






SQL
SQL分为两个部分,一个是操作语言(DML)。一个是数据定义语言(DDL)
查询和更新指令构成了SQL的DML部分
- SELECT——从数据库表中获取数据
- UPDATE——更新数据库表中的数据
- DELETE——从数据库表中删除数据
- INSERT INTO——向数据库表中插入数据
SQL的数据定义语言(DDL)部分使我们有能力创建或删除表哥,我们也可以定义索引(键),规定表之间的链接,以及施加表间的约束(实际工作中很少会添加那么多约束,因为这样会导致查询效率很低)
SQL中最重要的DDL语句
- CREATE DATABASE——创建新数据库
- ALTER DATABASE——修改数据库
- CREATE TABLE——创建新表
- ALTER TABLE——变更(改变)数据库表
- DROP TABLE——删除表
- CREATE INDEX——创建索引(搜索键)
- DROP INDEX——删除索引
DDL
创建
创建表
CREATE TABLE Websites
(
id bigint(20) NOT NULL,
url varchar(20),
alexa int,
country varchar(20)
);
设置id为主键
- 如果之前已经建好了表
ALTER TABLE Websites
ADD PRIMARY KEY (id);
- 如果没有建好表
CREATE TABLE Websites
(
id bigint(20) NOT NULL,
url varchar(20),
alexa int,
country varchar(20),
PRIMARY KEY (id)
);
取消主键
DROP PRIMARY KEY
把多个列设置为主键
ADD CONSTRAINT pk_PersonID PRIMARY KEY (Id_P,LastName)
外键
添加外键
/* 在Person表的id_P后面插入一个w_id*/
ALTER TABLE Persons ADD w_id bigint(20) AFTER id_P;
/* 把Persons中的w_id设置为外键,和Websites中的id做关联*/
ALTER TABLE Persons ADD FOREIGN KEY (w_id) REFERENCES Websites(id);
取消外键
DROP FOREIGN KEY
DML
insert
向表中插入数据
/*向表中插入数据*/
INSERT INTO 表名称 VALUES (值1, 值2,....)
/*向指定列中插入数据*/
INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....)
如果没有指定要插入数据的列名必须要列出插入行的每一列数据
select
/*选择全部数据*/
SELECT * FROM 表名;
/*选择部分数据*/
SELECT 列名 FROM 表名;
/*去掉重复的部分*/
SLECT DISTINCT 列名 FROM 表名;
distinct的使用方法如下:
mysql> SELECT DISTINCT LastName FROM Persons;
+----------+
| LastName |
+----------+
| 234 |
| 四 |
| 三 |
| 五 |
+----------+
4 rows in set (0.01 sec)
如果不加distinct
mysql> SELECT LastName FROM Persons;
+----------+
| LastName |
+----------+
| 234 |
| 四 |
| 三 |
| 五 |
| 五 |
+----------+
where
mysql> SELECT * FROM Persons WHERE LastName = '五';
+------+------+----------+-----------+-----------+-----------+
| Id_P | w_id | LastName | FirstName | Address | City |
+------+------+----------+-----------+-----------+-----------+
| 237 | 1002 | 五 | 王 | 花果山 | 连云港 |
| 238 | 1002 | 五 | 王 | 泰山 | 泰安 |
+------+------+----------+-----------+-----------+-----------+
2 rows in set (0.05 sec)
文本字段使用单引号引起来,数值字段不用引号
- 一些常用的运算符
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。**注释:**在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
-
逻辑运算
AND: 与 同时满足两个条件的值
SELECT * FROM Websites WHERE alexa > 0 AND alexa < 300;OR:或 满足一个就可以了
SELECT * FROM Websites WHERE alexa > 300 OR alexa < 1;NOT:非 满足不包含该条件的值
SELECT * FROM Websites WHERE NOT alexa > 30这个相当于小于等于30
逻辑运算的优先级
() > NOT AND OR -
特殊条件
空值判断 is null
SELECT * FROM Websites WHERE alexa is null从Websites中选出alexa是空的一列
between and(在。。。之间的值)
SELECT * FROM Websites WHERE alexa between 1500 and 3000 -- 查询列中等于 5000,3000,1500 的值in
SELECT * FROM Websites LastName WHERE alexa in(1,2,7)like
SELECT * FROM Websites WHERE LastName LIKE 'M%'查询 Websites 表中 LastName 列中有李 的值,M 为要查询内容中的模糊信息。
- % 表示多个字值,_ 下划线表示一个字符;
- M% : 为能配符,正则表达式,表示的意思为模糊查询信息为 M 开头的。
- %M% : 表示查询包含M的所有内容。
- %M_ : 表示查询以M在倒数第二位的所有内容。
‘%a’ //以a结尾的数据
‘a%’ //以a开头的数据
‘%a%’ //含有a的数据
‘a’ //三位且中间字母是a的
‘_a’ //两位且结尾字母是a的
‘a_’ //两位且开头字母是a的
两个比较特殊的WHERE子句子
SELECT studentNO FROM student WHERE 0;
--则会返回一个空集,因为每一行记录 WHERE 都返回 false。
SELECT studentNO FROM student WHERE 1
--返回 student 表所有行中 studentNO 列的值。因为每一行记录 WHERE 都返回 true。
INSERT INTO SELECT
insert into select可以从一个表中复制信息到另外一个表
insert into (准备好的表) select *(或者取用自己想要的结构)from 表名 where 各种条件
INSERT INTO FROM
也可以从一个表中复制信息到另外一个表,但是目标表不能存在,在插入数据的时候会自动建表
创建一个表并且从另外一个表复制数据
CREATE TABLE Websites_copy as select * FROM Websites;
mysql> SELECT * FROM Websites_copy;
+------+---------------------+-------+---------+
| id | url | alexa | country |
+------+---------------------+-------+---------+
| 1001 | http://baidu.com | 2 | cn |
| 1002 | http://souhu.com | 1 | cn |
| 1003 | http://bing.com | 9 | us |
| 1004 | http://apple.com | 3 | us |
| 1005 | http://bilibili.com | 3 | cn |
+------+---------------------+-------+---------+
5 rows in set (0.00 sec)
Websites_copy就是新的表
如果只是复制结构的话
CREATE TABLE Websites_copy_struct as select * FROM Websites WHERE 1=2;
DAY2
ORDER BY
websites表的结构如下:
mysql> SELECT * FROM Websites;
+------+---------------------+-------+---------+
| id | url | alexa | country |
+------+---------------------+-------+---------+
| 1001 | http://baidu.com | 2 | cn |
| 1002 | http://souhu.com | 1 | cn |
| 1003 | http://bing.com | 9 | us |
| 1004 | http://apple.com | 3 | us |
| 1005 | http://bilibili.com | 3 | cn |
+------+---------------------+-------+---------+
5 rows in set (0.00 sec)
按照alexa排序
mysql> SELECT * FROM Websites ORDER BY alexa;
+------+---------------------+-------+---------+
| id | url | alexa | country |
+------+---------------------+-------+---------+
| 1002 | http://souhu.com | 1 | cn |
| 1001 | http://baidu.com | 2 | cn |
| 1004 | http://apple.com | 3 | us |
| 1005 | http://bilibili.com | 3 | cn |
| 1003 | http://bing.com | 9 | us |
+------+---------------------+-------+---------+
5 rows in set (0.00 sec)
默认是升序,也可以降序
降序排列:
mysql> SELECT * FROM Websites ORDER BY alexa DESC;
+------+---------------------+-------+---------+
| id | url | alexa | country |
+------+---------------------+-------+---------+
| 1003 | http://bing.com | 9 | us |
| 1004 | http://apple.com | 3 | us |
| 1005 | http://bilibili.com | 3 | cn |
| 1001 | http://baidu.com | 2 | cn |
| 1002 | http://souhu.com | 1 | cn |
+------+---------------------+-------+---------+
5 rows in set (0.05 sec)
UPDATE
UPDATE Websites SET alexa='20' WHERE id=1001;
mysql> select * from websites;
+------+---------------------+-------+---------+
| id | url | alexa | country |
+------+---------------------+-------+---------+
| 1001 | http://baidu.com | 20 | cn |
| 1002 | http://souhu.com | 1 | cn |
| 1003 | http://bing.com | 9 | us |
| 1004 | http://apple.com | 3 | us |
| 1005 | http://bilibili.com | 3 | cn |
+------+---------------------+-------+---------+
5 rows in set (0.00 sec)
UPDATE注意 ⚠️
如果update后面没有跟where语句,所有的数据都会发生改变,比如
UPDATE Websites SET alexa='5000',country='us';
这样就会把表中所有的数据中的alex变成5000,country变成us
执行没有 WHERE 子句的 UPDATE 要慎重,再慎重。
在 MySQL 中可以通过设置 sql_safe_updates 这个自带的参数来解决,当该参数开启的情况下,你必须在update 语句后携带 where 条件,否则就会报错。
set sql_safe_updates=1; 表示开启该参数
DELETTE
-- 基本用法
mysql> select * from Websites;
+------+---------------------+-------+---------+
| id | url | alexa | country |
+------+---------------------+-------+---------+
| 1001 | http://baidu.com | 20 | cn |
| 1002 | http://souhu.com | 1 | cn |
| 1003 | http://bing.com | 9 | us |
| 1004 | http://apple.com | 3 | us |
| 1005 | http://bilibili.com | 3 | cn |
| 1006 | http://alibaba.com | 30 | cn |
| 1007 | http://sony.com | 60 | jp |
| 1008 | http://honda.com | 94 | jp |
+------+---------------------+-------+---------+
8 rows in set (0.00 sec)
mysql> DELETE FROM Websites WHERE alexa=94;
Query OK, 1 row affected (0.00 sec)
和update一样如果后面不加where参数的话,所有的数据都会被删除
拓展:DROP,TRUNCATE,DELETE的区别
DROP
DROP test;
-- 可以删除表test,并且释放空间,将test删除的一干二净
TRUNCATE
TRUNCATE test;
-- 删除表test中的内容,并且释放空间,但不删除表的定义,表的结构还在
DELETE
DELETE FROM Websites WHERE alexa=94;
-- 删除单条数据
DELETE FROM Websites
-- 删除整个表的数据,不释放空间,保留表的定义
SELECT TOP
select top字句用于规定要返回的记录的数目,对于大型表来说,是非常有用的
但是也不是所有的数据库系统都支持SELCET TOP语句,Mysql支持limit语句来选去指定的条数数据
Mysql
SELECT alexa FROM Websites LIMIT 3;
mysql> SELECT alexa FROM Websites LIMIT 3;
+-------+
| alexa |
+-------+
| 20 |
| 1 |
| 9 |
+-------+
SELECT TOP PRECENT
Sql-server里面可以设置百分比
SELECT TOP 50 PERCENT * FROM Websites;
返回前50%
SQL [Charlist]通配符
Mysql中使用REGEXP或者NOT REGEXP运算符(或者RLIKE和NOT RLIKE)来操作正则表达式
mysql> SELECT * FROM Websites WHERE country REGEXP '^[j]';
+------+-----------------+-------+---------+
| id | url | alexa | country |
+------+-----------------+-------+---------+
| 1007 | http://sony.com | 60 | jp |
+------+-----------------+-------+---------+
1 row in set (0.00 sec)
-- 返回网站的国家中以j开头的
mysql> SELECT * FROM Websites WHERE country REGEXP '^[j-u]';
+------+------------------+-------+---------+
| id | url | alexa | country |
+------+------------------+-------+---------+
| 1003 | http://bing.com | 9 | us |
| 1004 | http://apple.com | 3 | us |
| 1007 | http://sony.com | 60 | jp |
+------+------------------+-------+---------+
3 rows in set (0.00 sec)
-- 返回j-u之间的
mysql> SELECT * FROM Websites WHERE country REGEXP '^[^j-u]';
+------+---------------------+-------+---------+
| id | url | alexa | country |
+------+---------------------+-------+---------+
| 1001 | http://baidu.com | 20 | cn |
| 1002 | http://souhu.com | 1 | cn |
| 1005 | http://bilibili.com | 3 | cn |
| 1006 | http://alibaba.com | 30 | cn |
+------+---------------------+-------+---------+
4 rows in set (0.00 sec)
-- 不以j-u之间开头的
别名
通过使用SQL,可以为表名或者列名指定别名,使可读性更强
-- 查询到的alexa设置为排名
mysql> select alexa as 排名 FROM websites;
+--------+
| 排名 |
+--------+
| 20 |
| 1 |
| 9 |
| 3 |
| 3 |
| 30 |
| 60 |
+--------+
7 rows in set (0.00 sec)
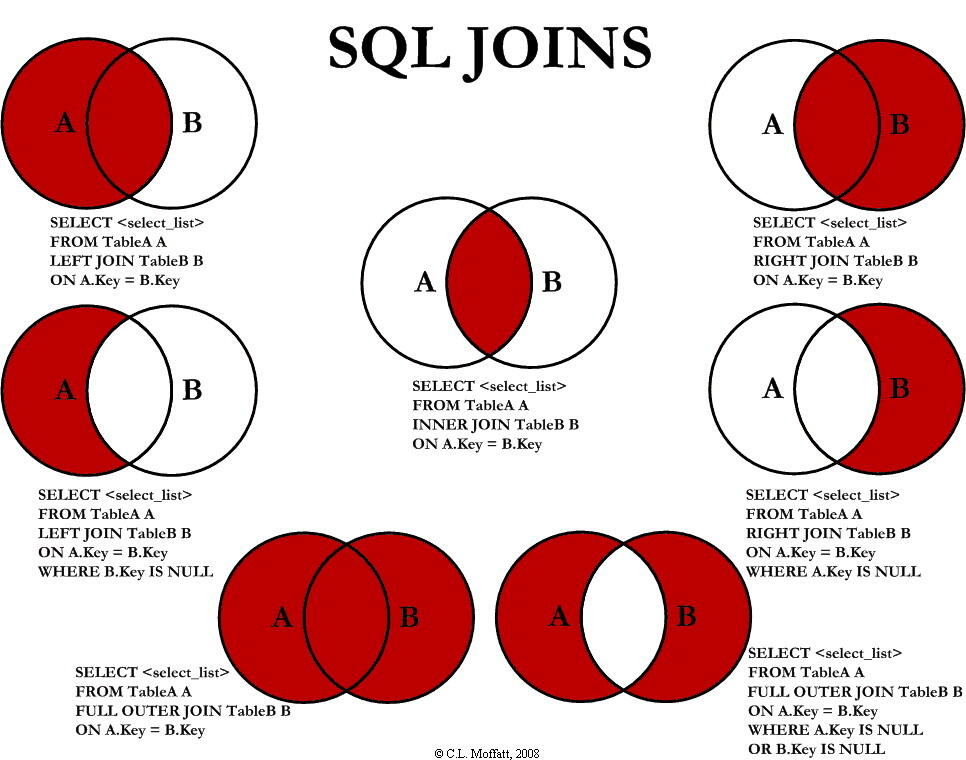
JOIN
JOIN把来自两个或者多个表的行结合起来,基于这些表之间的共同字段
新建一个access_log表
mysql> select * from access_log;
+------+---------+-------+---------------------+
| aid | site_id | count | date |
+------+---------+-------+---------------------+
| 1 | 1001 | 89 | 2020-12-28 18:22:21 |
| 2 | 1001 | 89 | 2020-12-28 18:22:30 |
| 2 | 1001 | 231 | 2020-12-28 18:22:37 |
| 2 | 1005 | 871 | 2020-12-28 18:22:49 |
| 7 | 1003 | 456 | 2020-12-28 18:23:01 |
| 8 | 1003 | 496 | 2020-12-28 18:23:10 |
| 9 | 1800 | 2131 | 2020-12-28 18:35:56 |
+------+---------+-------+---------------------+
-- 为了方便对照,把Websites表也打印下来
mysql> select * from websites;
+------+---------------------+-------+---------+
| id | url | alexa | country |
+------+---------------------+-------+---------+
| 1001 | http://baidu.com | 20 | cn |
| 1002 | http://souhu.com | 1 | cn |
| 1003 | http://bing.com | 9 | us |
| 1004 | http://apple.com | 3 | us |
| 1005 | http://bilibili.com | 3 | cn |
| 1006 | http://alibaba.com | 30 | cn |
| 1007 | http://sony.com | 60 | jp |
+------+---------------------+-------+---------+
7 rows in set (0.00 sec)
INNER JOIN

mysql> SELECT Websites.id,Websites.url,access_log.count,access_log.date from websites INNER JOIN access_log ON Websites.id=access_log.site_id;
+------+---------------------+-------+---------------------+
| id | url | count | date |
+------+---------------------+-------+---------------------+
| 1001 | http://baidu.com | 89 | 2020-12-28 18:22:21 |
| 1001 | http://baidu.com | 89 | 2020-12-28 18:22:30 |
| 1001 | http://baidu.com | 231 | 2020-12-28 18:22:37 |
| 1005 | http://bilibili.com | 871 | 2020-12-28 18:22:49 |
| 1003 | http://bing.com | 456 | 2020-12-28 18:23:01 |
| 1003 | http://bing.com | 496 | 2020-12-28 18:23:10 |
+------+---------------------+-------+---------------------+
6 rows in set (0.00 sec)
LEFT JOIN
返回左边表的所有行,即使右表(table)中没有匹配。
如果右表中没有匹配,则结果为null

mysql> SELECT Websites.id,Websites.url,access_log.count,access_log.date from websites LEFT JOIN access_log ON Websites.id=access_log.site_id;
+------+---------------------+-------+---------------------+
| id | url | count | date |
+------+---------------------+-------+---------------------+
| 1001 | http://baidu.com | 89 | 2020-12-28 18:22:21 |
| 1001 | http://baidu.com | 89 | 2020-12-28 18:22:30 |
| 1001 | http://baidu.com | 231 | 2020-12-28 18:22:37 |
| 1002 | http://souhu.com | NULL | NULL |
| 1003 | http://bing.com | 456 | 2020-12-28 18:23:01 |
| 1003 | http://bing.com | 496 | 2020-12-28 18:23:10 |
| 1004 | http://apple.com | NULL | NULL |
| 1005 | http://bilibili.com | 871 | 2020-12-28 18:22:49 |
| 1006 | http://alibaba.com | NULL | NULL |
| 1007 | http://sony.com | NULL | NULL |
+------+---------------------+-------+---------------------+
10 rows in set (0.00 sec)
inner join的一个变种

mysql> SELECT Websites.id,Websites.url,access_log.count,access_log.date from websites LEFT JOIN access_log ON Websites.id=access_log.site_id WHERE access_log.site_id is NULL;
+------+--------------------+-------+------+
| id | url | count | date |
+------+--------------------+-------+------+
| 1002 | http://souhu.com | NULL | NULL |
| 1004 | http://apple.com | NULL | NULL |
| 1006 | http://alibaba.com | NULL | NULL |
| 1007 | http://sony.com | NULL | NULL |
+------+--------------------+-------+------+
4 rows in set (0.00 sec)
FULL OUTER JOIN
主要坐标和右表其中一个表中存在匹配,则返回行
Mysql暂时不支持全full outer join,可以用left join + right join来实现
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YAM04nq7-1609165697119)(/Users/cjp/Library/Application Support/typora-user-images/image-20201228200939220.png)]
RIGHT JOIN
从右表返回所有的行,即使左表没有匹配,如果左表没有匹配,则结果为null

mysql> SELECT Websites.id,Websites.url,access_log.count,access_log.date from websites RIGHT JOIN access_log ON Websites.id=access_log.site_id;
+------+---------------------+-------+---------------------+
| id | url | count | date |
+------+---------------------+-------+---------------------+
| 1001 | http://baidu.com | 89 | 2020-12-28 18:22:21 |
| 1001 | http://baidu.com | 89 | 2020-12-28 18:22:30 |
| 1001 | http://baidu.com | 231 | 2020-12-28 18:22:37 |
| 1005 | http://bilibili.com | 871 | 2020-12-28 18:22:49 |
| 1003 | http://bing.com | 456 | 2020-12-28 18:23:01 |
| 1003 | http://bing.com | 496 | 2020-12-28 18:23:10 |
| NULL | NULL | 2131 | 2020-12-28 18:35:56 |
+------+---------------------+-------+---------------------+
Right join的变种
mysql> SELECT Websites.id,Websites.url,access_log.count,access_log.date from websites RIGHT JOIN access_log ON Websites.id=access_log.site_id WHERE Websites.id
IS NULL;
+------+------+-------+---------------------+
| id | url | count | date |
+------+------+-------+---------------------+
| NULL | NULL | 2131 | 2020-12-28 18:35:56 |
+------+------+-------+---------------------+
1 row in set (0.00 sec)
总结
- inner join:如果表中至少有一个匹配,则返回行
- left join:即使右表中没有匹配,也从左表返回所有行
- right join 即使左表没有匹配,也从右表返回所有的行
- full join 只要其中有一个表存在匹配,则返回行(mysql不支持)
join中on和where条件的区别
1、on条件是在生成临时表时使用的条件,它不管是on中的条件都会返回左边表的记录
2、where条件时在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表中的记录了)条件不为真的就全部过滤掉。
left join ,right join,full join不管on上的条件是否为真,都会返回left或者right表中的记录,full则具有left和right的特性的并集,inner join没有这个特殊性,条件放在on或者where中,返回的结果是相同的。
UNION
union操作符用来合并两个或者多个select语句的结果
下面新建一个apps表
mysql> create table apps(
-> id bigint(20) PRIMARY KEY,
-> app_name varchar(20),
-> url varchar(30),
-> country varchar(20)
-> );
mysql> insert into apps values(1,"QQ","http://qq.com","cn");
mysql> insert into apps values(2,"搜狐","http://souhu.com","cn");
mysql> insert into apps values(3,"bilibili","http://bilibili.com","cn");
mysql> select * from apps;
+----+----------+---------------------+---------+
| id | app_name | url | country |
+----+----------+---------------------+---------+
| 1 | QQ | http://qq.com | cn |
| 2 | 搜狐 | http://souhu.com | cn |
| 3 | bilibili | http://bilibili.com | cn |
+----+----------+---------------------+---------+
-- 查询apps和websites中的所有国家
mysql> select country from websites UNION select country from apps order by country;
+---------+
| country |
+---------+
| cn |
| jp |
| us |
+---------+
3 rows in set (0.01 sec)
union默认会去重,如果想要展示所有的,可以用UNION ALL
mysql> select country from websites UNION ALL select country from apps order by
country;
+---------+
| country |
+---------+
| cn |
| cn |
| cn |
| cn |
| cn |
| cn |
| cn |
| jp |
| us |
| us |
+---------+
10 rows in set (0.00 sec)
注意点 💁♂
在使用UNION命令的时候只能在最后使用ORDER BY命令,是将两个查询结果合并在一起的时候再进行排序
SQL约束
约束的英文名是Constraints
SQL约束用于规定表中的数据规则,如果存在违反约束的数据行为,行为会被约束终止。
约束可以在创建表时规定(通过CREATE TABLE语句),或者在创建表之后通过ALTER TABLE语句
语法
CREATE TABLE table_name
(
column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name,
column_name3 data_type(size) constraint_name,
....
);
常见的约束有如下几种
- NOT NULL——某列不能存储空值
- UNIQUE———保证某列的每行必须有一个唯一的值
- PRIMARY KEY—NOT NULL和QUNIQUE结合,保证某一列既不为空,也唯一,有助于更容易的找到表中的一个特定的记录(主键)
- FOREIGN KEY—保证一个表中的数据匹配另一个表中的值的参照完整性(外键)
- CHECK————保证列中的值符合指定的条件
- DEFAULT———规定没有给列赋值时的默认值
NOT NULL
-- 创建表时的使用方法
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255) NOT NULL,
Age int
);
-- 创建表后添加
ALTER TABLE Persons
MODIFY Age int NOT NULL;
-- 删除NOT NULL
ALTER TABLE Persons
MODIFY Age int NULL;
UNIQUE
-- 创建
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
UNIQUE (P_Id)
)
-- 创建多个约束
ALTER TABLE Persons
ADD CONSTRAINT uc_PersonID UNIQUE (P_Id,LastName);
-- 这一步操作之后相当于有了一个uc_PersonID索引
-- 撤销约束
ALTER TABLE Persons
DROP INDEX uc_PersonID
PRIMARY KEY
-- 还是以persons表为例,在初始化的时候添加主键
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (P_Id),
-- CONSTRAINT pk_PersonID PRIMARY KEY (P_Id,LastName) 多个列共同组成主键
)
-- 创建表之后的修改语法
ALTER TABLE Persons
ADD PRIMARY KEY (P_Id)
ALTER TABLE Persons
ADD CONSTRAINT pk_PersonID PRIMARY KEY (P_Id,LastName)
-- 撤销PRIMARY KEY
ALTER TABLE Persons
DROP PRIMARY KEY
POREIGN KEY
标准解释:一个表中的 FOREIGN KEY 指向另一个表中的 UNIQUE KEY(唯一约束的键)。
FOREIGN KEY可以用于预防破坏表之间的链接行为
可以防止非法数据插入外键列
-- orders创建时在“P_id”列上创建PROEIGN KEY约束
CREATE TABLE Orders
(
O_Id int NOT NULL,
OrderNo int NOT NULL,
P_Id int,
PRIMARY KEY (O_Id),
FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
)
-- 创建表之后添加
ALTER TABLE Orders
ADD FOREIGN KEY (P_Id)
REFERENCES Persons(P_Id)
-- 撤销FOREIGN KEY约束
ALTER TABLE Orders
DROP FOREIGN KEY fk_PerOrders
CHECK
-- 下面的表在创建persons的时候限制住了P_id必须大于0
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CHECK (P_Id>0),
-- CONSTRAINT chk_Person CHECK (P_Id>0 AND City='Sandnes') 定义多个约束
)
-- 如果表已经创建了
ALTER TABLE Persons
ADD CHECK (P_Id>0)
-- 撤销CHECK
ALTER TABLE Persons
DROP CHECK chk_Person
DEFAULT
default约束用于向列中插入默认值,如果没有规定其他的值,那么会将默认值添加到所有的新纪录
-- city的默认值是南京
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255) DEFAULT '南京'
)
-- 如果表已经创建好了
ALTER TABLE Persons
ALTER City SET DEFAULT 'SANDNES'
-- 撤销
ALTER TABLE Persons
ALTER City DROP DEFAULT
CREATE INDEX
CREATE INDEX语句用于在表中创建索引,在不读取整个表的情况下,索引数据库应用程序可以更快的查找数据
mysql的索引结构使用的是B+树,B+树高都比较低,时间复杂度低,每个节点只存放指针,所有的数据都在叶子结点中,查找速度快
-- 在persons表中建立一个索引
CREATE INDEX my_index ON persons(city);
-- 在persons表中建立唯一索引
CREATE UNIQUE INDEX my_index ON persons(city);
-- 在两个列上建立索引
CREATE INDEX my_index ON Persons (LastName, FirstName)
-- 撤销索引
ALTER TABLE Persons DROP INDEX my_index
ALTER TABLE
ALTER TABLE语句用来在已有表中添加、删除或者修改列
-- 在Person表中添加列
ALTER TABLE Persons
ADD Hobby varchar(20)
-- 删除列
ALTER TABLE Persons
DROP COLUMN Hobby
-- 修改列
ALTER TABLE Persons MODIFY COLUMN Hobby int(20);
AUTO INCREMENT
AUTO INCREMENT会在新纪录插入到表中时生成一个唯一的数字
-- 把id设置为自增的
CREATE TABLE Persons
(
ID int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (ID)
)
-- 设置启始值
ALTER TABLE Persons AUTO_INCREMENT=100;
-- 有了auto-increment字段之后,就不为为那个自增的列设置值了,可以像这样插入
INSERT INTO Persons (FirstName,LastName)
VALUES ('Lars','Monsen')
-- 给已经存在的列添加自增语法
ALTER TABLE Persons CHANGE ID ID bigint(20) NOT NULL AUTO_INCREMENT;
SQL函数
SQL Aggregate 函数
SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。
有用的 Aggregate 函数:
下面是access_log表
mysql> select * from access_log;
+------+---------+-------+---------------------+
| aid | site_id | count | date |
+------+---------+-------+---------------------+
| 1 | 1001 | 89 | 2020-12-28 18:22:21 |
| 2 | 1001 | 89 | 2020-12-28 18:22:30 |
| 2 | 1001 | 231 | 2020-12-28 18:22:37 |
| 2 | 1005 | 871 | 2020-12-28 18:22:49 |
| 7 | 1003 | 456 | 2020-12-28 18:23:01 |
| 8 | 1003 | 496 | 2020-12-28 18:23:10 |
| 9 | 1800 | 2131 | 2020-12-28 18:35:56 |
+------+---------+-------+---------------------+
AVG() - 返回平均值
-- 计算平均访问量
SELECT AVG(count) AS CountAverage FROM access_log;
+--------------+
| CountAverage |
+--------------+
| 623.2857 |
+--------------+
-- 选出访问量大于平均量的
mysql> SELECT site_id, count FROM access_log
-> WHERE count > (SELECT AVG(count) FROM access_log);
+---------+-------+
| site_id | count |
+---------+-------+
| 1005 | 871 |
| 1800 | 2131 |
+---------+-------+
-
COUNT() - 返回行数
-- 计算总行数 mysql> SELECT COUNT(count) AS nums FROM access_log; +------+ | nums | +------+ | 7 | +------+ -- 计算大于1000的行数 mysql> SELECT COUNT(count) AS nums FROM access_log -> WHERE count>1000; +------+ | nums | +------+ | 1 | +------+ 1 row in set (0.00 sec) -- 查询所有记录的条数 select count(*) from access_log; -- 查询websites 表中 alexa列中不为空的记录的条数 select count(alexa) from websites; -- 查询websites表中 country列中不重复的记录条数 select count(distinct country) from websites; -
FIRST() - 返回第一个记录的值
只有MS Access支持FIRST()函数 其他数据库用
mysql有类似的语法
SELECT url FROM Websites ORDER BY id ASC LIMIT 1; -
LAST() - 返回最后一个记录的值
只有 MS Access 支持 LAST() 函数
mysql中
SELECT url FROM Websites ORDER BY id DESCLIMIT 1; -
MAX() - 返回最大值
SELECT MAX(alexa) AS max_alexa FROM Websites; -
MIN() - 返回最小值
同上
-
SUM() - 返回总和
SQL Scalar 函数
SQL Scalar 函数基于输入值,返回一个单一的值。
有用的 Scalar 函数:
- UCASE() - 将某个字段转换为大写
- LCASE() - 将某个字段转换为小写
- MID() - 从某个文本字段提取字符,MySql 中使用
- SubString(字段,1,end) - 从某个文本字段提取字符
- LEN() - 返回某个文本字段的长度
- ROUND() - 对某个数值字段进行指定小数位数的四舍五入
- NOW() - 返回当前的系统日期和时间
- FORMAT() - 格式化某个字段的显示方式
sql通用数据类型
| 数据类型 | 描述 |
|---|---|
| CHARACTER(n) | 字符/字符串。固定长度 n。 |
| VARCHAR(n) 或 CHARACTER VARYING(n) | 字符/字符串。可变长度。最大长度 n。 |
| BINARY(n) | 二进制串。固定长度 n。 |
| BOOLEAN | 存储 TRUE 或 FALSE 值 |
| VARBINARY(n) 或 BINARY VARYING(n) | 二进制串。可变长度。最大长度 n。 |
| INTEGER§ | 整数值(没有小数点)。精度 p。 |
| SMALLINT | 整数值(没有小数点)。精度 5。 |
| INTEGER | 整数值(没有小数点)。精度 10。 |
| BIGINT | 整数值(没有小数点)。精度 19。 |
| DECIMAL(p,s) | 精确数值,精度 p,小数点后位数 s。例如:decimal(5,2) 是一个小数点前有 3 位数,小数点后有 2 位数的数字。 |
| NUMERIC(p,s) | 精确数值,精度 p,小数点后位数 s。(与 DECIMAL 相同) |
| FLOAT§ | 近似数值,尾数精度 p。一个采用以 10 为基数的指数计数法的浮点数。该类型的 size 参数由一个指定最小精度的单一数字组成。 |
| REAL | 近似数值,尾数精度 7。 |
| FLOAT | 近似数值,尾数精度 16。 |
| DOUBLE PRECISION | 近似数值,尾数精度 16。 |
| DATE | 存储年、月、日的值。 |
| TIME | 存储小时、分、秒的值。 |
| TIMESTAMP | 存储年、月、日、小时、分、秒的值。 |
| INTERVAL | 由一些整数字段组成,代表一段时间,取决于区间的类型。 |
| ARRAY | 元素的固定长度的有序集合 |
| MULTISET | 元素的可变长度的无序集合 |
| XML | 存储 XML 数据 |
MYSQL的数据类型
| 数据类型 | 描述 |
|---|---|
| CHAR(size) | 保存固定长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的长度。最多 255 个字符。 |
| VARCHAR(size) | 保存可变长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的最大长度。最多 255 个字符。**注释:**如果值的长度大于 255,则被转换为 TEXT 类型。 |
| TINYTEXT | 存放最大长度为 255 个字符的字符串。 |
| TEXT | 存放最大长度为 65,535 个字符的字符串。 |
| BLOB | 用于 BLOBs(Binary Large OBjects)。存放最多 65,535 字节的数据。 |
| MEDIUMTEXT | 存放最大长度为 16,777,215 个字符的字符串。 |
| MEDIUMBLOB | 用于 BLOBs(Binary Large OBjects)。存放最多 16,777,215 字节的数据。 |
| LONGTEXT | 存放最大长度为 4,294,967,295 个字符的字符串。 |
| LONGBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 4,294,967,295 字节的数据。 |
| ENUM(x,y,z,etc.) | 允许您输入可能值的列表。可以在 ENUM 列表中列出最大 65535 个值。如果列表中不存在插入的值,则插入空值。**注释:**这些值是按照您输入的顺序排序的。可以按照此格式输入可能的值: ENUM(‘X’,‘Y’,‘Z’) |
| SET | 与 ENUM 类似,不同的是,SET 最多只能包含 64 个列表项且 SET 可存储一个以上的选择。 |














 1792
1792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









