






前面已经提过最基本的三种排序(选择,插入,冒泡),请点击这里,下面我再来说说希尔排序。
希尔排序其实属于插入算法,但又是优化的插入算法,比之前算法有了较大的改进。
希尔排序的基本思想:先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。该方法实质上是一种分组插入方法。
下面我们看下图示:
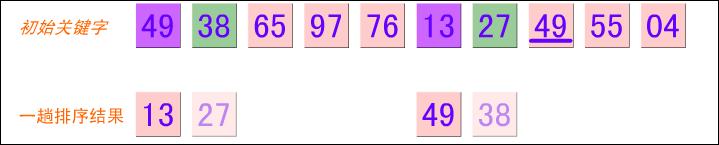
然后上面图示的第一趟排序后的结果为 13 27 49 55 04 49 38 65 97 76 (第一趟把数字分成5个子序列)
然后再看下面的图示:
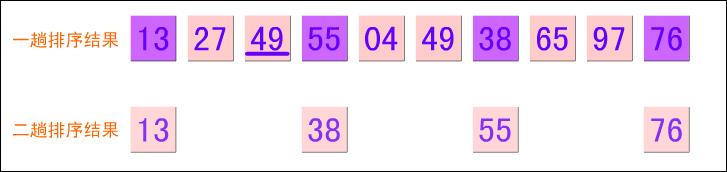
第二趟的结果为:13 04 19 38 27 49 55 65 9776 (第二趟把数列分成3个子序列)
最后再进行一下直接插入排序,就这样,shell排序就over了。
在这我们看看希尔排序的优势在哪:它每次都把整个数列分成有序的n份,然后再插入每一趟排序将使得数列部分有序,从而使得以后的插入排序很快找到插入位置。
另外最重要的是:Shell排序算法依赖一种称之为“排序增量”的数列,不同的增量将导致不同的效率。
希尔排序的分析是一个复杂度问题吗因为它的时间是所取“增量”序列的函数,目前为止还没有人求得一种最好的增量的序列,所以在这就不研究时间复杂度了。
看面看下算法代码:
- #include <stdio.h>
- void ShellInsert(int*a,int inc,int len)
- {
- for (int i=inc;i<len;i+=inc)
- {
- int j=i,x=a[i];
- while (j>0 && a[j-inc]>x)
- {
- a[j]=a[j-inc],j-=inc;
- }
- a[j]=x;
- }
- }
- int main(void)
- {
- int a[10];
- while(true)
- {
- for(int n=0;n<10;n++)
- {
- printf("/n第 %d 数:",(n+1));
- scanf("%d",&a[n]);
- }
- ShellInsert(a,4,10);
- for(int i=0;i<10;i++)//输出排序后的数
- {
- printf("%d ",a[i]);
- }
- }
- }
原文链接: http://blog.csdn.net/crazyjixiang/article/details/6465833















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









