







1. 题目范围
Java后端研发涉及到的范围包括:
- 计算机基础:
- 网络基础:
- 云服务基础:
- 开发框架:
- 中间件:
- 领域建模设计
2. 适用人群
- 需要面试的初/中/高级 java 程序员
- 想要查漏补缺的人
- 想要不断完善和扩充自己 java 技术栈的人
- java 面试官
3. 各大公司对候选者的筛选偏好
百度:简单聊过,未真正面试,不发表评论;
阿里:既要候选人的知识广度,又要深度,特别注重候选人在以往项目中的思考和解决方案,要求工作年限和能力有一定匹配度;
腾讯:北京Java岗位,整体聊下来比较轻松,对知识面有一定要求,但不强烈,更多看交流气氛;
字节:直接哐哐哐的算法,答不上来没机会到下一轮;
美团:对细节关注比较多,会问到比较深的知识点;LZ面试得到的反馈要求岗位匹配度,也就是说需要有一定的项目经历匹配;
快手:面试常用知识点,但是要求能够手写出来实现,有些知识点要求有专业度;
滴滴:整体偏向于基础知识问答;
小米:基础知识问答+首先简单算法程序题;
京东:老东家了,有些记不清了,欢迎评论补充;
4. 具体面试题搜集
4.1 开放类题目
在过往的项目经历中,印象最深的项目是什么?你在其中做了什么?
4.2 数据库题目
2)常用的MySQL架构是怎样的,各有什么优劣
常见的数据库的高可用方案包括:双机主备,一主一从,一主多从,同步多主机,中间件。
双机主备:优点是一个机器宕机后可以自动切换到另一个机器,操作简单;缺点是只有一个机器在提供服务,读写压力大;
一主一从:优点是从库支持读,读写分离,并且一个机器宕机后可切换到另一个机器;缺点是并发度还是不够;
一主多从:优点是多个从库分担了主库的读请求,提升了并发度;缺点是只有一台主机,写的能力受限;
同步多主机:通过代理层负载,读写的能力都有明显提升,有较高的可用性保障;缺点是:如果集群中一个节点变慢,其他节点也会变慢;
数据库中间件Mycat:数据库分片存储,解决高并发度读写,并且高可用性;缺点是维护成本比较高;
3)什么是事务?常见分布式事务解决方案
事务是逻辑上的一组数据库操作,要么都执行,要么都不执行,遵循ACID原则;
分布式事务的几种解决方案:
- 2PC:分为prepare和commit/rollback两阶段,存在同步阻塞、事务管理器单点、极端情况下数据不一致等缺点
- 3PC:分为CanCommit, preCommit和doCommit, 利用超时机制解决2PC的同步阻塞问题,避免资源呗永久锁定,但无法应对极端情况下宕机数据不一致问题;
- TCC:采用了补偿机制,核心思想是每个操作都注册一个对应的确认和补偿(撤销)操作。TCC降低了数据库锁的操作粒度,提升性能,但对业务侵入性较大;
- 本地消息表:核心思想是将分布式事务分拆成本地事务执行,具体实现如事务消息等;
- Saga:核心思想是将长事务分拆成多个本地短事务,由saga事务协调器协调,如果正常结束就正常完成,如果某个步骤失败,则根据相反顺序调用补偿;
4)事务的隔离级别有哪些?默认的数据库隔离级别是什么?为什么选它?
数据库四大隔离级别:Read Uncommit, Read Commit, Repeatable Read, Serializable。 读未提交有脏读、不可重复、幻读问题。读已提交有不可重复读、幻读问题,读已提交有幻读问题。MySQL默认的事务隔离级别是Repeatable Read。
主从模式下MySQL主从同步是通过binlog实现的,MySQL binlog有三种格式:statement,row和mixed。 statement格式下,记录的是SQL原文。如果采用RC,
事务1:set autocommit = false; update user set name = 'xxx' where id = 123;
事务2:set auto commit = false; update user set id = 123 where id = 456; commit;
事务1:commit ;
在binlog记录中,记录为update user set id = 123 where id = 456; 和update user set name = 'xxx' where id = 123;这样就导致了从库数据的不一致性;
RR隔离级别下,不仅会对更新记录加行锁,还会增加gap lock,这样保障事务2阻塞,需要等等事务1执行完成才能继续,维护主从一致性;
5)RR隔离级别实现原理,是如何解决不可重复度的
RR的隔离级别是通过MVCC实现的,而MVCC是通过read View和undo log实现。 read view的可见性原则如下:
- 每一个数据行会有两个隐藏的列:tx_id和roll_pointer;
- read View有几个重要属性:m_ids, 系统中未提交的事务id list; min_limit_id, 生成read view时系统中最小的未提交事务ID; max_limit_id,read view生成时,系统应该给下一个事务分配的id. creator_trx_id: 创建当前read view的事务ID。
- 如果trx_id<min_limit_id,表示生成该版本的事务在read view之前,已提交,该版本可以被事务访问;
- 如果trx_id>max_limit_id,表示生成该版本的事务在read view之后,该版本不能被事务访问;
- 如果min_limit_id<=trx_id<=max_limit_id,分为三种情况:如果m_ids包含trx_id并且trx_id=creator_trx_id,表示是自己未提交的版本,所以能被控制;如果m_ids包含trx_id并且rx_id != creator_trx_id,表示不是自己的事务版本并且也未提交,所以不可见;如果m_ids不包含trx_id,表示已提交,可被访问;
6)项目中怎么设计分库分表?分布式ID如何生成
分库分表有水平切分和垂直切分两种。 水平切分的做法可以通过ldc或者用户单号hash。 垂直切分则是将列分散到不同的数据库内。
分布式ID生成方式:时间戳+随机数方式,雪花算法,号段方法,uuid, 数据库自增、Redis 自增等。
4.3 开发框架题目
1) 为什么线程崩溃不会导致JVM进程崩溃
线程崩溃进程一定会崩溃么?一般来说,如果线程非法访问内存引起的崩溃,进程一定会崩溃,原因是各个线程是共享进程地址空间的,所以某个线程非法访问,会影响到别的线程,操作系统认为很可能导致一系列严重问题,所以会处理成进程崩溃。常见的线程非法访问内存的几种情况:
- 访问没有权限的地址空间
- 访问不存在的内存空间
- 只读内存写入数据等
线程崩溃后进程是如何崩溃的呢?答案是信号机制。比如我们常在Linux系统中执行的kill -9 命令,9就是信号。背后大致运行如下:
- CPU执行正常的进程指令,调用kill向进程发送信号
- 进程收到OS的信号后,CPU暂停当前应用程序运行,将控制权转交给OS
- OS根据情况执行对应的信号处理逻辑,一般信号处理完成后会让进程退出。
- 如果进程没有注册自己的信号处理函数,OS会采用默认信号处理;同理,如果注册了新号处理函数,则调用注册函数。
为什么JVM线程崩溃不会导致JVM进程崩溃?首先明白Java中线程异常通常由非法访问内存产生,常见的有Exception(NPE)和error(Stackoverflow)。从前面知识可以知道,只要执行拦截处理信号函数,就能让进程不崩溃。
主线程异常会导致JVM退出么?做一个实验
public static void main(String[] args) {
Thread t = new Thread(()->{
while (true){
System.out.println("test");
}
});
t.start();
String s = null;
if(s.equals("3")){
System.out.println("haha");
}
}实际结果是不停的打印test。说明主线程异常后并不会导致JVM崩溃。原因是什么呢?实际上Java中并没有主线程概念,线程都是平等,普通线程异常不会导致JVM崩溃。
2)Java线程模型
从源码看Java线程模型:
// 是一个native方法
@HotSpotIntrinsicCandidate
public static native Thread currentThread();
// 启动start方法
public synchronized void start() {
...
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
}
}
}
// start0也是一个native方案
private native void start0();继续追踪start0方法,从GitHub - AdoptOpenJDK/openjdk-jdk8u: JDK8u mirror from mercurial
// jvm.cpp
JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread))
native_thread = new JavaThread(&thread_entry, sz);
// thread.cpp
JavaThread::JavaThread(ThreadFunction entry_point, size_t stack_sz)
{
os::create_thread(this, thr_type, stack_sz);
}
// os_linux.cpp
bool os::create_thread(Thread* thread, ThreadType thr_type, size_t stack_size) {
int ret = pthread_create(&tid, &attr, (void* (*)(void*)) java_start, thread);
}(代码来自芋道源码)
可以看到jvm调用线程创建最终会调用底层pthread_create创建一个native thread内核线程,由此推断出Java线程和内核线程是一一对应关系,这种模型也称之为NPTL。

内核线程在Linux系统中是通过一个task_struct结构来表示的,定义了进程所需的虚拟地址,文件描述符,寄存器、信号等资源。早期内核线程是用进程来实现的,所以创建一个线程就要fork一个进程,copy task_struct结构,开销很大。后期线程实现通过除线程栈和寄存器外都共享虚拟地址,提升线程执行效率。Linux中还引入了线程组的概念,同一组线程主pid一样,线程间的通信通过POSIX Thread标准。
NPTL线程模型的优缺点:
- 优点:相比于内核进程模式,有非常高的性能提升,单台服务器生成10万+线程2秒内完成;
- 缺点:线程或者进程的阻塞,都需要系统调度,包括上下文切换等,开销大;基于抢占式模式,线程同步需要应用自行保障顺序;内存开销仍然较大,单个线程Linux默认栈大小是1M。
所以有了协程(Coroutine)概念的出现。协程可以分为两个角度来看:一个是routine执行单元,一个是cooperative协作单元。协程与线程的不同之处在:协程遇到IO阻塞事件,会自动让出调度权,转而执行其他协程,而协程的挂起和唤醒完全是由用户态决定的,不会到内核态开销。所以协程业非常适合IO密集的应用。
3)Spring中为何不推荐直接使用异步线程注解@Async
@Async使用默认的线程池,而默认的线程池是SimpleAsyncTaskExecutor,具体的代码实现:
public class AsyncSupportConfigurer {
...
/**
* 异步配置默认使用SimpleAsyncTaskExecutor
* The provided task executor is used to:
* <ol>
* <li>Handle {@link Callable} controller method return values.
* <li>Perform blocking writes when streaming to the response
* through a reactive (e.g. Reactor, RxJava) controller method return value.
* </ol>
* <p>By default only a {@link SimpleAsyncTaskExecutor} is used. However when
* using the above two use cases, it's recommended to configure an executor
* backed by a thread pool such as {@link ThreadPoolTaskExecutor}.
* @param taskExecutor the task executor instance to use by default
*/
public AsyncSupportConfigurer setTaskExecutor(AsyncTaskExecutor taskExecutor) {
this.taskExecutor = taskExecutor;
return this;
}
...
}
public class SimpleAsyncTaskExecutor extends CustomizableThreadCreator implements AsyncListenableTaskExecutor, Serializable {
...
// 执行方法
protected void doExecute(Runnable task) {
Thread thread = this.threadFactory != null ? this.threadFactory.newThread(task) : this.createThread(task);
thread.start();
}
...
}所以在只用@Async注解的时候, 一般要通过接口AsyncSupportConfigurer自定义线程池。
4)Java中new一个对象的过程
在《深入理解Java虚拟机》中介绍:当虚拟机遇到new 指令后,会检查静态常量池中是否定位到一个类的引用符号,并检查这个类引用符号是否被加载、解析和初始化过,如果没有则执行类的加载过程。
类加载是把class文件变成一个二进制流加载到内存中,classloader加载class文件会把类中的常量值、方法和类信息记在到元数据内,最终生成一个class对象。
加载完成后是连接,为类中的静态变量分配存储空间,设立初始值(还未初始化),如果有静态代码块,也会执行静态代码块内容。
最后是初始化,具体包括给对象分配存储空间,并设置默认值,如果有引用对象会在栈内存中申请一个空间来指向实际对象;执行初始化代码实例,先从父类再到子类;对象实例化完成后,如果栈中存在引用对象指针,还需要把指针对应的对象也实例化出来。

(图来自知乎 健美猪)
5)Java中守护线程和非守护线程
守护线程和非守护线程都是线程,守护线程有一个特征:当主线程销毁时会和主线程一起销毁,比如GC线程,而非守护线程则不会随着主线程销毁。
4.4 中间件题目
4.4.1 消息中间件
| ActiveMq | RabbitMq | RocketMq | Kafka | |
| 吞吐量 | 万+ | 万+ | 10万+ | 10万+ |
| 开发语言 | java | erlang | java | scala |
| 时效 | ms | ms | ms | ms |
| 可用性 | 主从架构,高 | 主从架构,高 | 分布式,非常高 | 分布式,非常高 |
| 功能成熟性 | 成熟度高,有较多公开文档,使用公司也较多 | 性能好,延时低 | 功能比较完备,扩展性好 | 只支持MQ基本功能,适合大数据量吞吐场景 |
| 缺点 | 社区维护性较差,不适合大吞吐量场景 | erlang语言不利于二次开发,吞吐量较弱,学校维护成本高 | Java和c++语言支持,c++支持度较弱 | 单机队列超过64个后,load会明显飘高;不支持消息重试,消息有序性维度度较低 |
了解Kafka的详情可参见:KafKa消息中间件_西木风落的博客-CSDN博客_kafka消息中间件
RocketMq的源码解读可参见:RocketMq源码解读(一)_西木风落的博客-CSDN博客
1)怎么解决百万消息积压问题:
首先对积压问题定位:如果是瞬时流量飙高,后续流量回落,并且消费者在正常消费,这种情况持续监控即可;如果是流量持续加大,原来的消费者数量不够,可以选择增大消费者数量;如果消费速度过慢,可以将消费的消息直接写入新的topic下更大的message queue下,新建立消费链路。
4.4.2 Nginx
4.4.3 mybais
参见:Mybaits 常用问题详解_西木风落的博客-CSDN博客
4.5 微服务题目
1)什么是微服务
(Martin Fowler)目前而言对微服务并没有一个统一的、标准的定义,但通常而言,微服务架构是一种架构模式或者风格,提倡讲单一应用划分为一组小的服务,每个服务运行在自己的进程。
简单来说,微服务就是独立的单一职责应用服务。
2)微服务通讯方式
同步:大部分采用rpc远程调用,spring cloud 采用的是rest接口JSON调用。
异步:通常采用消息队列方式;
3)什么是熔断,什么是降级
熔断是指当某服务不可用或者相应超时,为防止整个系统雪崩,暂时停止对该系统的服务调用;降级是指当系统负载过高时,为防止系统崩溃,内部暂时放弃对一些非重要接口和数据的请求,而直接返回一个预先准备好的数据,提高RT响应,保证系统的稳定性和可用性。
4)为什么要采用微服务设计
优点:
- 架构上:服务单一职责,各系统服务高内聚,可维护性强,链路抗风险性强;
- 资源成本上:微服务应用可按需分配资源,有助提升资源利用率;
- 人力成本上:团队按需分配,降本提效;
缺点:系统复杂性增加,管理和运维成本随着复杂度也会提升,系统依赖性强;
5)eureka、zookeeper、nacos都可以作为注册中心,区别
- Nacos与Eureka的区别:
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式;
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
- zk和eureka的区别:
- zk是CP原则,当主节点挂掉时,zk会重新选主,选主节点如果有服务注册或者注销,都不能及时同步到集群,可能导致服务不可用;
- eureka是AP原则,一个节点挂掉后其他节点仍能保持正常工作;
6)分布式锁实现
分布式锁是控制不同进程对共享资源访问一种锁实现形式。常见的视线方式有:数据库锁、Redis锁和zk锁。数据库锁分为悲观(select for update)和乐观锁(版本控制) 。Redis锁一般通过setnx+expire或者扩展命令set ex px nx xx(管道)。zk采用临时有序节点机制。从性能角度Redis>zk>=db。实现角度(从低到高)db>redis>zk;可靠性(从高到底)zk>redis>db
4.6 计算机网络题目
1)http 协议详解
http协议是一个无状态协议,本身不会对发送请求和响应通信状态持久化,目的是为了保持http协议的简单性和高效率性。http请求体有:请求行、header和请求体组成。
- 请求行:包含method, url和version。e.g. POST https://event.csdn.net/logstores HTTP/1.1
- 请求头:可以含带较多信息,比如请求格式 content-type:text/plain;charset=UTF-8
响应报文包含状态行,响应头和响应体组成。
Http存在通信明文,内容可能被窃听,以及内容篡改等风险,所以后续推出了https。
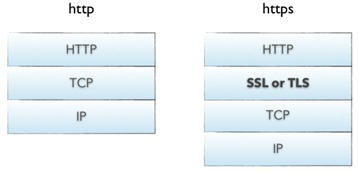
2)https协议
https在TCP协议之上增加了一层SSL/TLS,用于加密http的通信内容。

3)http3协议
HTTP2协议虽然大幅提升了HTTP/1.1的性能,但基于TCP实现的HTTP2遗留下3个问题:
- 有序字节流引出的队头阻塞(Head-of-line blocking),使得HTTP2的多路复用能力大打折扣;
- TCP与TLS叠加了握手时延,建链时长还有1倍的下降空间;
- 基于TCP四元组确定一个连接,这种诞生于有线网络的设计,并不适合移动状态下的无线网络,这意味着IP地址的频繁变动会导致TCP连接、TLS会话反复握手,成本高昂
HTTP3协议解决了这些问题:
- HTTP3基于UDP协议重新定义了连接,在QUIC层实现了无序、并发字节流的传输,解决了队头阻塞问题(包括基于QPACK解决了动态表的队头阻塞);
- HTTP3重新定义了TLS协议加密QUIC头部的方式,既提高了网络攻击成本,又降低了建立连接的速度(仅需1个RTT就可以同时完成建链与密钥协商);
- HTTP3 将Packet、QUIC Frame、HTTP3 Frame分离,实现了连接迁移功能,降低了5G环境下高速移动设备的连接维护成本。
4)高并发场景下httpclient优化
httpclient是一个线程安全的类,反复创建存在的开销:对象创建开销和TCP连接创建开销。 所以优化可以从:单列client和缓存保活。具体的client工具类可见:HttpClient高并发下性能优化-http连接池_a363722188的博客-CSDN博客_httpclient 连接池监控
4.7 云原生题目
4.8 设计类题目
1)为什么要设计接口幂等性
什么叫幂等?是指可以使用相同参数重复执行,并能获得相同结果(来自百科)。接口为什么要幂等?个人任务最主要是接口逻辑一致性要求。比如:在电商商品退款时,同一个订单不论执行多少次退款,退款的逻辑都会保持一致(只退款一次);常见实现接口幂等性通过token机制,逻辑实现一锁二判3更新。
2)feed流实现
feed流即持续更新并呈现给用户内容的信息流,特点是将用户主动订阅的若干消息源组合在一起形成内容聚合器,帮助用户持续地获取最新的订阅源内容。比如微博,微信朋友圈。feed流有两种实现模式:push和pull.
- push:新的feed发布后,将其插入到发布者所有粉丝的feed流中。这种方式的优点是快速响应用户拉取最新消息,缺点是大v发布信息后,push给所有粉丝会产生较大的流量尖峰;
- pull:优点是大v发布信息后不会产生流量尖峰,缺点是粉丝收到信息响应较慢。
feed流系统中存储的数据有3部分:作者发布的feed列表,作者和粉丝的关注关系,粉丝用户的feed流信息。轻量化的解决方案作者发布的feed列表存储在NoSQL中,作者和粉丝的关系存储即可是关系型数据库,也可以是KV键值数据库,对于粉丝用户的信息一般保存在内存中。
Feed流优化:作者拥有小客群课直接使用push模式,大v可参用:在线粉丝数量可控,push模式,离线的用户粉丝pull模式。如果在线人数非常多,则仍以pull模式为主。
其次,feed流通常会很大,不可能一次性将所有内容拉取到本地,所以要支持分页查询,通常用lastId+limit式分页器。
最后异步缓存历史feed流信息。默认可缓存用户一月或者一周的信息,当用户浏览到月最后几天时,开始异步组装缓存历史信息,这样减少用户等待时间,提高用户满意度。















 1130
1130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









