







 本文介绍了哈夫曼树的概念、用途以及如何构造哈夫曼树。通过给定权值构建哈夫曼树的过程包括:由每个权值构建单节点二叉树,选取最小权值树组合成新树,重复此过程直至只剩一棵树。此外,还展示了用代码实现哈夫曼树的示例,用于统计字符个数并生成字符编码。
本文介绍了哈夫曼树的概念、用途以及如何构造哈夫曼树。通过给定权值构建哈夫曼树的过程包括:由每个权值构建单节点二叉树,选取最小权值树组合成新树,重复此过程直至只剩一棵树。此外,还展示了用代码实现哈夫曼树的示例,用于统计字符个数并生成字符编码。
一.什么是哈夫曼树
基本概念
节点之间的路径:一个结点到另一个结点,所经过节点的结点序列。
结点之间的路径长度:结点之间路径上的分支数(边),如汽车到下一站的路径长度为1。
树的路径长度:从根结点到每个叶子结点的路径长度之和。
带权路径: 路径上加上的实际意义 。如汽车到下一站的距离我们叫做权值
树的带权路经长度: 每个叶子结点到根的路径长度*权值 之和,记作WPL。还是汽车的例子,汽车到达天津有2条路 可以走。第一条路经过3个站,每个站相距13km。第二条有2个站,每个站相距18km。那么有距离的路我们叫做带权路径。根结点为天津的树,那么第一条路带权路径为 3*13 = 39,第二条为2*18。树的带权路径WPL 3*13+2*18.
哈夫曼树: 重点来了,什么是哈夫曼树呢。二叉树是n个结点的结合,它的度(所有孩子个数的最大值)小于等于2。n个结点构成一个二叉树有许多方法。使二叉树的带权路径最小的树 ,我们叫做哈夫曼树。
二.哈夫曼树有什么用
介绍了这么多概念,不知道它有什么用,让初学者感觉数据结构没什么劲。哈夫曼树主要用在数据的压缩如JPEG格式图片,在通信中我们可以先对发送的数据进行哈夫曼编码压缩数据提高传输速度。查询优化 在工作中我们我们身边放许多工具,由于空间限制我们不能把所有工具放在我们最容易拿到的地方,所有我们把使用频率最高的工具放在最容易的位置。同样的道理在查询的时候我们把查询频率最高的数据建立索引,这些都是使用了哈夫曼算法的思想。
三.怎么构造哈夫曼树
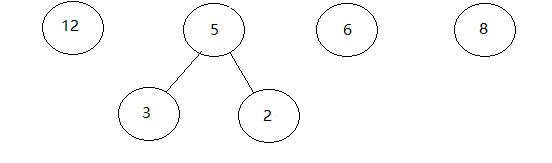
给定权值为12 3 6 8 2 如果构造其哈夫曼树
1.给定n个权值{w1,w2,w3…..,wn}构成 n棵二叉树的集合F={T1,T2,T3…..Tn}, 其中每棵树只有权值为Wi的根节点。
构成的二叉树为

2.在F中选取权值最小的两棵树作为 左子树和右子树 构成新的二叉树根的权值为两棵树之和
3.将前两棵树从F删除 加入新树
4.重复2和3直到只剩一棵树
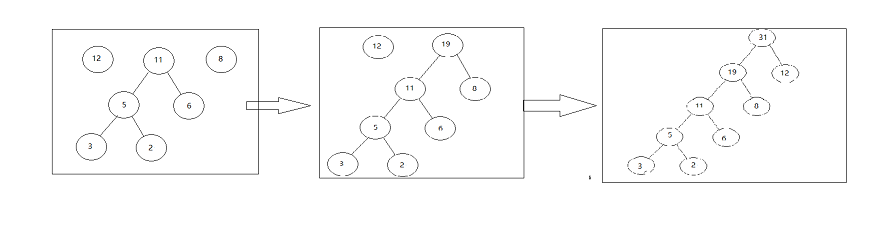
三.代码实现哈夫曼树
程序功能输入一串字符,统计字符个数,并把字符个数作为权值构造一棵哈夫曼树,求出字符的编码
程序效果图
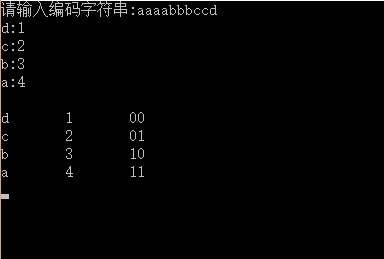
1.代码
//头文件
//为了学习 我使用链表来实现
//从树种找出权值最小的两个树 我先对树排序 取最小的两棵
//新的树先和最后一棵树 比较 找到合适位置进行插入 也就是插入排序
#include <stdio.h>
#define STACKSIZE 20 //栈的大小
typedef struct char_table {
char ch; //统计的字符
int count; //字符出现的次数
struct char_table * next; //指向下一个字符表指针
}CharNode;
typedef struct
{
int weight; //结点权值
int parent; //节点指向父节点的指针
char ch; //叶子节点的字符
int lchirld, rchirld; //指向结点的左右孩子
}HTNode,*HuffmanTree;
typedef struct stack{
int data[STACKSIZE]; //给栈分配内存
int top; //栈顶
}Stack1;
void InitStack1(Stack1*); //栈的初始化
int IsEmptyStack1(Stack1*); //判断栈是否为空
void Push1(int, Stack1*s); //入栈操作
int Pull1(Stack1*s); //出栈操作
CharNode* CountChar(char *); //统计字符个数
HuffmanTree HuffManEncodeing(CharNode* table);  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









