







Profile_Day04:企业级360°全方位用户画像
1昨日课程内容回顾
主要讲解:标签模型应用开发,针对规则匹配类型模型开发,涉及2大方面的内容:
- 第一方面内容: 标签模型开发,以[用户性别标签模型为例],整个开发步骤流程
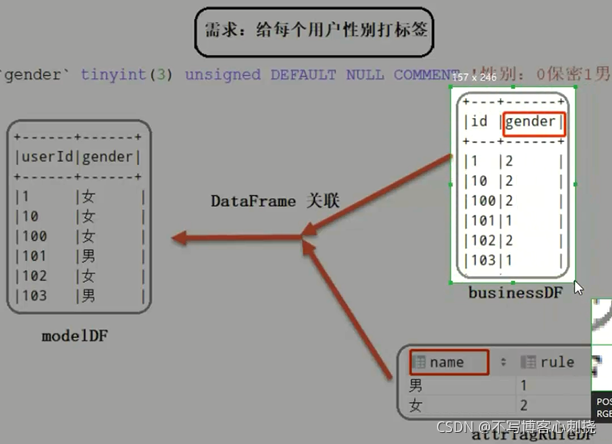
- 给每个用户打上性别标签,存储到HBase画像标签表: tb_profile
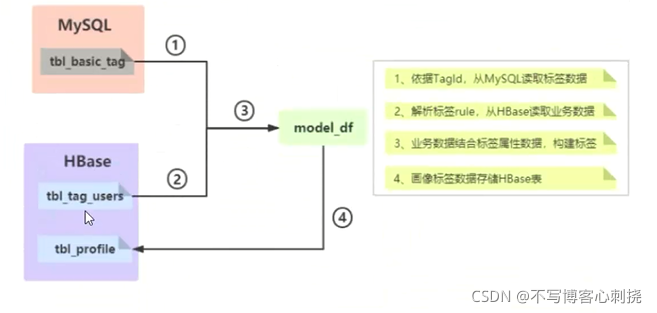
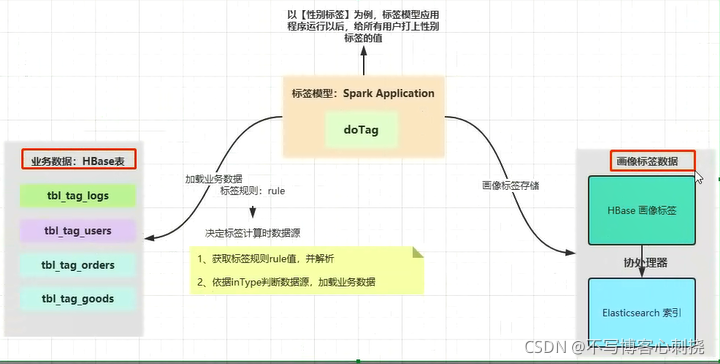
- 标签模型开发分为四个步骤
- 1,依据每个标签(4级业务标签)tagld,获取标签数据
- 业务标签标签规则rule; 标签计算业务数据源的信息
- 业务标签对应的属性标签信息: 标签名称bname,标签规则
2),解析业务标签规则,到数据源(HBase)加载业务数据源
- 解析标签规则标签rule,解析为Map集合
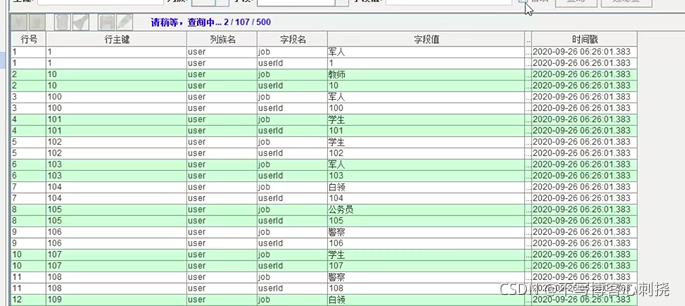
- 判断数据源类型: intype,当数据源为HBase时,封装数据源信息至元数据类HBaseMeta,加载业务数据,包含用户的标识符UserId,业务相关的字段
- 3).业务数据结合属性标签数据,构建标签
- 不同类型标签计算,业务逻辑实现方式不一样,以规则匹配类型标签为例,匹配规则
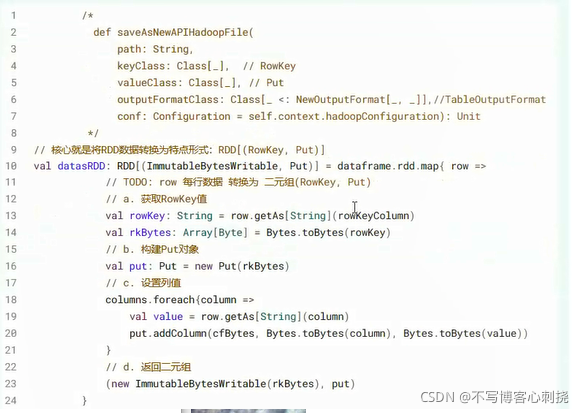
- 4保存结果到HBase表中

编写工具类,方便直接与HBase表交互,读写HBase表数据
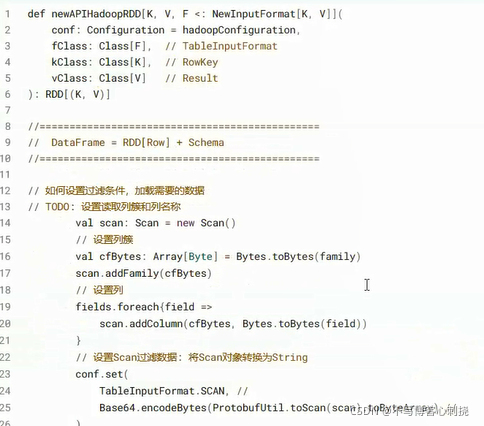
工具类HBaseTools,提供2个方法:read加载数据核write保存数据
- 1,加载数据load:
- 2保存数据sava:
- 第二个方面的内容:规则匹配类型标签模型开发
- 将业务数据中业务类型字段fileld与属性标签中规则进行匹配关联,给用户打上标签的值(tagName)
- 实现方式2种
- 方式一:将业务数据BusinessDF和属性标签规则数据attrTagRuleDF进行JOIN
- 方式二:自定义udf函数,通过广播变量的方式

- 第三方面内容:标签模型开发
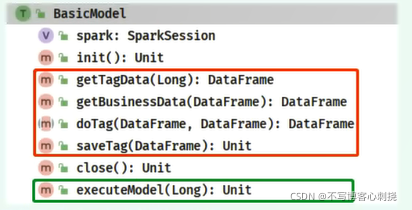
- 每个标签模型开发时,四种主要是4个步骤,只是在打标签这个步骤不一样外,其他步骤代码基本上一致或只需要稍稍改动,对标签模型进行重构,开发基类BasicModel
- 第一步,使用设计模式:模板方法设计模式(TemplateParttern)
- 思想:属于一种类继承设计模式,父类(基类)和子类
基类(父类)中有两种方法: 1),基本方法可以是具体方法,也可以是抽象方法(给子类实现) 完成每个小的功能,比如针对标签模型应用程序来说 创建SparkSession实例对象 关闭SparkSession实例对象 加载标签数据 加载业务数据 2),模板方法 规则基本方法执行顺序
- 第二步,属性配置,数据库信息和应用属性信息
- 1 ,数据库相关配置数据,MySQL数据库(标签数据)和HBase数据库(画像标签数据)
- 属性配置文件:config.properties
- 使用库: TypeSafe加载属性配置文件,编写工具类类:ModelConfig
- 2,创建SparkSession实例对象时,基本信息设置
1) 是否是本地模式运行isLocal 2),是否集成Hive 3) Spark Application属性
编写SparkUtils工具类,提供1个方法,专门创建SparkSession对象

2,今日课程内容提纲
主要讲解两个方面的内容:自定义实现SparkSql外部数据源HBase和统计类型标签模型开发
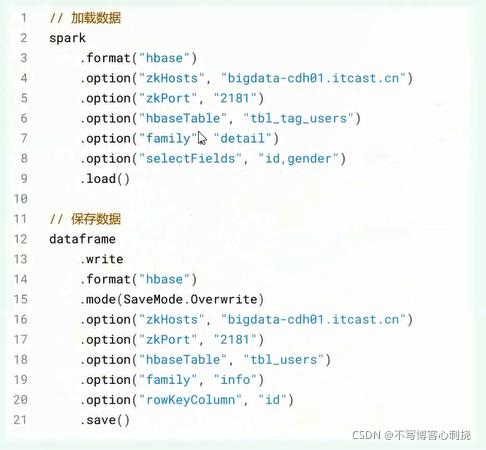
- 1,自定义SparkSQl外部数据源HBase
- 在SparkSQL中提供一套外部数据源的接口,方便存储外部存储引擎加载和保存数据
分为如下8个章节讲解:属于SparkSQl模块中高级功能
- 2 统计类型标签模型开发
- 在实际用户画像模型开发中,更多标签模型属于:规则匹配类型标签和统计类型标签
- 统计类型标签:
- 第一步, 适用业务相关字段,进行统计聚合计算,使用函数完成比如groupby,agg,max
- 第二步,结合属性标签规则rule进行打标签
上述三个统计类型标签来说,使用SparkSql中不同技术,综合使用- [年龄段]标签模型:比较函数
- [消费周期]标签模型:日期函数
- [支付方式] 窗口分析函数



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









