






-
查看cassandra集群状态的命令
nodetool status
-
修复每台机器的keyspace
nodetool repair -h ip_address_of_node keyspace_name
-
如果要剔除的cassandra数据库的状态为UN,表示数据库为正常状态可以执行以下命令
nodetool decommission (此命令同样适用于cassandra缩容,执行此命令在某台cassandra数据库,此数据库将退出当前cassandra集群,需要注意的是此命令执行时间过长,需要在tmux或者使用nohup的方式执行)
-
如果要剔除的cassandra数据库的状态为DN,可以直接执行以下命令将问题节点剔除
nodetool removenode 41528794-6454-4cb3-9e16-6f8b7961cc61
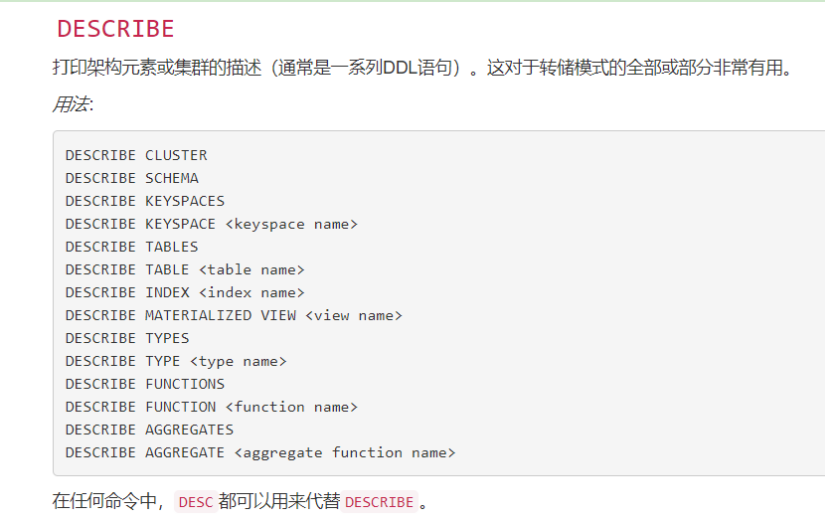
- 打印集群名称
Decs cluster;
- cassandra数据复制可以从任意相邻节点复制数据,
- Cassandra主要组成部分:节点,数据中心(相关节点的集合),集群,提交日志(commit log)存储表(Mem-table),SSTable(当内容达到阀值时,它从内存表刷新数据的磁盘文件)Bloom filter(过滤器)
- Cassandra写操作时,本地写入commit log,同时数据存储到内存表中,然后数据写入SStable文件,所有写入在中个集群中自动分区和复制。
- Cassandra读操作是从内存表获取值,并检查bloom过滤器以找到所需数据的SStable
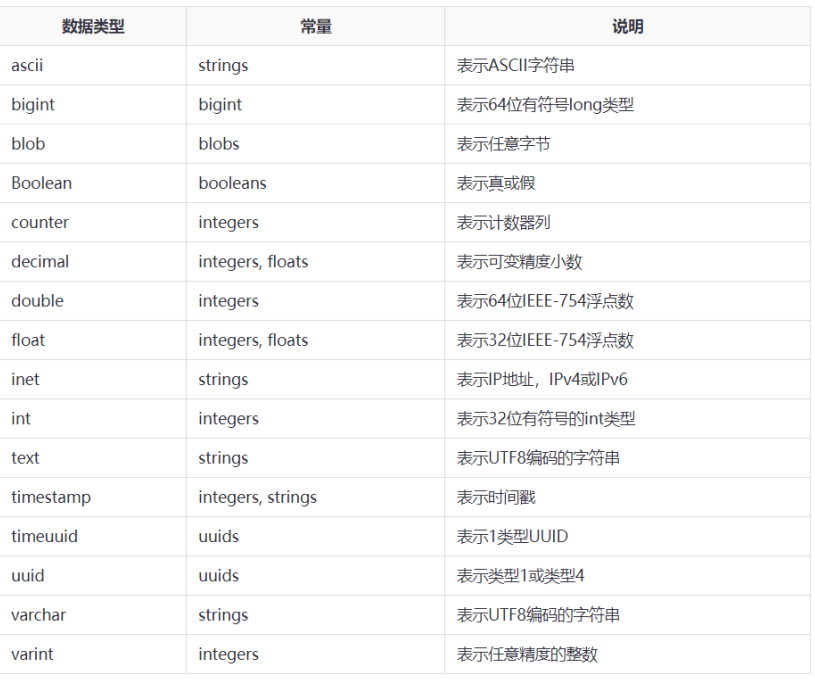
Cassandra支持不同类型的数据类型。 下面来看看看下表中的不同数据类型:
- Cassandra自动数据到期,提供自动过期功能,数据插入时,以秒为单位指定ttl值,ttl值后数据将被自动删除
- 创建键空间(键空间相当于数据库)
CREATE KEYSPACE <identifier> WITH <propertite>
例:CREATE KEYSPACE XX WITH replication = {‘class’:’SimpleStrategy’,’replication_factor’ : 3};
- 查看检查键空间是否存在
Cqlsh> DESCRIBE XX;
- 查看所有键空间
DESCRIBE keyspace;
- 使用键空间
USE XX;
- 修改键空间
ALTER KEYSPACE <IDENTIFIER> WITH <properties>
例:
ALTER KEYSPACE "KeySpace Name" WITH replication = {'class': 'Strategy name', 'replication_factor' : 'No.Of replicas'};
改变Cassandra中的Keyspace的要点
- Keyspace Name: Cassandra中的键名称不能更改。
- Strategy Name: 可以通过使用新的策略名称来更改战略名称。
- Replication Factor : 可以通过使用新的复制因子来更改复制因子。
- DURABLE_WRITES : DURABLE_WRITES值可以通过指定其值true / false来更改。 默认情况下为true。 如果设置为false,则不会将更新写入提交日志,反之亦然。
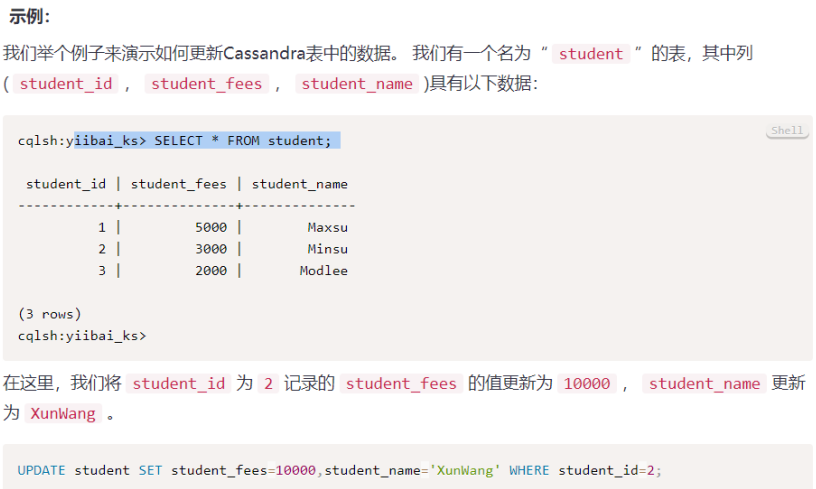
实例:
我们来举个例子来说明“更改键空间”。 这将会将KeyCenter策略从“SimpleStrategy”更改为“NetworkTopologyStrategy”,将DataCenter1的复制因子从3更改为1。
ALTER KEYSPACE yiibai_ks WITH replication = {'class':'NetworkTopologyStrategy', 'replication_factor' : 1};
- 删除键空间
DROP KEYSPACE xx;
验证是否还存在:use xx;
- 创建表
CREATE TABLE student(
student_id int PRIMARY KEY,
student_name text,
student_city text,
student_fees varint,
student_phone varint );
- 更改表,添加一列
ALTER TABLE table name ADD new column datatype;
例:添加一个名为student_email的文本数据类型
ALTER TABLE student ADD student_email text;
- 删除一列
ALTER table name DROP column name;
例:ALTER TABLE student DROP student_email;
如果要删除多个列,请使用“,”分隔列名。
ALTER TABLE student DROP (student_fees,student_phone);
- 删除表
DROP TABLE table name
DROP TABLE students;
验证表是否被删除
DESCRIBE COLUMNFAMILIES;
- 截断表( 清空表)
TRUNCATE student;
验证
Select * from student;
- 创建索引
CREATE INDEX命令用于在用户指定的列上创建一个索引。 如果您选择索引的列已存在数据,则Cassandra会在“create index”语句执行后在指定数据列上创建索引。
语法:create index <identifier> ON <tablename>
创建索引的规则
- 由于主键已编入索引,因此无法在主键上创建索引。
- 在Cassandra中,不支持集合索引。
- 没有对列进行索引,Cassandra无法过滤该列,除非它是主键。
执行以下命令创建一个索引 -
CREATE INDEX name ON student (student_name);
执行describe student;查看详细情况
- 删除索引
DROP INDEX <identifier>
或者DROP index IF EXISTS keyspaceName.IndexName
删除索引的规则
- 如果索引不存在,它将返回错误,除非您使用IF EXISTS,否则不返回任何操作。
- 在创建索引期间,您必须使用索引名称指定keyspace名称,否则将当前键空间中的索引删除。
创建索引:create index student_name_index on student(student_name);
删除索引
例:
Use yiibai_ks;
DROP index IF EXISTS yiibai_ks.student_name_index;
- Cassandra 批量处理
语法
BEGIN BATCH <insert-stmt>/ <update-stmt>/ <delete-stmt> APPLY BATCH
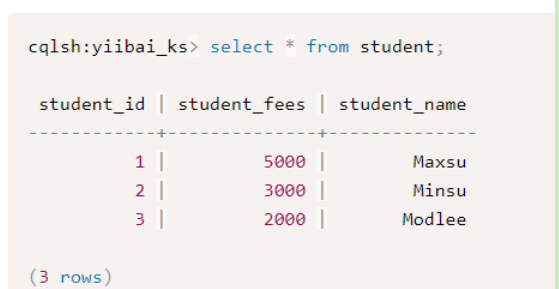
例:## 创建表
CREATE TABLE student( student_id int PRIMARY KEY, student_name text, student_fees varint );
## 插入数据
INSERT INTO student (student_id, student_fees, student_name) VALUES(1,5000, 'Maxsu');
INSERT INTO student (student_id, student_fees, student_name) VALUES(2,3000, 'Minsu');
INSERT INTO student (student_id, student_fees, student_name) VALUES(3, 2000, 'Modlee');
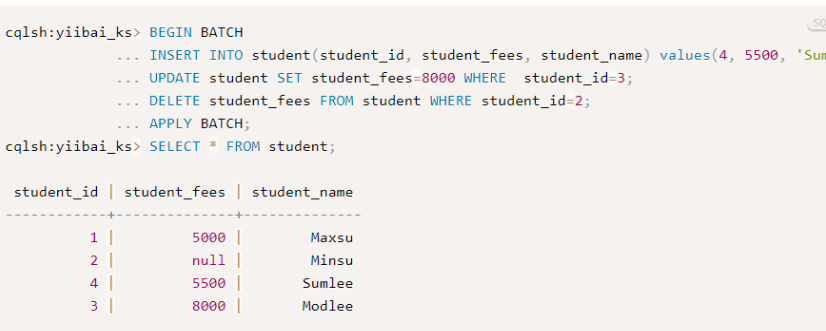
执行BATCH命令 -
BEGIN BATCH
INSERT INTO student(student_id, student_fees, student_name) values(4, 5500, Sumlee);
UPDATE student SET student_fees=8000 WHERE student_id=3;
DELETE student_fees FROM student WHERE student_id=2;
APPLY BATCH;
- 插入数据
语法:INSERT INTO <tablename>
(<column1 name>, <column2 name>....) VALUES (<value1>, <value2>....) USING <option>
例:
## 创建表
CREATE TABLE student( student_id int PRIMARY KEY, student_name text, student_fees varint );
## 向表插入数据
INSERT INTO student (student_id, student_fees, student_name) VALUES(1,5000, 'Maxsu'); INSERT INTO student (student_id, student_fees, student_name) VALUES(2,3000, 'Minsu'); INSERT INTO student (student_id, student_fees, student_name) VALUES(3, 2000, 'Modlee');
- 读取数据
Select * from student;
读取特定列
Select student_id from student;
使用where子句
注意:WHERE子句只能在作为主键的一部分的列,或者在其上具有辅助索引上使用。
Student_id 是主键
Select * form student WHERE student_id=2;
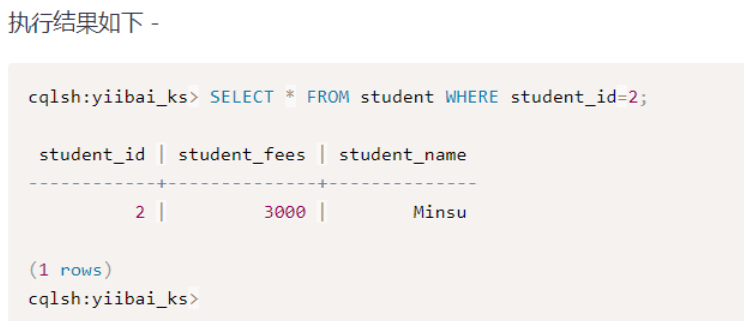
- 更新数据
语法:
UPDATE <tablename> SET <column name> = <new value> <column name> = <value>.... WHERE <condition>
SQL
又或者 -
Update KeyspaceName.TableName Set ColumnName1=new Column1Value,
ColumnName2=new Column2Value,
ColumnName3=new Column3Value,
.
.
. Where ColumnName=ColumnValue
例:
- 删除数据
语法:DELETE FROM <identifier> WHERE <condition>;
删除整行:
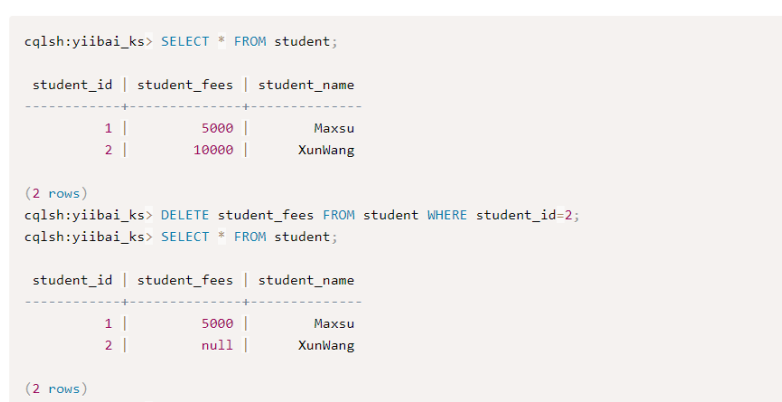
删除student_id 为3
Delete from student where student_id=3;
删除一个特定列名
删除student_id为2的记录中的student_fees列中的值。
DELETE student_fees FROM student WHERE student_id=2;
- Cassandra 查看hugegraph数据库
Use hugegraph;
Describe tables 列出所有表
- 补充:nodetool cfstats显示了每个表和keyspace的统计数据
- nodetool cfhistograms提供了表的统计数据,包括读写延迟,行大小,列的数量和SSTable的数量。
- nodetool netstats提供了网络连接操作的统计数据。
- nodetool tpstats提供了如active、pending以及完成的任务等Cassandra操作的每个阶段的状态。
- Cassandra 删除一个节点
第一步:先每个机器都修复下每个keyspace
nodetool repair -h ip_address_of_node keyspace_name
第二步:如果你要删除的机器是UP状态的机器,没有宕机
你可以在要删除的机器上执行 nodetool decommission. 就直接结束了,否则继续:
第三步:如果你的机器是宕机的。
你要先用在一个活着的机器上执行nodetool status 命令,获取宕机节点的id
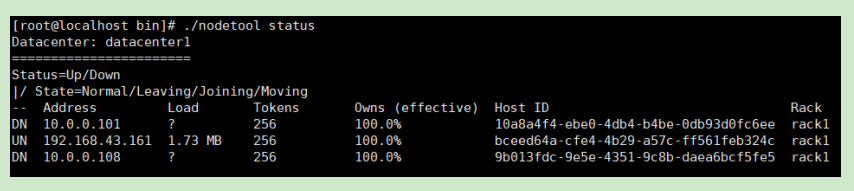
第四步: 在活的节点上执行删除操作
./nodetool removenode 10a8a4f4-ebe0-4db4-b4be-0db93d0fc6ee
它会自己均衡数据,这里就直接结束了,否则继续。
第五步:再次使用nodetool status查看节点是否删除成功

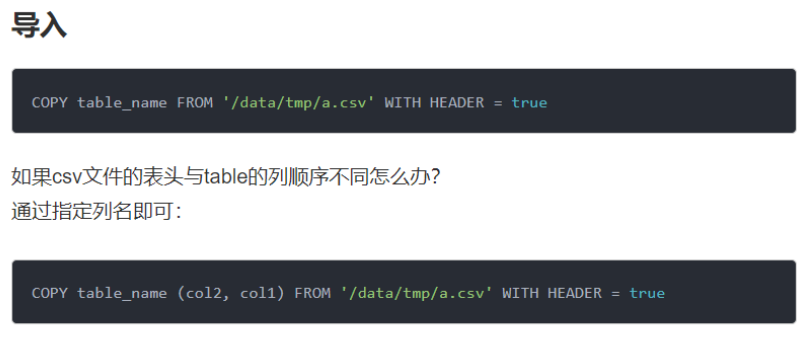
- 导出/ 导入表
Desc keyspaces;
Desc tables;
Copy table_name to ‘path’ with header = true;
- 在cassandra的bin目录下提供了一个sstableloader工具,这个工具专门用于把一个表的sstable文件导入到一个新的集群中。
假设你的表是mykeyspace.mytable。你的数据存一个10个节点组成的集群中,每个几点的数据都存在/disk/data1和/disk/data2目录下。
假设你的新集群的一个访问地址是IP, 先在新集群建离相同名字的keyspace和表结构。
接下来你只要在老集群的每个节点执行下面的命令:
bin/sstableloader -d IP -u cassandra -pw cassandra -t 100 /disk/data1/mykeyspace/mytable
bin/sstableloader -d IP -u cassandra -pw cassandra -t 100 /disk/data2/mykeyspace/mytable
其中-u是 用户名 -pw是密码 -t是限制流量100M/bps
等所有节点执行完毕,你的表数据就成功导入到了新的集群中,当然只要你的机器io和网络条件允许,你可以多个节点并发执行。
cassandra 备份
生成快照:
nodetool -h 服务器ip -p 端口号 snapshots 数据库名 #全库快照
nodetool -h 服务器ip -p 端口号 snapshots -t 快照名称 -kt 数据库名.表名 #某个表快照
快照路径:table-uuid/snapshots/snapshotsname(/stronge/cassandra/data/hugegraph/index_labels-df733680bcd011e9920ebf22c41dab22/snapshots)
删除快照文件
nodetool -h localhost -p 7199 clearsnapshot
要删除单个快照,请使用快照名称运行clearsnapshot命令
nodetool clearsnapshot -t <snapshot_name> </snapshot_name>
启用增量备份
启用增量备份(默认情况下禁用)时,Cassandra会将每个可刷新表的SSTable映射到keyspace数据目录下的备份目录。 这允许在不传输整个快照的情况下将备份存储在异地。 而且,增量备份与快照相结合,可以提供可靠的最新备份机制。 压实的SSTables不会在/backups中创建映射文件,因为这些SSTables不包含任何尚未备份的数据。 一个时间点的快照,加上所有的增量备份和提交日志,形成一个完整的备份。
与快照一样,Cassandra不会自动清除增量备份文件。建议在每次创建新快照时设置一个进程来清除增量备份文件。
编辑集群中每个节点上的cassandra.yaml配置文件,并将incremental_backups的值更改为true。
查看数据库表情况
./nodetool listsnapshots
数据备份恢复过程:
删除表数据
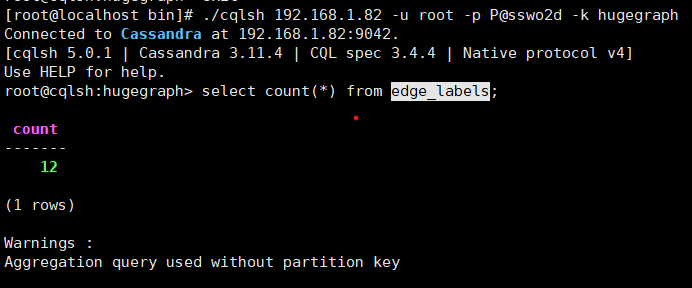
查询表中数据
select count(*) from edge_labels;
cqlsh:hugegraph> truncate table edge_labels;
#cassandra 在truncate table的时候会自动创建一个截断表的快照,表目录下的文件除了backups snapshots两个目录,其他都会被删除,删除*.db 文件
执行:查看nodetool listsnapshots
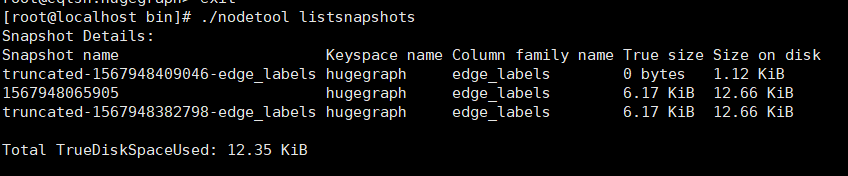
复制快照文件
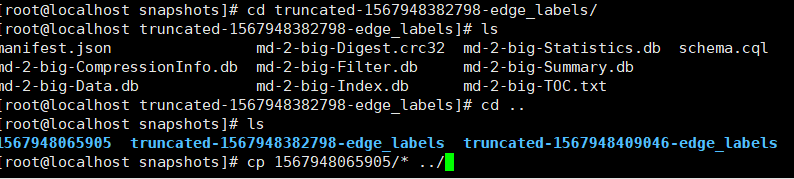
加权限:chown -R cassandra.cassandra *
恢复数据:
nodetool refresh --hugegraph edge_labels
查看:./cqlsh 192.168.1.82 -u root -p P@sswo2d -k hugegraph
select count(*) from edge_labels;
Cassandra 导出数据库及表结构文件,恢复数据库
导出
./cqlsh 192.168.1.82 -e 'desc keyspace hugegraph' > hugegraph.cql
导入
利用导出的数据库文件还原服务器上的数据库
cqlsh 10.200.250.190(server ip) -f hugegraph.cql(db's file)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









