







 本文详细介绍了Memcached的工作原理,包括为何使用它来解决数据库高并发读写和海量数据处理的问题。讲解了Memcached的安装和使用,并探讨了基于libevent的事件处理机制。此外,文章还深入剖析了Memcached的内存管理,特别是Slab分配算法,以及如何通过LRU算法来支持高并发和淘汰数据。
本文详细介绍了Memcached的工作原理,包括为何使用它来解决数据库高并发读写和海量数据处理的问题。讲解了Memcached的安装和使用,并探讨了基于libevent的事件处理机制。此外,文章还深入剖析了Memcached的内存管理,特别是Slab分配算法,以及如何通过LRU算法来支持高并发和淘汰数据。
1.为什么要使用memcache
由于网站的高并发读写需求,传统的关系型数据库开始出现瓶颈,例如:
1)对数据库的高并发读写:
关系型数据库本身就是个庞然大物,处理过程非常耗时(如解析SQL语句,事务处理等)。如果对关系型数据库进行高并发读写(每秒上万次的访问),那么它是无法承受的。
2)对海量数据的处理:
对于大型的SNS网站,每天有上千万次的数据产生(如twitter, 新浪微博)。对于关系型数据库,如果在一个有上亿条数据的数据表种查找某条记录,效率将非常低。
使用memcache能很好的解决以上问题。
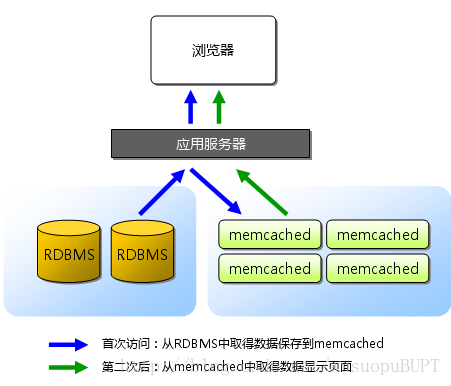
在实际使用中,通常把数据库查询的结果保存到Memcache中,下次访问时直接从memcache中读取,而不再进行数据库查询操作,这样就在很大程度上减少了数据库的负担。
保存在memcache中的对象实际放置在内存中,这也是memcache如此高效的原因。
2.memcache的安装和使用
这个网上有太多教程了,不做赘言。
3.基于libevent的事件处理
libevent是个程序库,它将Linux的 epoll、BSD类操作系统的kqueue等事件处理功能 封装成统一的接口。即使对服务器的连接数增加,也能发挥O(1)的性能。
memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。
参考:
- libevent: http://www.monkey.org/~provos/libevent/
- The C10K Problem: http://www.kegel.com/c10k.html
4.memcache使用实例:
- <?php
- $mc = new Memcache();
- $mc->connect('127.0.0.1', 11211);
- $uid = (int)$_GET['uid'];
- $sql = "select * from users where uid='uid' ";
- $key = md5($sql);
- if(!($data = $mc->get($key))) {
- $conn = mysql_connect('localhost', 'test', 'test');
- mysql_select_db('test');
- $result = mysql_fetch_object($result);
- while($row = mysql_fetch_object($result)) {
- $data[] = $row;
- }
- $mc->add($key, $datas);
- }
- var_dump($datas);
- ?>
<?php
$mc = new Memcache();
$mc->connect('127.0.0.1', 11211);
$uid = (int)$_GET['uid'];
$sql = "select * from users where uid='uid' ";
$key = md5($sql);
if(!($data = $mc->get($key))) {
$conn = mysql_connect('localhost', 'test', 'test');
mysql_select_db('test');
$result = mysql_fetch_object($result);
while($row = mysql_fetch_object($result)) {
$data[] = $row;
}
$mc->add($key, $datas);
}
var_dump($datas);
?>
5.memcache如何支持高并发(此处还需深入研究)
memcache使用多路复用I/O模型,如(epoll, select等),传统I/O中,系统可能会因为某个用户连接还没做好I/O准备而一直等待,知道这个连接做好I/O准备。这时如果有其他用户连接到服务器,很可能会因为系统阻塞而得不到响应。
而多路复用I/O是一种消息通知模式,用户连接做好I/O准备后,系统会通知我们这个连接可以进行I/O操作,这样就不会阻塞在某个用户连接。因此,memcache才能支持高并发。
此外,memcache使用了多线程机制。可以同时处理多个请求。线程数一般设置为CPU核数,这研报告效率最高。
6.使用Slab分配算法保存数据
slab分配算法的原理是:把固定大小(1MB)的内存分为n小块,如下图所示:
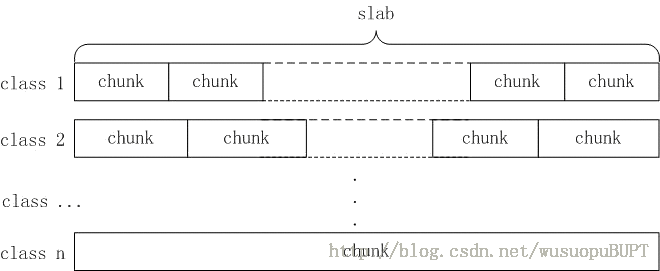
slab分配算法把每1MB大小的内存称为一个slab页,每次向系统申请一个slab页,然后再通过分隔算法把这个slab页分割成若干个小块的chunk(如上图所示),然后把这些chunk分配给用户使用,分割算法如下(在slabs.c文件中):
(注:memcache的github项目地址:https://github.com/wusuopubupt/memcached)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









