







 这篇博客详细介绍了C++编译器的工作过程,包括预处理、编译、汇编和链接四个步骤。预处理涉及宏定义展开、头文件包含、行号添加等;编译阶段包括词法分析、语法分析、语义分析等多个环节,生成汇编代码;汇编阶段将汇编代码转化为机器码;链接阶段解决符号引用,生成可执行文件。博客深入剖析了每个步骤的具体细节,是理解C++编译过程的好资源。
这篇博客详细介绍了C++编译器的工作过程,包括预处理、编译、汇编和链接四个步骤。预处理涉及宏定义展开、头文件包含、行号添加等;编译阶段包括词法分析、语法分析、语义分析等多个环节,生成汇编代码;汇编阶段将汇编代码转化为机器码;链接阶段解决符号引用,生成可执行文件。博客深入剖析了每个步骤的具体细节,是理解C++编译过程的好资源。
在Linux下,用GCC来编译程序(如gcc test.c )可以分解为4个步骤,分别是预处理、编译、汇编和链接。
具体如下图所示:
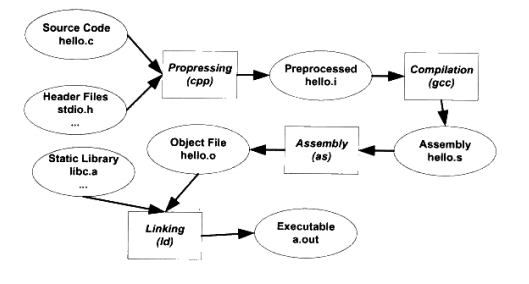
1、预处理
首先是源代码文件test.c和相关的头文件,如stdio.h等被预处理器cpp预处理成一个.i文件。第一步预处理的过程相当于如下命令(-E表示只进行预处理):
gcc -E test.c -o test.i
预处理过程主要处理那些源代码文件只能够的以"#"开始的预编译指令。比如“#include”、“#define”等,主要处理规则如下:
(1)将所有的“#define“删除,并且展开所有的宏定义;
(2)处理所有条件预编译指令,比如”#if“、”#ifdef“、”#elif“、”#else“、#endif;
(3)处理”#include“预编译指令,将被包含的文件插入到该预编译指令的位置。注意:这个过程是递归进行的,也就是说被包含的文件可能还包含其他文件;
(4)标记化 。每一条注释被一个单独的空字符所替换。C++双字符运算符被识别为标记(为了开发可读性更强的程序,C++为非ASCII码开发者定义了一套双字符运算符集和新的保留字集)。源代码被分析成预处理标记。
(5)添加行号和文件名标识,比如#2 "test.c" 2,以便于编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告时能够显示行号;
(6)保留所有的#pragma编译器指令,因为编译器需要使用它们;
(7)字符映射 。文件中的物理源字符被映射到源字符集中,其中包括三字符运算符的替换、控制字符(行尾的回车换行)的替换。
(8)行合并 。以反斜杠\结束的行和它接下来的行合并。
经过预编译后的.i文件不包含任何宏定义,因为所有的宏已经被展开,并且包含的文件也已经被插入到.i文件中。所以当我们无法判断宏定义是否正确或头文件包含是否正确时,可以查看预处理后的文件来确定问题。
2、编译
编译过程就是把预处理完的文件进行一系列的词法分析、语法分析、语义分析以及优化后产生相应的汇编代码文件,这个过程往往是我们所说的整个程序的构建的核心部分,也是最复杂的部分之一。上面的编译过程相当于如下命令:
gcc -S test.i -o test.s
现在版本的GCC把预处理和编译两个步骤合并成一个步骤,使用一个叫ccl的程序来完成两个步骤。我们可以直接使用如下命令:
gcc -S test.c -o test.s
都可以得到汇编输出文件test.s。对于C语言代码来说,这个预处理和编译的程序是ccl,对于C++来说,有对应的程序叫做cclplus。所以实际上gcc这个命令只是这些后台程序的包装,它会根据不同的参数要求取调用预处理编译程序ccl、汇编器as、链接器ld。
(1)编译步骤
从最直观的角度来讲,编译器就是将高级语言翻译成机器语言的一个工具。比如我们可以用C/C++语言写的一个程序可以使用编译器将其翻译成机器可以执行的指令及数据。
编译的过程一般分为6步:
词法分析、语法分析、语义分析、源代码优化、代码生成和目标代码优化。
整个过程如下图所示: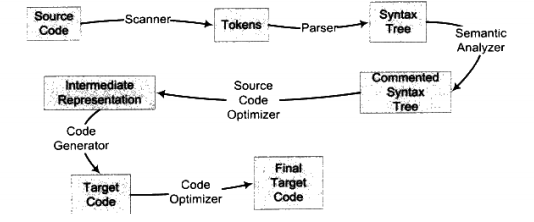
我们将结合上图来简单描述从源代码到最终目标代码的过程。以一段很简单的C语义的代码为例子来讲述这个过程。比如我们有一行C语义的源代码如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









