







Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
本文简单介绍了table和SQL API在执行、优化器、planner和sql client几方面的配置属性以及以java代码示例性的演示属性的配置方式。
本文依赖kafka集群能正常使用。
本文分为6个部分,即maven依赖、概述、执行配置、优化器配置、planner配置、sql client配置和示例。
本文的示例是在Flink 1.17版本中运行。
一、Table 和 SQL API 的配置
Table 和 SQL API 的默认配置能够确保结果准确,同时也提供可接受的性能。
根据 Table 程序的需求,可能需要调整特定的参数用于优化。例如,无界流程序可能需要保证所需的状态是有限的(请参阅 15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置).
1、概览
当实例化一个 TableEnvironment 时,可以使用 EnvironmentSettings 来传递用于当前会话的所期望的配置项 —— 传递一个 Configuration 对象到 EnvironmentSettings。
此外,在每个 TableEnvironment 中,TableConfig 提供用于当前会话的配置项。
对于常见或者重要的配置项,TableConfig 提供带有详细注释的 getters 和 setters 方法。
对于更加高级的配置,用户可以直接访问底层的 key-value 配置项。以下章节列举了所有可用于调整 Flink Table 和 SQL API 程序的配置项。
因为配置项会在执行操作的不同时间点被读取,所以推荐在实例化 TableEnvironment 后尽早地设置配置项。
2、简单示例(java和SQL Client)
1)、maven依赖
<properties>
<encoding>UTF-8</encoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- flink连接器 -->
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
2)、示例代码及运行结果
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.lit;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableConfig;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
public class TestTableAndSQLConfigurationDemo {
final static List<User> userList = Arrays.asList(
new User(1L, "alan", 18, 1698742358391L),
new User(2L, "alan", 19, 1698742359396L),
new User(3L, "alan", 25, 1698742360407L),
new User(4L, "alanchan", 28, 1698742361409L),
new User(5L, "alanchan", 29, 1698742362424L)
);
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class User {
private long id;
private String name;
private int balance;
private Long rowtime;
}
public static void testConfiguration() throws Exception {
// instantiate table environment
Configuration configuration = new Configuration();
// set low-level key-value options
configuration.setString("table.exec.mini-batch.enabled", "true");
configuration.setString("table.exec.mini-batch.allow-latency", "5 s");
configuration.setString("table.exec.mini-batch.size", "5000");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().withConfiguration(configuration).build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
// access flink configuration after table environment instantiation
TableConfig tableConfig = tenv.getConfig();
// set low-level key-value options
tableConfig.set("table.exec.mini-batch.enabled", "true");
tableConfig.set("table.exec.mini-batch.allow-latency", "5 s");
tableConfig.set("table.exec.mini-batch.size", "5000");
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
//按属性、时间窗口分组后的互异(互不相同、去重)聚合
Table groupByWindowResult = usersTable
.window(Tumble
.over(lit(5).minutes())
.on($("rowtime"))
.as("w")
)
.groupBy($("name"), $("w"))
.select($("name"), $("balance").sum().distinct().as("sum_balance"));
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(groupByWindowResult, Row.class);
result2DS.print("result2DS:");
// result2DS::2> (true,+I[alan, 62])
// result2DS::16> (true,+I[alanchan, 57])
//使用分组窗口结合单个或者多个分组键对表进行分组和聚合。
Table result = usersTable
.window(Tumble.over(lit(5).minutes()).on($("rowtime")).as("w")) // 定义窗口
.groupBy($("name"), $("w")) // 按窗口和键分组
// 访问窗口属性并聚合
.select(
$("name"),
$("w").start(),
$("w").end(),
$("w").rowtime(),
$("balance").sum().as("sum(balance)")
);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print("resultDS:");
// resultDS::16> (true,+I[alanchan, 2023-10-31T08:50, 2023-10-31T08:55, 2023-10-31T08:54:59.999, 57])
// resultDS::2> (true,+I[alan, 2023-10-31T08:50, 2023-10-31T08:55, 2023-10-31T08:54:59.999, 62])
env.execute();
}
public static void main(String[] args) throws Exception {
testConfiguration();
}
}
3)、SQL Client示例
该部分的配置选项在文章 :23、Flink 的table api与sql之流式聚合(性能调优)有说明。
SET 'table.exec.mini-batch.enabled' = 'true';
SET 'table.exec.mini-batch.allow-latency' = '5s';
SET 'table.exec.mini-batch.size' = '5000';
Flink SQL> SET 'table.exec.mini-batch.enabled' = 'true';
[INFO] Execute statement succeed.
Flink SQL> SET 'table.exec.mini-batch.allow-latency' = '5s';
[INFO] Execute statement succeed.
Flink SQL> SET 'table.exec.mini-batch.size' = '5000';
[INFO] Execute statement succeed.
3、执行配置
以下选项可用于优化查询执行的性能。
本选项采用了中英文对照的方式,避免翻译的不准确。
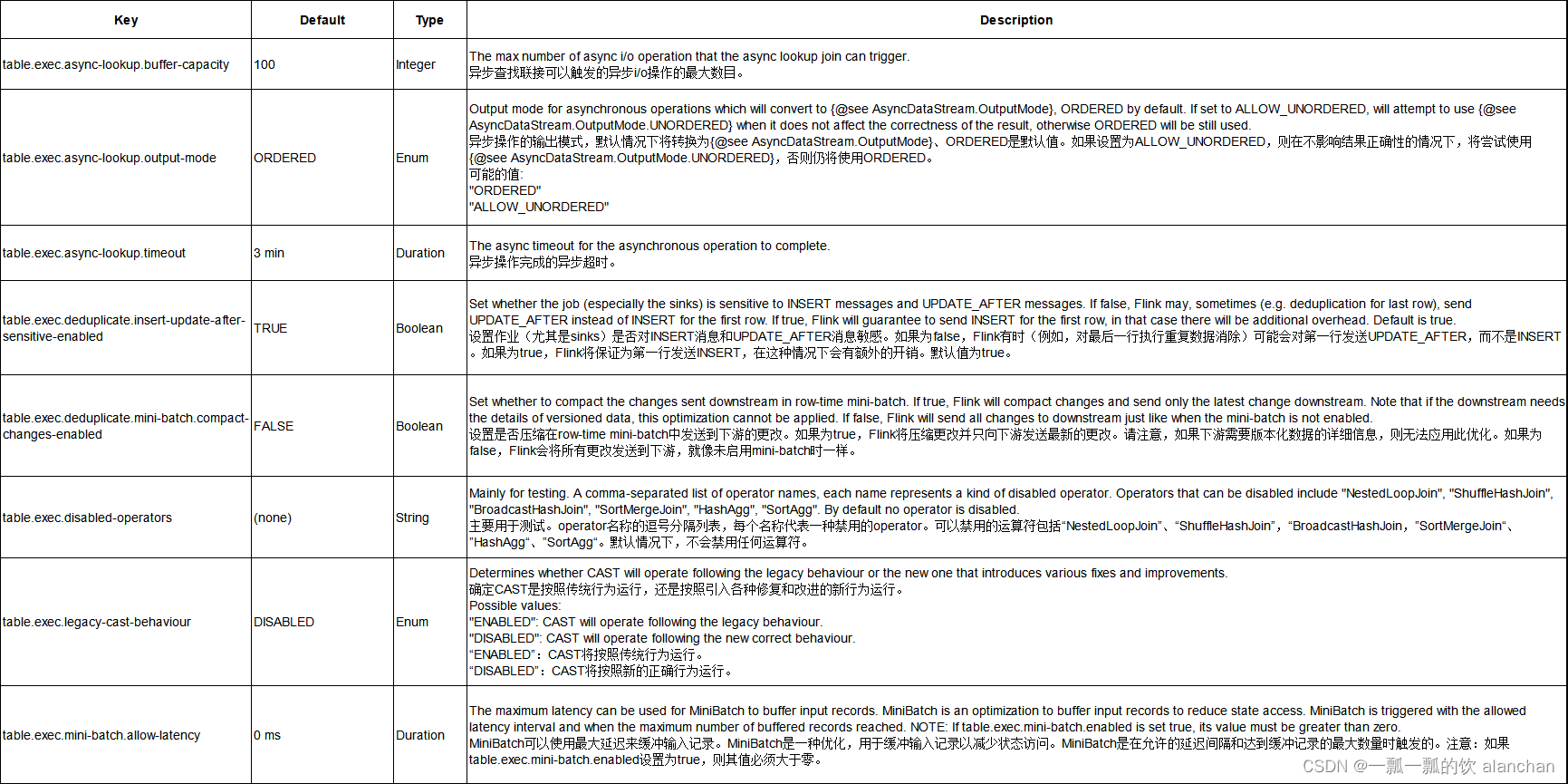

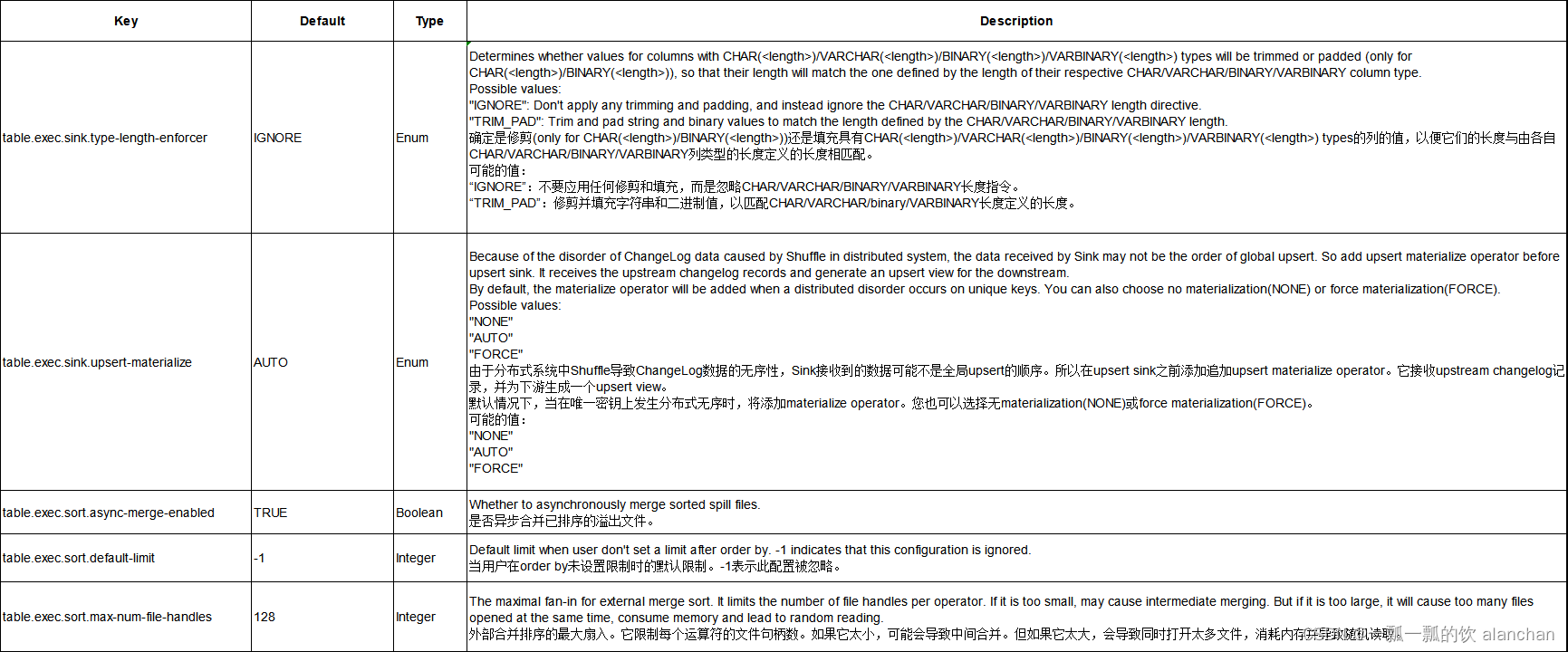


4、优化器配置
以下配置可以用于调整查询优化器的行为以获得更好的执行计划。
有些优化属性是流批都可以用的,有些用于流式,有些用于批处理。在default中没有特别说明的是流批均可,如果标明了则表示只适用于流或批。
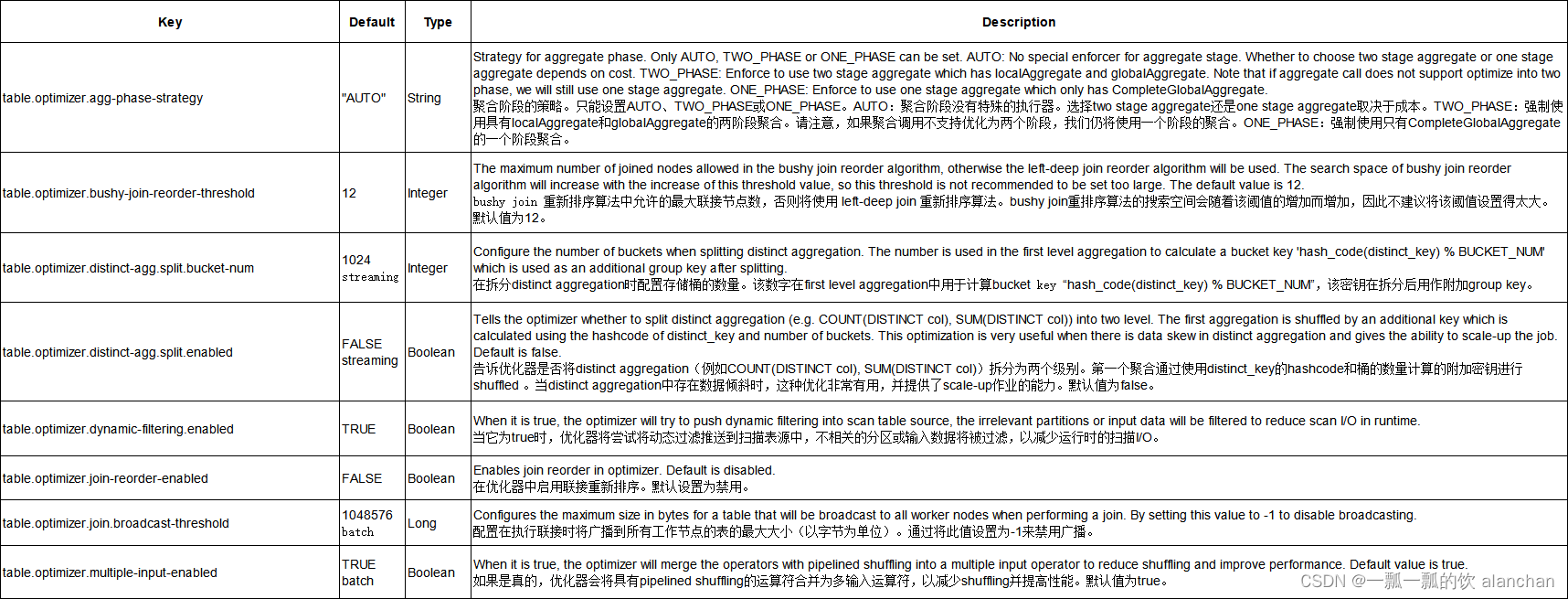
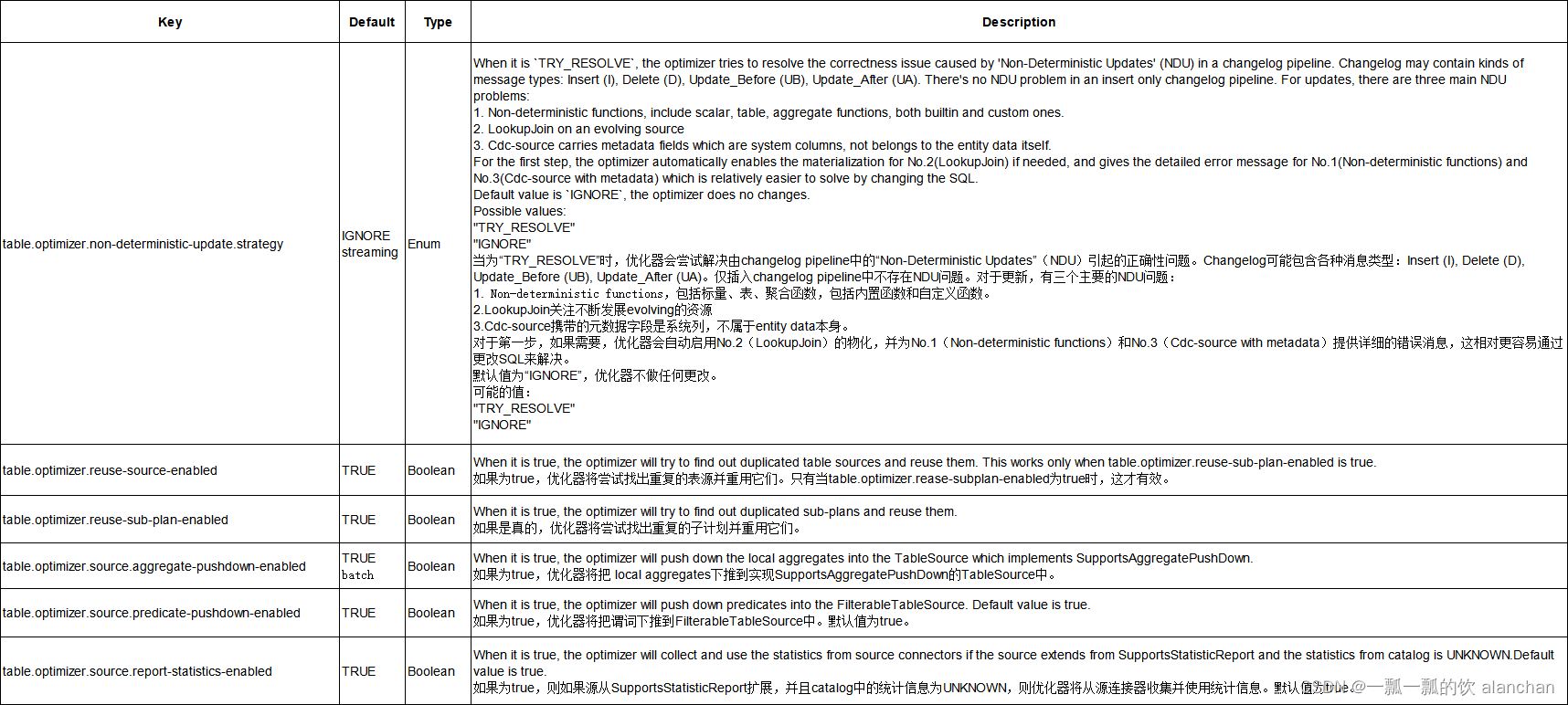
5、Planner 配置
以下配置可以用于调整 planner 的行为。
有些配置属性是流批都可以用的,有些用于流式,有些用于批处理。在default中没有特别说明的是流批均可,如果标明了则表示只适用于流或批。


6、SQL Client 配置
以下配置可以用于调整 sql client 的行为。
有些配置属性是流批都可以用的,有些用于流式,有些用于批处理。在default中没有特别说明的是流批均可,如果标明了则表示只适用于流或批。

以上,本文简单介绍了table和SQL API在执行、优化器、planner和sql client几方面的配置属性以及以java代码示例性的演示属性的配置方式。

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











