个返回的属性,而不是分配的长 ID。
gremlin> g.V().has('name', 'hercules').values('name')
==>hercules
gremlin> g.V().has('name', 'hercules').out('father').values('name')
==>jupiter
gremlin> g.V().has('name', 'hercules').out('father').out('father').values('name')
==>saturn
请注意显示 Hercules 的整个父系树分支的相关遍历。提供这种更复杂的遍历是为了展示语言的灵活性和表达能力。熟练掌握 Gremlin 可为 JanusGraph 用户提供流畅导航底层图形结构的能力。
gremlin> g.V().has('name', 'hercules').repeat(out('father')).emit().values('name')
==>jupiter
==>saturn
下面提供了一些更多的遍历示例。
gremlin> hercules = g.V().has('name', 'hercules').next()
==>v[1536]
gremlin> g.V(hercules).out('father', 'mother').label()
==>god
==>human
gremlin> g.V(hercules).out('battled').label()
==>monster
==>monster
==>monster
gremlin> g.V(hercules).out('battled').valueMap()
==>{name=nemean}
==>{name=hydra}
==>{name=cerberus}
鉴于The Graph of the Gods只有一个战士 (Hercules),另一位战士(例如)被添加到图中,Gremlin 展示了如何将顶点和边添加到图中。
gremlin> theseus = graph.addVertex('human')
==>v[3328]
gremlin> theseus.property('name', 'theseus')
==>null
gremlin> cerberus = g.V().has('name', 'cerberus').next()
==>v[2816]
gremlin> battle = theseus.addEdge('battled', cerberus, 'time', 22)
==>e[7eo-2kg-iz9-268][3328-battled->2816]
gremlin> battle.values('time')
==>22
添加顶点时,可以提供可选的顶点标签。添加边时必须指定边标签。可以在顶点和边上设置作为键值对的属性。当使用 SET 或 LIST 基数定义属性键addProperty时,必须在将相应属性添加到顶点时使用。
gremlin> g.V(hercules).as('h').out('battled').in('battled').where(neq('h')).values('name')
==>theseus
上面的例子有 4 个链式函数:out、in、except、 和 values(即name的简写values('name'))。下面逐项列出每个函数签名,其中V是顶点,U是任何对象,其中V是 的子集U。
out: V -> Vin: V -> Vexcept: U -> Uvalues: V -> U
将函数链接在一起时,传入类型必须匹配传出类型,其中U匹配任何内容。因此,上面的“co-batted/ally”遍历是正确的。
笔记
本节中介绍的 Gremlin 概述侧重于 Gremlin 控制台中使用的 Gremlin-Groovy 语言实现。有关使用 Groovy 以外的其他语言和独立于 Gremlin 控制台连接到 JanusGraph的信息,请参阅连接到 JanusGraph。
迭代遍历
Gremlin 控制台的一项便利功能是它会自动迭代从 gremlin> 提示符执行的查询的所有结果。这在REPL环境中运行良好,因为它将结果显示为字符串。当您过渡到编写 Gremlin 应用程序时,了解如何显式迭代遍历很重要,因为应用程序的遍历不会自动迭代。这些是迭代Traversal 的一些常用方法:
iterate()- 预期结果为零或可以忽略。next()- 得到一个结果。请务必先检查hasNext()。next(int n)- 获取下一个n结果。请务必先检查hasNext()。toList()- 以列表形式获取所有结果。如果没有结果,则返回一个空列表。
下面显示了一个 Java 代码示例来演示这些概念:
Traversal t = g.V().has("name", "pluto"); // Define a traversal
// Note the traversal is not executed/iterated yet
Vertex pluto = null;
if (t.hasNext()) { // Check if results are available
pluto = g.V().has("name", "pluto").next(); // Get one result
g.V(pluto).drop().iterate(); // Execute a traversal to drop pluto from graph
}
// Note the traversal can be cloned for reuse
Traversal tt = t.asAdmin().clone();
if (tt.hasNext()) {
System.err.println("pluto was not dropped!");
}
List<Vertex> gods = g.V().hasLabel("god").toList(); // Find all the gods2.4架构概览
JanusGraph 是一个图形数据库引擎。JanusGraph 本身专注于紧凑的图序列化、丰富的图数据建模和高效的查询执行。此外,JanusGraph 利用 Hadoop 进行图形分析和批量图形处理。JanusGraph 为数据持久性、数据索引和客户端访问实现了强大的模块化接口。JanusGraph 的模块化架构使其能够与广泛的存储、索引和客户端技术进行互操作;它还简化了扩展 JanusGraph 以支持新的过程。
JanusGraph 和磁盘之间有一个或多个存储和索引适配器。JanusGraph 标配以下适配器,但 JanusGraph 的模块化架构支持第三方适配器。
- 数据存储:
- 索引,可加速并启用更复杂的查询:
- Elasticsearch
- Apache Solr
- Apache Lucene
从广义上讲,应用程序可以通过两种方式与 JanusGraph 交互:
-
将 JanusGraph 嵌入到应用程序中, 直接针对同一 JVM 中的图形执行 Gremlin查询。查询执行、JanusGraph 的缓存和事务处理都发生在与应用程序相同的 JVM 中,而从存储后端检索数据可能是本地的或远程的。
-
通过向服务器提交 Gremlin 查询,与本地或远程 JanusGraph 实例交互。JanusGraph 本身支持Apache TinkerPop堆栈的 Gremlin 服务器组件。
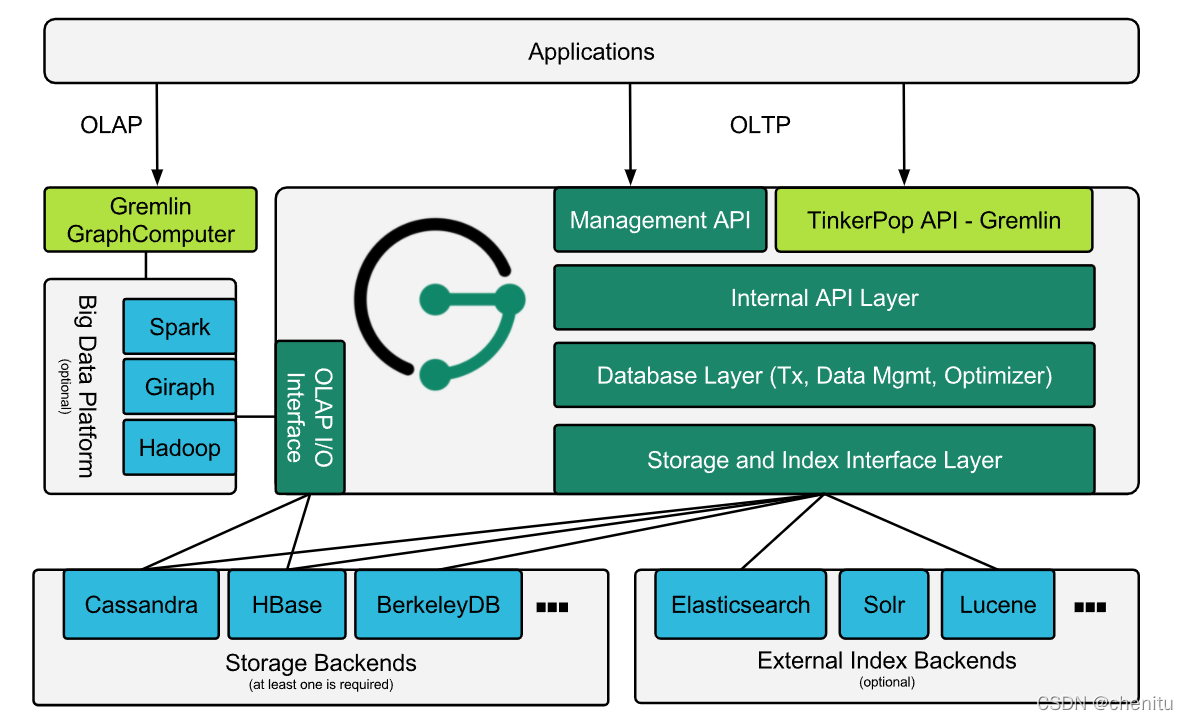
3.与JanusGraph交互
几乎所有与 JanusGraph 的交互都与交易相关联。JanusGraph 事务对于多线程并发使用是安全的。JanusGraph 实例上的方法类似于graph.V(...)并 graph.tx().commit()执行ThreadLocal查找以检索或创建与调用线程关联的事务。ThreadLocal调用者也可以放弃事务管理,转而使用 call graph.tx().createThreadedTx(),后者返回对事务对象的引用,其中包含读/写图形数据和提交或回滚的方法。
JanusGraph 事务不一定是 ACID。它们可以在 BerkeleyDB 上如此配置,但它们在 Cassandra 或 HBase 上通常不是这样,它们的底层存储系统不提供可序列化的隔离或多行原子写入,并且模拟这些属性的成本将是巨大的。
本节描述 JanusGraph 的事务语义和 API。
交互处理
JanusGraph 中的每个图形操作都发生在事务的上下文中。根据 TinkerPop 的事务规范,每个线程通过对图的第一个操作(即检索或变异)针对图数据库打开自己的事务:
graph = JanusGraphFactory.open("berkeleyje:/tmp/janusgraph")
juno = graph.addVertex() //Automatically opens a new transaction
juno.property("name", "juno")
graph.tx().commit() //Commits transaction
在本例中,打开了一个本地 JanusGraph 图数据库。添加顶点“juno”是第一个操作(在此线程中),它会自动打开一个新事务。所有后续操作都发生在同一个事务的上下文中,直到事务显式停止或图形数据库关闭。如果close()调用时事务仍处于打开状态,则未完成事务的行为在技术上是未定义的。在实践中,任何非线程绑定事务通常都会被有效回滚,但属于调用关闭线程的线程绑定事务将首先被提交。请注意,读取和写入操作都发生在事务的上下文中。
交互范围
所有图元素(顶点、边和类型)都与检索或创建它们的事务范围相关联。在 TinkerPop 的默认事务语义下,事务使用图上的第一个操作自动创建,并使用commit()或显式关闭rollback()。一旦事务关闭,与该事务关联的所有图形元素都将变得陈旧且不可用。但是,JanusGraph 会自动将顶点和类型转换到新的事务范围中,如下例所示:
graph = JanusGraphFactory.open("berkeleyje:/tmp/janusgraph")
juno = graph.addVertex() //Automatically opens a new transaction
graph.tx().commit() //Ends transaction
juno.property("name", "juno") //Vertex is automatically transitioned
另一方面,边缘不会自动转换,也不能在原始事务之外访问。它们必须显式转换:
e = juno.addEdge("knows", graph.addVertex())
graph.tx().commit() //Ends transaction
e = g.E(e).next() //Need to refresh edge
e.property("time", 99)
交互失败
提交事务时,JanusGraph 将尝试将所有更改持久保存到存储后端。由于 IO 异常、网络错误、机器崩溃或资源不可用,这可能并不总是成功。因此,事务可能会失败。事实上,交易 最终会在足够大的系统中失败。因此,我们强烈建议您的代码预期并适应此类故障:
try {
if (g.V().has("name", name).iterator().hasNext())
throw new IllegalArgumentException("Username already taken: " + name)
user = graph.addVertex()
user.property("name", name)
graph.tx().commit()
} catch (Exception e) {
//Recover, retry, or return error message
println(e.getMessage())
}
上面的示例演示了一个简化的用户注册实现,其中name是希望注册的用户的名称。首先,检查是否已经存在具有该名称的用户。如果没有,则会创建一个新的用户顶点并分配名称。最后,事务被提交。
如果事务失败,JanusGraphException则抛出 a。事务可能失败的原因有多种。JanusGraph 区分潜在的临时故障和永久故障。
潜在的临时故障是与资源不可用和 IO 故障(例如网络超时)相关的故障。JanusGraph 通过在一些延迟后重试保持事务状态来自动尝试从临时故障中恢复。重试次数和重试延迟是可配置的(参见配置参考)。
永久性故障可能由完全连接丢失、硬件故障或锁争用引起。要了解锁争用的原因,请考虑上面的注册示例,并假设用户尝试使用用户名“juno”进行注册。该用户名可能在事务开始时仍然可用,但在事务提交时,另一个用户可能同时向“juno”注册,并且该事务持有用户名的锁,因此导致另一个事务失败。根据事务语义,可以通过重新运行整个事务从锁争用失败中恢复。
可能导致事务失败的永久性异常包括:
-
PermanentLockingException(本地锁争用):另一个本地线程已被授予冲突锁。
-
PermanentLockingException( Expected value mismatch for X: expected=Y vs actual=Z ): 申请锁后验证此事务中读取的值与数据存储中的值相同失败。换句话说,另一个事务在它被读取和修改后修改了该值。
多线程事务
JanusGraph 通过 TinkerPop 的线程事务支持多线程事务。因此,为了加速事务处理并利用多核架构,多个线程可以在单个事务中同时运行。
使用 TinkerPop 的默认事务处理,每个线程自动针对图形数据库打开自己的事务。要打开与线程无关的事务,请使用createThreadedTx()方法。
threadedGraph = graph.tx().createThreadedTx();
threads = new Thread[10];
for (int i=0; i<threads.length; i++) {
threads[i]=new Thread({
println("Do something with 'threadedGraph''");
});
threads[i].start();
}
for (int i=0; i<threads.length; i++) threads[i].join();
threadedGraph.tx().commit();
该createThreadedTx()方法返回一个Graph代表这个新打开的事务的新对象。图对象tx支持原始图所做的所有方法,但不会为每个线程打开新事务。这允许我们启动多个线程,这些线程都在同一个事务中并发工作,其中一个线程在所有线程完成工作后最终提交事务。
JanusGraph 依靠优化的并发数据结构来支持在单个事务中高效运行的数百个并发线程。
并发算法
createThreadedTx()在实现并发图算法时,启动的线程独立事务特别有用。大多数遍历或消息传递(以自我为中心)的图形算法都是 令人尴尬的并行,这意味着它们可以通过多个线程轻松并行化和执行。这些线程中的每一个都可以对Graph返回的单个对象进行操作 ,createThreadedTx()而不会相互阻塞。
嵌套事务
线程独立事务的另一个用例是嵌套事务,它应该独立于周围的事务。
例如,假设一个长时间运行的事务性作业必须创建一个具有唯一名称的新顶点。由于强制执行唯一名称需要获取锁(有关更多详细信息,请参阅最终一致的存储后端)并且由于事务运行了很长时间,因此可能会出现锁拥塞和代价高昂的事务失败。
v1 = graph.addVertex()
//Do many other things
v2 = graph.addVertex()
v2.property("uniqueName", "foo")
v1.addEdge("related", v2)
//Do many other things
graph.tx().commit() // This long-running tx might fail due to contention on its uniqueName lock
解决此问题的一种方法是在一个简短的嵌套线程独立事务中创建顶点,如以下伪代码所示
v1 = graph.addVertex()
//Do many other things
tx = graph.tx().createThreadedTx()
v2 = tx.addVertex()
v2.property("uniqueName", "foo")
tx.commit() // Any lock contention will be detected here
v1.addEdge("related", g.V(v2).next()) // Need to load v2 into outer transaction
//Do many other things
graph.tx().commit() // Can't fail due to uniqueName write lock contention involving v2
常见事务处理问题
事务在对图形执行的第一个操作时自动启动。不必手动启动事务。该方法newTransaction仅用于启动多线程事务。
事务在 TinkerPop 语义下自动启动,但 不会自动终止。必须使用commit()或手动终止事务rollback()。如果commit()事务失败,应rollback()在捕获失败后手动终止。手动终止交易是必要的,因为只有用户知道交易边界。
事务将尝试从事务开始时保持其状态。这可能会导致多线程应用程序中出现意外行为,如下面的人工示例所示
v = g.V(4).next() // Retrieve vertex, first action automatically starts transaction
g.V(v).bothE()
>> returns nothing, v has no edges
//thread is idle for a few seconds, another thread adds edges to v
g.V(v).bothE()
>> still returns nothing because the transactional state from the beginning is maintained
这种意外行为很可能发生在客户端-服务器应用程序中,其中服务器维护多个线程来响应客户端请求。因此,在一个工作单元(例如代码片段、查询等)之后终止事务很重要。所以,上面的例子应该是:
v = g.V(4).next() // Retrieve vertex, first action automatically starts transaction
g.V(v).bothE()
graph.tx().commit()
//thread is idle for a few seconds, another thread adds edges to v
g.V(v).bothE()
>> returns the newly added edge
graph.tx().commit()
当通过newTransaction在该事务范围内检索或创建的所有顶点和边使用多线程事务时,在该事务 范围之外不可用。在事务关闭后访问这些元素将导致异常。如上例所示,必须在新事务中使用g.V(existingVertex)或显式刷新此类元素 g.E(existingEdge)。
交互配置
JanusGraph的JanusGraph.buildTransaction()方法给出了用户的能力,配置和启动新的多线程事务 反对JanusGraph。因此,它JanusGraph.newTransaction()与附加配置选项相同。
buildTransaction()返回一个TransactionBuilder允许配置交易的以下方面:
-
readOnly()- 使事务只读,任何修改图形的尝试都将导致异常。 -
enableBatchLoading()- 为单个事务启用批量加载。storage.batch-loading由于禁用了一致性检查和其他优化,此设置的效率与图形范围的设置相似。与storage.batch-loading此选项不同, 此选项不会更改存储后端的行为。同样,您可以调用disableBatchLoading()以禁用单个事务的批量加载。 -
propertyPrefetching(boolean)- 启用或禁用属性预取,即query.fast-property针对单个事务。如果启用,特定顶点的所有属性将在第一个顶点属性访问时预取,这消除了对同一顶点的后续属性访问的后端调用。 -
multiQuery(boolean)- 启用或禁用查询批处理,即query.batch针对单个事务。如果启用,则在针对存储后端执行时,将对单个遍历的查询进行批处理。 -
setTimestamp(long)- 将此事务的时间戳设置为与存储后端通信以进行持久化。根据存储后端,此设置可能会被忽略。对于最终一致的后端,这是用于解决写入冲突的时间戳。如果未明确指定此设置,JanusGraph 将使用当前时间。 -
setVertexCacheSize(long size)- 此事务在内存中缓存的顶点数。此数字越大,事务可能消耗的内存就越多。如果这个数字太小,事务可能必须重新获取数据,这会导致延迟,特别是对于长时间运行的事务。 -
checkExternalVertexExistence(boolean)- 此交易是否应验证用户提供的顶点 ID 的顶点是否存在。此类检查需要访问数据库,这需要时间。仅当用户绝对确定顶点必须存在时才应禁用存在检查 - 否则会导致数据损坏。 -
checkInternalVertexExistence(boolean)- 此事务是否应在查询执行期间仔细检查顶点的存在。这对于避免最终一致存储后端上的幻影顶点很有用。默认禁用。启用此设置会减慢查询处理速度。 -
consistencyChecks(boolean)- JanusGraph 是否应该强制执行模式级别的一致性约束(例如多重性约束)。禁用一致性检查会带来更好的性能,但需要用户确保应用程序级别的一致性确认以避免不一致。小心使用!
一旦指定了所需的配置选项,新事务就会开始,通过start()它返回一个 JanusGraphTransaction.
3.2搜索谓词和混合索引数据类型
本页列出了 JanusGraph 在全局图搜索和局部遍历中支持的所有比较谓词。
笔记
本节的某些部分需要混合索引,请参阅混合索引后端。
比较谓词
该Compare枚举指定用于索引查询构造和使用在上面的实施例中的以下比较谓词:
eq(平等的)neq(不等于)gt(比...更棒)gte(大于或等于)lt(少于)lte(小于或等于)
String、numeric、Date 和 Instant 数据类型支持所有比较谓词。Boolean 和 UUID 数据类型支持eq和neq比较谓词。
eq并且neq可以用于布尔值和 UUID。
文本谓词
该Text枚举指定文本搜索用于查询匹配的文本或字符串值。我们区分两种类型的谓词:
- 文本搜索谓词在文本字符串被标记化后与文本字符串中的单个单词匹配。这些谓词不区分大小写。
textContains: 如果(至少)文本字符串中的一个词与查询字符串匹配,则为真textNotContains: 如果文本字符串中没有与查询字符串匹配的词,则为真textContainsPrefix: 如果(至少)文本字符串中的一个单词以查询字符串开头,则为真textNotContainsPrefix: 如果文本字符串中没有以查询字符串开头的单词,则为真textContainsRegex: 如果(至少)文本字符串中的一个词与给定的正则表达式匹配,则为真textNotContainsRegex: 如果文本字符串中没有单词与给定的正则表达式匹配,则为真textContainsFuzzy: 如果(至少)文本字符串中的一个词与查询字符串相似(基于 Levenshtein 编辑距离),则为真textNotContainsFuzzy: 如果文本字符串中没有与查询字符串相似的词,则为真(基于 Levenshtein 编辑距离)textContainsPhrase: 如果文本字符串包含查询字符串中的确切单词序列,则为真textNotContainsPhrase: 如果文本字符串不包含查询字符串中的单词序列,则为真
- 匹配整个字符串值的字符串搜索谓词
textPrefix: 如果字符串值以给定的查询字符串开头textNotPrefix: 如果字符串值不以给定的查询字符串开头textRegex: 如果字符串值完全匹配给定的正则表达式textNotRegex: 如果字符串值不完全匹配给定的正则表达式textFuzzy: 如果字符串值与给定的查询字符串相似(基于 Levenshtein 编辑距离)textNotFuzzy: 如果字符串值与给定的查询字符串不相似(基于 Levenshtein 编辑距离)
有关全文和字符串搜索的更多信息,请参阅文本搜索。
地理谓词
该Geo枚举指定地理位置谓词。
geoIntersect如果两个几何对象至少有一个公共点(与 的相反点),则该结论成立geoDisjoint。geoWithin如果一个几何对象包含另一个几何对象,则为真。geoDisjoint如果两个几何对象没有共同点(与 的相反geoIntersect),则该规则成立。geoContains如果一个几何对象包含在另一个几何对象中,则该规则成立。
有关地理搜索的更多信息,请参阅地理映射。
查询示例
以下查询示例演示了教程图上的一些谓词。
// 1) Find vertices with the name "hercules"
g.V().has("name", "hercules")
// 2) Find all vertices with an age greater than 50
g.V().has("age", gt(50))
// or find all vertices between 1000 (inclusive) and 5000 (exclusive) years of age and order by ascending age
g.V().has("age", inside(1000, 5000)).order().by("age", asc)
// which returns the same result set as the following query but in reverse order
g.V().has("age", inside(1000, 5000)).order().by("age", desc)
// 3) Find all edges where the place is at most 50 kilometers from the given latitude-longitude pair
g.E().has("place", geoWithin(Geoshape.circle(37.97, 23.72, 50)))
// 4) Find all edges where reason contains the word "loves"
g.E().has("reason", textContains("loves"))
// or all edges which contain two words (need to chunk into individual words)
g.E().has("reason", textContains("loves")).has("reason", textContains("breezes"))
// or all edges which contain words that start with "lov"
g.E().has("reason", textContainsPrefix("lov"))
// or all edges which contain words that match the regular expression "br[ez]*s" in their entirety
g.E().has("reason", textContainsRegex("br[ez]*s"))
// or all edges which contain words similar to "love"
g.E().has("reason", textContainsFuzzy("love"))
// 5) Find all vertices older than a thousand years and named "saturn"
g.V().has("age", gt(1000)).has("name", "saturn")
数据类型支持
虽然 JanusGraph 的复合索引支持可以存储在 JanusGraph 中的任何数据类型,但混合索引仅限于以下数据类型。
- 字节
- 短的
- 整数
- Long
- 漂浮
- 双倍的
- 细绳
- 地理形状
- 日期
- 立即的
- 用户名
未来将支持其他数据类型。
Geoshape 数据类型
Geoshape 数据类型支持表示点、圆、框、线、多边形、多点、多线和多多边形。索引后端目前支持索引点、圆、框、线、多边形、多点、多线、多多边形和几何集合。地理空间索引查找仅通过混合索引支持。
要构造 Geoshape,请使用以下方法:
//lat, lng
Geoshape.point(37.97, 23.72)
//lat, lng, radius in km
Geoshape.circle(37.97, 23.72, 50)
//SW lat, SW lng, NE lat, NE lng
Geoshape.box(37.97, 23.72, 38.97, 24.72)
//WKT
Geoshape.fromWkt("POLYGON ((35.4 48.9, 35.6 48.9, 35.6 49.1, 35.4 49.1, 35.4 48.9))")
//MultiPoint
Geoshape.geoshape(Geoshape.getShapeFactory().multiPoint().pointXY(60.0, 60.0).pointXY(120.0, 60.0)
.build())
//MultiLine
Geoshape.geoshape(Geoshape.getShapeFactory().multiLineString()
.add(Geoshape.getShapeFactory().lineString().pointXY(59.0, 60.0).pointXY(61.0, 60.0))
.add(Geoshape.getShapeFactory().lineString().pointXY(119.0, 60.0).pointXY(121.0, 60.0)).build())
//MultiPolygon
Geoshape.geoshape(Geoshape.getShapeFactory().multiPolygon()
.add(Geoshape.getShapeFactory().polygon().pointXY(59.0, 59.0).pointXY(61.0, 59.0)
.pointXY(61.0, 61.0).pointXY(59.0, 61.0).pointXY(59.0, 59.0))
.add(Geoshape.getShapeFactory().polygon().pointXY(119.0, 59.0).pointXY(121.0, 59.0)
.pointXY(121.0, 61.0).pointXY(119.0, 61.0).pointXY(119.0, 59.0)).build())
//GeometryCollection
Geoshape.geoshape(Geoshape.getGeometryCollectionBuilder()
.add(Geoshape.getShapeFactory().pointXY(60.0, 60.0))
.add(Geoshape.getShapeFactory().lineString().pointXY(119.0, 60.0).pointXY(121.0, 60.0).build())
.add(Geoshape.getShapeFactory().polygon().pointXY(119.0, 59.0).pointXY(121.0, 59.0)
.pointXY(121.0, 61.0).pointXY(119.0, 61.0).pointXY(119.0, 59.0)).build())
此外,当通过 GraphSON 导入图形时,几何图形可能由 GeoJSON 表示:
"37.97, 23.72"
GeoJSON可以指定为 Point、Circle、LineString 或 Polygon。多边形必须闭合。请注意,与 JanusGraph API 不同的是,GeoJSON 将坐标指定为 lng lat。
收藏
如果您使用的是Elasticsearch,那么您可以使用 SET 和 LIST 基数索引属性。例如:
mgmt = graph.openManagement()
nameProperty = mgmt.makePropertyKey("names").dataType(String.class).cardinality(Cardinality.SET).make()
mgmt.buildIndex("search", Vertex.class).addKey(nameProperty, Mapping.STRING.asParameter()).buildMixedIndex("search")
mgmt.commit()
//Insert a vertex
person = graph.addVertex()
person.property("names", "Robert")
person.property("names", "Bob")
graph.tx().commit()
//Now query it
g.V().has("names", "Bob").count().next() //1
g.V().has("names", "Robert").count3.3连接到janusgraph
可以从存在 TinkerPop 驱动程序的所有语言中查询 JanusGraph。驱动程序允许将 Gremlin 遍历发送到 Gremlin 服务器,例如JanusGraph 服务器。TinkerPop 的主页上提供了 TinkerPop 驱动程序列表。
除了驱动程序之外,TinkerPop还存在 查询语言 ,可以更轻松地在 Java、Python 或 C# 等不同编程语言中使用 Gremlin。其中一些语言甚至从完全不同的查询语言(如 Cypher 或 SPARQL)构建 Gremlin 遍历。由于 JanusGraph 实现了 TinkerPop,所有这些语言都可以与 JanusGraph 一起使用。
从 Java 连接
虽然可以将 JanusGraph 作为库嵌入 Java 应用程序中,然后直接连接到后端,但本节假设应用程序连接到 JanusGraph 服务器。有关如何嵌入 JanusGraph 的信息,请参阅JanusGraph 示例项目。
本节仅介绍应用程序如何使用GraphBinary序列化连接到 JanusGraph 服务器。有关Gremlin的介绍和指向更多资源的指针,请参阅Gremlin 查询语言。
JanusGraph 和 Gremlin-Java 入门
在 Java 中开始使用 JanusGraph:
-
使用 Maven 创建一个应用程序:
mvn archetype:generate -DgroupId=com.mycompany.project -DartifactId=gremlin-example -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false -
添加上的依赖
janusgraph-driver和gremlin-driver对依赖管理:马文摇篮<dependency> <groupId>org.janusgraph</groupId> <artifactId>janusgraph-driver</artifactId> <version>0.6.0</version> </dependency> <dependency> <groupId>org.apache.tinkerpop</groupId> <artifactId>gremlin-driver</artifactId> <version>3.5.1</version> </dependency> -
添加两个配置文件,
conf/remote-graph.properties以及conf/remote-objects.yaml:conf/remote-graph.propertiesconf/remote-objects.yamlgremlin.remote.remoteConnectionClass=org.apache.tinkerpop.gremlin.driver.remote.DriverRemoteConnection gremlin.remote.driver.clusterFile=conf/remote-objects.yaml gremlin.remote.driver.sourceName=g -
创建一个
GraphTraversalSource是所有 Gremlin 遍历的基础:import static org.apache.tinkerpop.gremlin.process.traversal.AnonymousTraversalSource.traversal; GraphTraversalSource g = traversal().withRemote("conf/remote-graph.properties"); // Reuse 'g' across the application // and close it on shut-down to close open connections with g.close() -
执行简单的遍历:
Object herculesAge = g.V().has("name", "hercules").values("age").next(); System.out.println("Hercules is " + herculesAge + " years old.");next()是将遍历提交给 Gremlin 服务器并返回单个结果的终端步骤。
JanusGraph 特定类型和谓词
JanusGraph 特定类型和谓词可以通过依赖项直接从 Java 应用程序使用janusgraph-driver。
访问管理 API 的注意事项
所描述的连接使用GraphBinary并且janusgraph-driver不允许访问内部 JanusGraph 组件,例如ManagementSystem. 要访问ManagementSystem,您必须更新包和序列化。
- maven 包
janusgraph-driver需要替换为 maven 包janusgraph-core。 - 文件中的序列化类
conf/remote-objects.yaml必须通过替换className: org.apache.tinkerpop.gremlin.driver.ser.GraphBinaryMessageSerializerV1为className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV1d0,.
从 Python 连接
Gremlin 遍历可以用 Gremlin-Python 构建,就像在 Gremlin-Java 或 Gremlin-Groovy 中一样。有关Gremlin的介绍和指向更多资源的指针,请参阅Gremlin 查询语言。
重要的
一些 Gremlin 步骤和谓词名称是 Python 中的保留字。这些名称_在 Gremlin-Python中只是简单地加上后缀,例如, in()变成in_()、not()变成not_()等等。受此影响的其它名称是:all,and,as,from,global, is,list,or,和set。
JanusGraph 和 Gremlin-Python 入门
要开始使用 Gremlin-Python:
- 安装 Gremlin-Python:
pip install gremlinpython==3.5.1 -
创建一个文本文件
gremlinexample.py并向其中添加以下导入:from gremlin_python import statics from gremlin_python.structure.graph import Graph from gremlin_python.process.graph_traversal import __ from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection -
创建一个
GraphTraversalSource是所有 Gremlin 遍历的基础:from gremlin_python.process.anonymous_traversal_source import traversal connection = DriverRemoteConnection('ws://localhost:8182/gremlin', 'g') # The connection should be closed on shut down to close open connections with connection.close() g = traversal().withRemote(connection) # Reuse 'g' across the application -
执行简单的遍历:
herculesAge = g.V().has('name', 'hercules').values('age').next() print('Hercules is {} years old.'.format(herculesAge))next()是将遍历提交给 Gremlin 服务器并返回单个结果的终端步骤。
JanusGraph 特定类型和谓词
JanusGraph 包含一些不属于 Apache TinkerPop 的类型和谓词,因此 Gremlin-Python 也不支持。
从 .NET 连接
Gremlin 遍历可以用 Gremlin.Net 构建,就像在 Gremlin-Java 或 Gremlin-Groovy 中一样。有关Gremlin的介绍和指向更多资源的指针,请参阅Gremlin 查询语言。Gremlin.Net 的主要语法差异在于它遵循 .NET 命名约定,例如,方法名称使用 PascalCase 而不是 camelCase。
JanusGraph 和 Gremlin.Net 入门
要开始使用 Gremlin.Net:
-
创建一个控制台应用程序:
dotnet new console -o GremlinExample -
添加 Gremlin.Net:
dotnet add package Gremlin.Net -v 3.5.1 -
创建一个
GraphTraversalSource是所有 Gremlin 遍历的基础:using static Gremlin.Net.Process.Traversal.AnonymousTraversalSource; var client = new GremlinClient(new GremlinServer("localhost", 8182)); // The client should be disposed on shut down to release resources // and to close open connections with client.Dispose() var g = Traversal().WithRemote(new DriverRemoteConnection(client)); // Reuse 'g' across the application -
执行简单的遍历:
遍历也可以通过使用var herculesAge = g.V().Has("name", "hercules").Values<int>("age").Next(); Console.WriteLine($"Hercules is {herculesAge} years old.");Promise()这是推荐的方式异步执行, 因为 Gremlin.Net 中的底层驱动程序也异步工作:var herculesAge = await g.V().Has("name", "hercules").Values<int>("age").Promise(t => t.Next());
JanusGraph 特定类型和谓词
JanusGraph 包含一些不属于 Apache TinkerPop 的类型和谓词,因此 Gremlin.Net 也不支持。
4.配置
4.1介绍
一个 JanusGraph 图数据库集群由一个或多个 JanusGraph 实例组成。要打开 JanusGraph 实例,必须提供一个配置,指定应如何设置 JanusGraph。
JanusGraph 配置指定 JanusGraph 应该使用哪些组件,控制 JanusGraph 部署的所有操作方面,并提供许多调整选项以从 JanusGraph 集群获得最大性能。
JanusGraph 配置至少必须定义 JanusGraph 应该用作存储后端的持久性引擎。 Storage Backends列出了所有支持的持久性引擎以及如何分别配置它们。如果需要高级图形查询支持(例如全文搜索、地理搜索或范围查询),则必须配置额外的索引后端。有关详细信息,请参阅 索引后端。如果查询性能是一个问题,则应启用缓存。JanusGraph Cache 中描述了缓存配置和调整。
示例配置
下面是一些示例配置文件,用于演示如何配置最常用的存储后端、索引系统和性能组件。这仅涵盖了可用配置选项的一小部分。 有关所有选项的完整列表,请参阅配置参考。
卡桑德拉 + 弹性搜索
设置 JanusGraph 以使用本地运行的 Cassandra 持久性引擎和远程弹性搜索索引系统:
storage.backend=cql
storage.hostname=localhost
index.search.backend=elasticsearch
index.search.hostname=100.100.101.1, 100.100.101.2
index.search.elasticsearch.client-only=true
HBase+缓存
设置 JanusGraph 以使用远程运行的 HBase 持久性引擎,并使用 JanusGraph 的缓存组件以获得更好的性能。
storage.backend=hbase
storage.hostname=100.100.101.1
storage.port=2181
cache.db-cache = true
cache.db-cache-clean-wait = 20
cache.db-cache-time = 180000
cache.db-cache-size = 0.5
伯克利数据库
设置 JanusGraph 以使用 BerkeleyDB 作为嵌入式持久性引擎,将 Elasticsearch 作为嵌入式索引系统。
storage.backend=berkeleyje
storage.directory=/tmp/graph
index.search.backend=elasticsearch
index.search.directory=/tmp/searchindex
index.search.elasticsearch.client-only=false
index.search.elasticsearch.local-mode=true
配置参考详细描述了所有这些配置选项。confJanusGraph 发行版的目录包含其他配置示例。
进一步的例子
目录中有几个示例配置文件conf/,可用于快速入门 JanusGraph。可以传递到这些文件的路径,JanusGraphFactory.open(...)如下所示:
// Connect to Cassandra on localhost using a default configuration
graph = JanusGraphFactory.open("conf/janusgraph-cql.properties")
// Connect to HBase on localhost using a default configuration
graph = JanusGraphFactory.open("conf/janusgraph-hbase.properties")
使用配置
如何向 JanusGraph 提供配置取决于实例化模式。
JanusGraphFactory
小精灵控制台
JanusGraph 发行版包含一个命令行 Gremlin 控制台,可以轻松入门并与 JanusGraph 交互。调用 bin/gremlin.sh(Unix/Linux) 或bin/gremlin.bat(Windows) 以启动控制台,然后使用工厂打开 JanusGraph 图,配置存储在可访问的属性配置文件中:
graph = JanusGraphFactory.open('path/to/configuration.properties')
JanusGraph 嵌入式
JanusGraphFactory 还可用于从基于 JVM 的用户应用程序中打开嵌入式 JanusGraph 图实例。在这种情况下,JanusGraph 是用户应用程序的一部分,应用程序可以直接通过其公共 API 调用 JanusGraph。
短代码
如果之前已经配置了 JanusGraph 图集群和/或只需要定义存储后端,JanusGraphFactory 接受存储后端名称和主机名或目录的冒号分隔的字符串表示。
graph = JanusGraphFactory.open('cql:localhost')
graph = JanusGraphFactory.open('berkeleyje:/tmp/graph')
JanusGraph 服务器
JanusGraph 本身只是一组没有执行线程的 jar 文件。连接和使用 JanusGraph 数据库有两种基本模式:
-
JanusGraph 可以通过在客户端程序中嵌入 JanusGraph 调用来使用,该程序提供执行线程。
-
JanusGraph 打包了一个长时间运行的服务器进程,当它启动时,允许远程客户端或运行在单独程序中的逻辑进行 JanusGraph 调用。这个长时间运行的服务器进程称为JanusGraph Server。
对于JanusGraph服务器,JanusGraph使用精怪服务器中的Apache的TinkerPop有关堆栈来服务客户端请求。JanusGraph 提供了一个开箱即用的配置,用于快速启动 JanusGraph 服务器,但可以更改配置以提供广泛的服务器功能。
配置 JanusGraph Server 是通过 JanusGraph Server yaml 配置文件完成的,该文件位于 JanusGraph 发行版的 ./conf/gremlin-server 目录中。要使用图形实例 ( JanusGraph)配置 JanusGraph Server ,JanusGraph Server 配置文件需要以下设置:
...
graphs: {
graph: conf/janusgraph-berkeleyje.properties
}
scriptEngines: {
gremlin-groovy: {
plugins: { org.janusgraph.graphdb.tinkerpop.plugin.JanusGraphGremlinPlugin: {},
org.apache.tinkerpop.gremlin.server.jsr223.GremlinServerGremlinPlugin: {},
org.apache.tinkerpop.gremlin.tinkergraph.jsr223.TinkerGraphGremlinPlugin: {},
org.apache.tinkerpop.gremlin.jsr223.ImportGremlinPlugin: {classImports: [java.lang.Math], methodImports: [java.lang.Math#*]},
org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {files: [scripts/empty-sample.groovy]}}}}
...
条目graphs定义了特定JanusGraph 配置的绑定。在上述情况下,它绑定graph到 JanusGraph 配置conf/janusgraph-berkeleyje.properties。该plugins 条目启用 JanusGraph Gremlin 插件,该插件启用 JanusGraph 类的自动导入,以便可以在远程提交的脚本中引用它们。
在JanusGraph Server 中了解有关配置和使用 JanusGraph Server 的更多信息。
服务器分布
JanusGraph zip 文件包含一个快速启动服务器组件,有助于更轻松地开始使用 Gremlin Server 和 JanusGraph。调用bin/janusgraph.sh start以使用 Cassandra 和 Elasticsearch 启动 Gremlin Server。
笔记
出于安全原因 Elasticsearch 因此janusgraph.sh必须在非 root 帐户下运行
笔记
从 0.5.1 开始,这只是包含在完整包版本中。
全局配置
JanusGraph 区分本地和全局配置选项。本地配置选项适用于单个 JanusGraph 实例。全局配置选项适用于集群中的所有实例。更具体地说,JanusGraph 区分了以下五个配置选项范围:
-
LOCAL:这些选项仅适用于单个 JanusGraph 实例,并在初始化 JanusGraph 实例时提供的配置中指定。
-
MASKABLE:本地配置文件可以为单个 JanusGraph 实例覆盖这些配置选项。如果本地配置文件未指定该选项,则从全局 JanusGraph 集群配置中读取其值。
-
GLOBAL:这些选项总是从集群配置中读取,不能在实例基础上被覆盖。
-
GLOBAL_OFFLINE:与GLOBAL类似,但更改这些选项需要重新启动集群以确保整个集群中的值相同。
-
已修复:与GLOBAL类似,但一旦 JanusGraph 集群初始化,该值就无法更改。
当集群中的第一个 JanusGraph 实例启动时,全局配置选项从提供的本地配置文件中初始化。随后更改全局配置选项是通过 JanusGraph 的管理 API 完成的。要访问管理 API,请调用g.getManagementSystem()打开的 JanusGraph 实例句柄g。例如,要更改 JanusGraph 集群上的默认缓存行为:
mgmt = graph.openManagement()
mgmt.get('cache.db-cache')
// Prints the current config setting
mgmt.set('cache.db-cache', true)
// Changes option
mgmt.get('cache.db-cache')
// Prints 'true'
mgmt.commit()
// Changes take effect
更改离线选项
更改配置选项不会影响正在运行的实例,仅适用于新启动的实例。更改GLOBAL_OFFLINE 配置选项需要重新启动集群,以便更改对所有实例立即生效。要更改 GLOBAL_OFFLINE选项,请执行以下步骤:
- 关闭集群中除一个 JanusGraph 实例外的所有实例
- 连接到单个实例
- 确保所有正在运行的事务都已关闭
- 确保没有新的事务被启动(即集群必须离线)
- 打开管理API
- 更改配置选项
- 调用 commit 将自动关闭图形实例
- 重启所有实例
有关更多信息,包括每个选项的配置范围,请参阅配置参考中的配置选项的完整列表

















 2192
2192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









