






沉寂了这么久,该总结下近期工作了。近期主要工作是毕业设计,多标记分类算法。我选择用SVM(Support Vector Machine)作为核心算法。其实之所以选择这个毕业设计课题,是因为在以往用python做网页爬虫的过程中,遇到验证码识别问题,用穷举法,对于稍微复杂的,位数高,包含字母的在时间上不具有可行性,更有些网站对一个验证码不能重复尝试的问题,无法解决。最好的方法是识别。
本程序用python语言,PIL图像处理模块,svmlight作为分类器,以前用过的一个测试网站作为验证码图片来源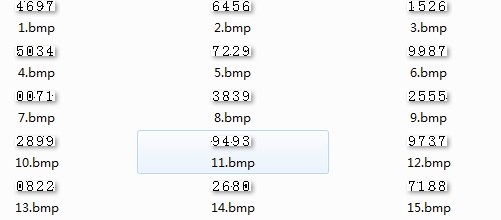 (图片数字规整,位置很正,只是有些噪声点,所以比较简单)下面是步骤:
(图片数字规整,位置很正,只是有些噪声点,所以比较简单)下面是步骤:
1、获取图片:
#getpic.py
#python ver 2.7
__author__ = 'Directorli'
import urllib
def getone(filename):
pic=urllib.urlopen("http://localhost/getcode.asp")
file=open("bmp\\%s.bmp"%filename,"wb")
file.write(pic.read())
for i in range(100):
getone(i)
得到一百张验证码图片
2、 对图片进行切割,每个图片切成四个单独的数字
#cutpic.py
#python ver 2.7
__author__ = 'Directorli'
import Image
def cut(x,y,ifile,ofile):
im = Image.open('bmp\\'+ifile)
box = (x-10,0,x,10)
xim = im.crop(box)
xim.save('bmp\\cut\\'+ofile)
o=0
for i in range(400):
for j in range(1,5):
cut(10*j,10*j,str(i)+".bmp",str(o)+".bmp")
o = o + 1
 如图
如图
3、 手工分拣,制作训练集:
4、程序重命名
#chname.py
#python ver 2.7
__author__ = 'Directorli'
import os
path="bmp\\cut\\"
a = os.listdir(path)
for b in a:
pathb = path + b +"\\"
c = os.listdir(pathb)
n = 0
for d in c:
os.rename(pathb+d,pathb+str(n)+b+".bmp")
n = n + 1

名字最后一位就是数字本身
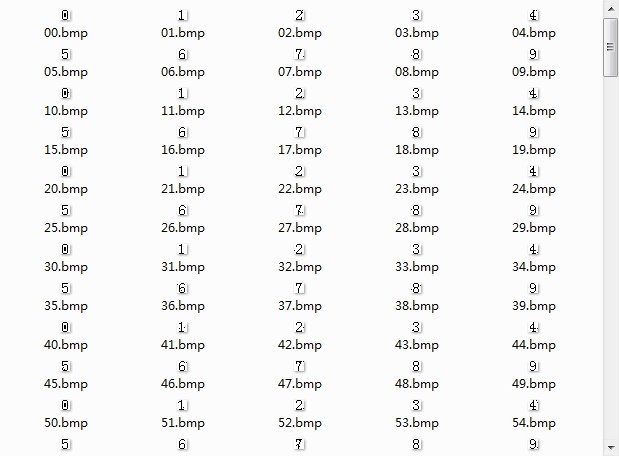
5、建立训练集(400个):
6、训练svm,生成 模式
#train.py
#python ver 2.7
__author__ = 'Directorli'
import Image
import os
import svmlight
def binary(x,y,file):
im = Image.open(file)
Lim = im.convert('L')
threshold = 80
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
# convert to binary image by the table
bim = Lim.point(table, '1')
bdata=bim.load()
out=""
for a in range(y):
for b in range(x):
out = out + str(bdata[b,a])
#out = out + '\n'
return out
def totrain(x):
path = "bmp\\cut\\all\\"
filelist = os.listdir(path)
#print filelist
f=[]
for one in filelist:
# print path[-5]
# print binary(10,10,path)
a = binary(10,10,path+one)
d=[]
c = 1
for b in a:
d.append((c,int(b)))
c = c + 1
# print d
if str(x) == one[-5]:
e = (1,d)
else:
e = (-1,d)
f.append(e)
#print e
#print f
return f
def trainall():
for i in range(10):
training_data = totrain(i) #train set
#test_data =test #test set
# train a model based on the data
model = svmlight.learn(training_data, type='classification', verbosity=0)
svmlight.write_model(model, 'model'+str(i)) #write model
#model=svmlight.read_model("my_model.dat") #read model
#predictions = svmlight.classify(model, test_data)
生成的知识模式(model 0~9):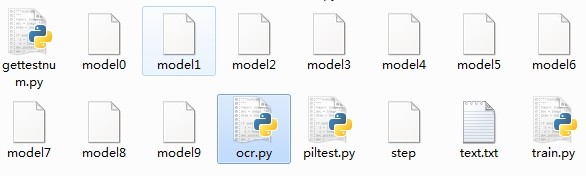
7、再获取一定数量的验证码图片试着识别:
因为图片太规整,识别率太高(100%) ,所以对图片手动加些处理
以下是机器命名的,识别率任然算高
上代码:
#ocr.py
#python ver 2.7
__author__ = 'Directorli'
import Image
import svmlight
def binary(x,file):
im = Image.open(file)
Lim = im.convert('L')
threshold = 80
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
# convert to binary image by the table
bim = Lim.point(table, '1')
bdata=bim.load()
out=""
for a in range(10):
for b in range(x*10,x*10+10):
out = out + str(bdata[b,a])
#out = out + '\n'
return out
def chformat(x):
f=[]
d=[]
c = 1
for b in x:
d.append((c,int(b)))
c = c + 1
e = (1,d)
f.append(e)
return f
def ocr(filename):
result=""
for num in range(4):
t = binary(num,filename)
test = chformat(t)
for i in range(10):
model=svmlight.read_model("model"+str(i)) #read model
prediction = svmlight.classify(model,test)
#print prediction
if prediction[0] >0:
#print i
result = result + str(i)
print(result)
return result
#ocr("code.bmp")
import os
allfile = os.listdir("test\\")
for a in allfile:
b = str(ocr("test\\"+a))
os.rename("test\\"+a,"test\\"+b+".bmp")














 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









