






一、获取公开数据集
- **UCI机器学习知识库:**包括近300个不同大小和类型的数据集,可用于分类、回归、聚类和推荐系统任务。数据集列表位于:http://archive.ics.uci.edu/ml/
- ** Amazon AWS公开数据集:**包含的通常是大型数据集,可通过Amazon S3访问。这些数据集包括人类基因组项目、Common Craw网页语料库、维基百科数据和Google Books Ngrams。相关信息可参见:http://aws.amazon.com/publicdatasets/
- **Kaggle:**这里集合了Kaggle举行的各种机器学习竞赛所用的数据集。它们覆盖分类、回归、排名、推荐系统以及图像分析领域,可从Competitions区域下载:http://www.kaggle.com/competitions
- **KDnuggets:**这里包含一个详细的公开数据集列表,其中一些上面提到过的。该列表位于:http://www.kdnuggets.com/datasets/index.html
MovieLens 100k 数据集
MovieLens 100k数据集包含表示多个用户对多部电影的10万次评级数据,也包含电影元数据和用户属性信息。
下载链接:http://files.grouplens.org/datasets/movielens/ml-100k.zip
下载后解压:
unzip ml-100k.zip

其中重要文件有:u.user(用户属性文件)、u.item(电影元数据)和u.data(用户对电影的评级)。关于数据集更多信息可从README获得,包括每个数据文件里的变量定义。
可用head命令查看各个文件中的内容:
head -5 u.user

二、探索与可视化数据
工具:IPython 是针对Python的一个高级交互式壳程序,包含内置一系列实用功能的pylab,其中有NumPy和SciPy用于数值计算,以及matplotlib用于交互式绘图和可视化。
Anaconda安装方法: https://blog.csdn.net/zhdgk19871218/article/details/46502637
Ipython notebook使用教程: https://blog.csdn.net/worfs123456/article/details/53506351
基于pyspark和scala的Jupyter notebook安装: https://blog.csdn.net/xmo_jiao/article/details/72674687?utm_source=itdadao&utm_medium=referral
toree安装Scala的notebook: https://blog.csdn.net/cafebar123/article/details/78636826
PySpark支持运行Python时可指定参数。在启动PySpark终端时,我们可以使用IPython而非标准的Python shell。启动时也可以向IPython传入其他参数,包括让它在启动时也启用pylab功能。
可在Spark主目录下运行如下命令启动IPython(https://blog.csdn.net/JavaMoo/article/details/77275515):
PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="--pylab" ./bin/pyspark
2.1 探索用户数据
启动基于pyspark的Jupyter notebook:
cd ~/IPythonNotebook
bash /usr/local/spark/starths.sh #启动脚本
/usr/local/spark/bin/pyspark #打开 jupyter notebook
%matplotlib inline
import numpy as np
from matplotlib.pylab import *
import matplotlib.pyplot as plt
from matplotlib.pyplot import hist
首先分析MovieLens用户的特征:
下述代码生成RDD,每一个记录对应一个Python列表,各列表由 用户ID(user ID) , 年龄(age),性别(gender),职业(occupation) 和 邮编(ZIP code) 五个属性构成。
user_data = sc.textFile("/winnie/DataSets/ml-100k/u.user") #hadoop文件
user_data.first() #或take(1)
'1|24|M|technician|85711'
统计用户,性别,职业和邮编的数目:
user_fields = user_data.map(lambda line: line.split("|")) # 用 | 分隔各行数据
num_users = user_fields.map(lambda fields: fields[0]).count() # 用户数
num_genders = user_fields.map(lambda fields: fields[2]).distinct().count() # 性别数目,去重
num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count() #职业数目
num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count() #邮编数目
print("Users: %d, genders: %d, occupations: %d, ZIP codes: %d" % (num_users, num_genders, num_occupations, num_zipcodes))
Users: 943, genders: 2, occupations: 21, ZIP codes: 795
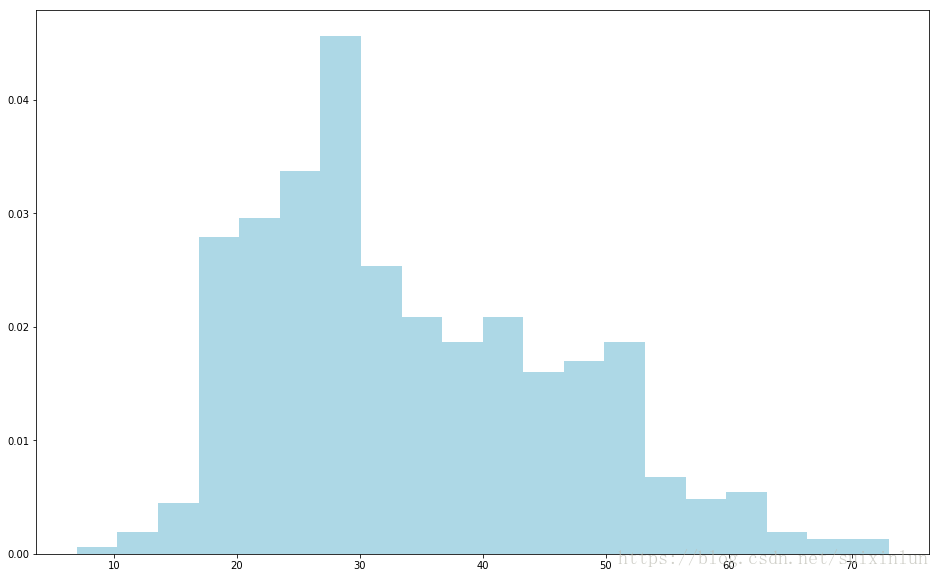
用 matplotlib 的 hist 函数来创建一个直方图,以分析用户年龄的分布情况:
ages = user_fields.map(lambda x: int(x[1])).collect() #提出年龄所有数据项
hist(ages, bins=20, color='lightblue', density=True) #区间数为20
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)
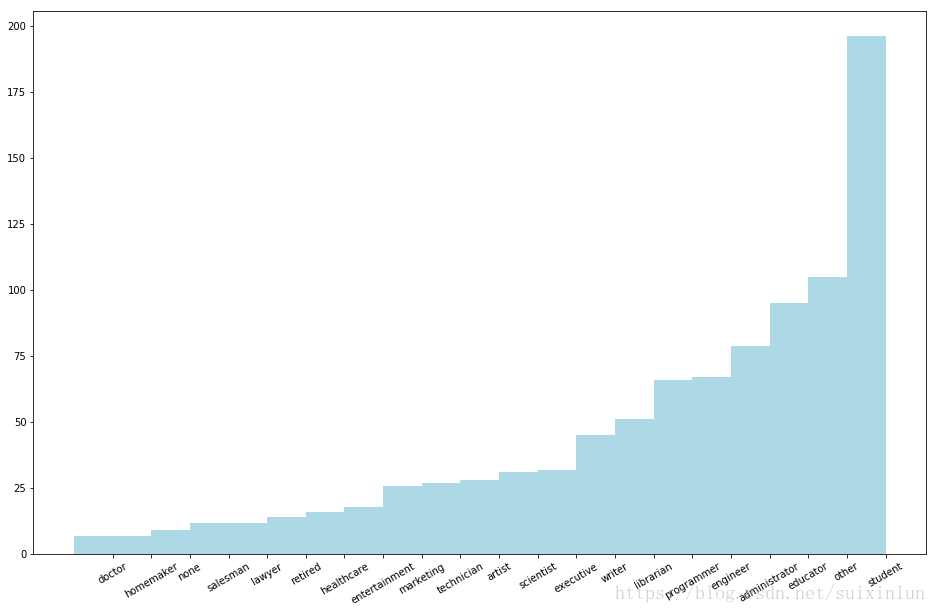
count_by_occupation = user_fields.map(lambda fields: (fields[3], 1)).reduceByKey(lambda x, y: x + y).collect() #职业出现次数
x_axis1 = np.array([c[0] for c in count_by_occupation])
y_axis1 = np.array([c[1] for c in count_by_occupation])
x_axis = x_axis1[np.argsort(y_axis1)] #升序
y_axis = y_axis1[np.argsort(y_axis1)]
#创建条形图
pos = np.arange(len(x_axis))
width = 1.0
ax = plt.axes()
ax.set_xticks(pos + (width / 2))
ax.set_xticklabels(x_axis)
plt.bar(pos, y_axis, width, color='lightblue')
plt.xticks(rotation=30) #旋转30°
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)
count_by_occupation2 = user_fields.map(lambda fields: fields[3]).countByValue()
print("Map-reduce approach:")
print(dict(count_by_occupation2))
print("")
print("countByValue approach:")
print(dict(count_by_occupation))
Map-reduce approach: {'technician': 27, 'other': 105, 'writer': 45, 'executive': 32, 'administrator': 79, 'student': 196, 'lawyer': 12, 'educator': 95, 'scientist': 31, 'entertainment': 18, 'programmer': 66, 'librarian': 51, 'homemaker': 7, 'artist': 28, 'engineer': 67, 'marketing': 26, 'none': 9, 'healthcare': 16, 'retired': 14, 'salesman': 12, 'doctor': 7} countByValue approach: {'other': 105, 'executive': 32, 'administrator': 79, 'student': 196, 'educator': 95, 'programmer': 66, 'homemaker': 7, 'artist': 28, 'engineer': 67, 'none': 9, 'retired': 14, 'doctor': 7, 'technician': 27, 'writer': 45, 'lawyer': 12, 'scientist': 31, 'entertainment': 18, 'librarian': 51, 'marketing': 26, 'healthcare': 16, 'salesman': 12}
2.2 探索电影数据
简单看一下某行记录,然后再统计电影总数:
movie_data = sc.textFile("/winnie/DataSets/ml-100k/u.item")
print(movie_data.first())
num_movies = movie_data.count()
print("Movies: %d" % num_movies)
1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0 Movies: 1682
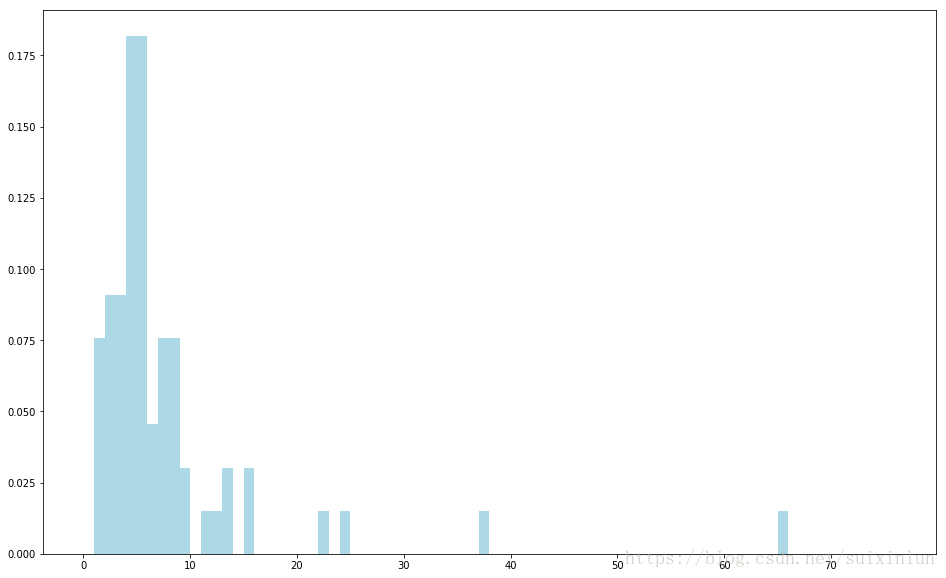
电影数据中有些数据不规整,故需要一个函数来处理解析releasedate时可能的解析错误.这里命名该函数为convert_year.接着便可在调用电影数据进行map转换时应用该函数,并取回其结果: 使用Spark的filter转换操作过滤掉问题数据后,用当前年份减去发行年份,从而将电影发行年份列表转换为电影年龄.接着用countByValue来计算不同年龄电影的数目.最后绘制电影年龄直方图(同样会使用hist函数,且其values变量的值来自countByValue的结果,主键则为bins变量):
def convert_year(x):
try:
return int(x[-4:])
except:
return 1900 #若数据缺失年份则将其年份设为1900,在后续处理中会过滤掉这类数据。
movie_fields = movie_data.map(lambda lines: lines.split("|"))
years = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x)) #获得年份
years_filtered = years.filter(lambda x: x!= 1900) #过滤掉缺失年份的电影数据
movie_ages = years_filtered.map(lambda yr: 1998-yr).countByValue() #电影年龄(相对于现在1998年)
# values = movie_ages.values() #不同年龄电影的个数
# bins = movie_ages.keys() #不同电影的年龄
# 用了比较复杂的方法:升序排序,dict和list来回转换,否则出错
movieages=sorted(movie_ages.items(),key=lambda x:x[0])
values = list(dict(movieages).values()) #不同年龄电影的个数
bins = list(dict(movieages).keys()) #不同电影的年龄
hist(values, bins=bins, color='lightblue', density=True)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16,10)
2.3 探索评级数据
先来看一下评级数据:
rating_data_raw = sc.textFile("/winnie/DataSets/ml-100k/u.data")
print(rating_data_raw.first())
num_ratings = rating_data_raw.count() # 评级次数 10万
print("Ratings: %d" % num_ratings)
196 242 3 881250949 Ratings: 100000
可以看到评级次数共有10万.另外和用户数据与电影数据不同,评级记录用'\t'分隔.下面做些基本统计,以及绘制评级值分布的直方图:
# 绘制评级值分布的直方图
rating_data = rating_data_raw.map(lambda line: line.split("\t"))
ratings = rating_data.map(lambda fields: int(fields[2])) #获取评级
max_rating = ratings.reduce(lambda x, y: max(x, y)) #获取最大评级
min_rating = ratings.reduce(lambda x, y: min(x, y)) #获取最小评级
mean_rating = ratings.reduce(lambda x, y: x + y) / num_ratings #平均评级
median_rating = np.median(ratings.collect()) #评级中位数
ratings_per_user = num_ratings / num_users #每个用户的平均评级次数
ratings_per_movie = num_ratings / num_movies #每部电影的平均评级次数
print("Min rating: %d" % min_rating)
print("Max rating: %d" % max_rating)
print("Average rating: %2.2f" % mean_rating)
print("Median rating: %d" % median_rating)
print("Average # of ratings per user: %2.2f" % ratings_per_user)
print("Average # of ratings per movie: %2.2f" % ratings_per_movie)
Min rating: 1 Max rating: 5 Average rating: 3.53 Median rating: 4 Average # of ratings per user: 106.04 Average # of ratings per movie: 59.45
Spark对RDD也提供一个名为states的函数.该函数包含一个数值变量用于做类似的统计(其中,stdev为标准差):
ratings.stats()
(count: 100000, mean: 3.5298600000000024, stdev: 1.125667970762251, max: 5.0, min: 1.0)
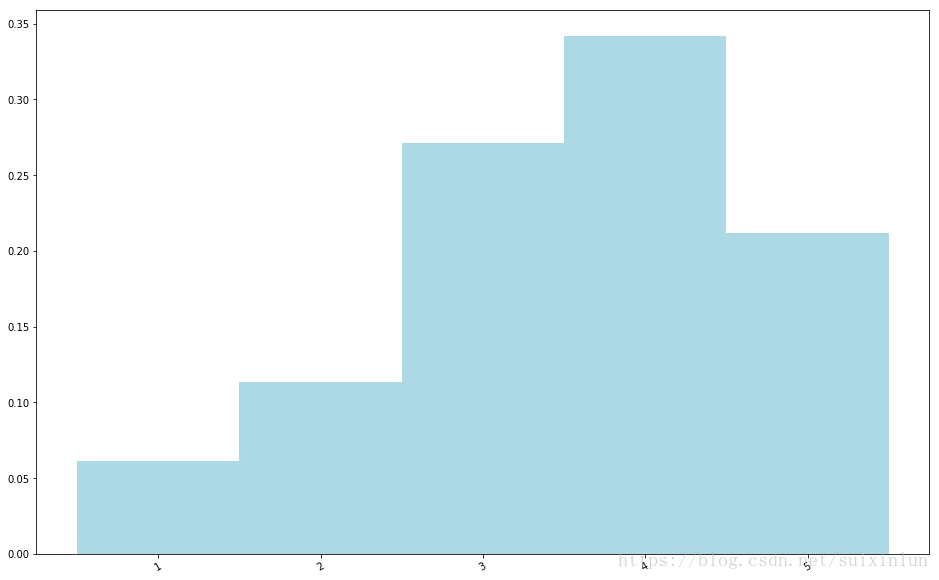
可以看出,用户对电影的平均评级(mean)是3.5左右,而评级中位数(median)为4.这就能期待说评级的分布稍倾向高点的得分.要验证这的,可以创建一个评级值分布的条行图.
# 创建评级值分布条形图
count_by_rating1 = ratings.countByValue() #评级计数
count_by_rating=sorted(count_by_rating1.items(),key=lambda x:x[0]) #排序
x_axis = dict(count_by_rating).keys()
y_axis = np.array([float(c) for c in dict(count_by_rating).values()])
# 这里对y轴正则化,使它表示百分比
y_axis_normed = y_axis / y_axis.sum()
pos = np.arange(len(x_axis))
width = 1.0
ax = plt.axes()
# ax.set_xticks(pos + (width / 2))
ax.set_xticks(pos)
ax.set_xticklabels(x_axis)
plt.bar(pos, y_axis_normed, width, color='lightblue')
plt.xticks(rotation=30)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)
同样也可以求各个用户评级次数的分布情况.先从rating_data RDD里提取出以用户ID为主键,评级为值的键值对.之后调用Spark的groupByKey函数,来对评级以用户ID为主键进行分组:
user_ratings_grouped = rating_data.map(lambda fields: (int(fields[0]), int(fields[2]))).groupByKey().sortByKey() #(用户主键,评级)
# 求出每一个主键(用户ID)对应的评级集合的大小
user_ratings_byuser = user_ratings_grouped.map(lambda kv: (kv[0], len(kv[1])))
user_ratings_byuser.take(5)
[(1, 272), (2, 62), (3, 54), (4, 24), (5, 175)]
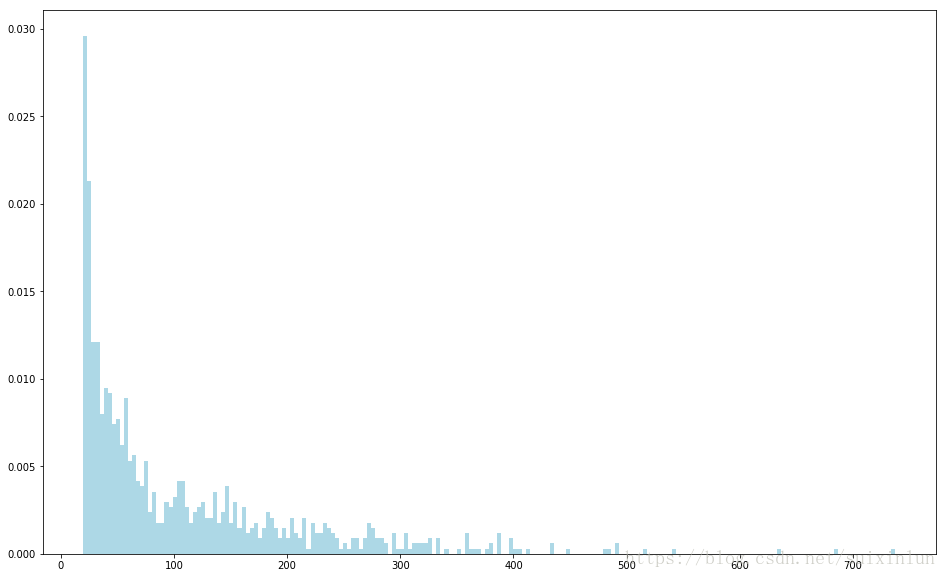
最后,用hist函数来绘制各用户评级分布的直方图:
# 用hist函数绘制各用户评级分布的直方图
user_ratings_byuser_local = user_ratings_byuser.map(lambda kv: kv[1]).collect() #评级次数
hist(user_ratings_byuser_local, bins=200, color='lightblue', density=True)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)
三、处理与转换数据
为让原始数据可用于机器学习算法,需要先对其进行清理,并可能需要将其进行各种转换,之后才能从转换后的数据里提取有用的特征.数据的转换和特征提取联系紧密.某些情况下,一些转换本身便是特征提取的过程.
一般来说,现实中的数据会存在信息不规则,数据点缺失和异常值问题.理想情况下,我们会修复非规整数据.但很多数据集都源于一些难以重现的收集过程(比如网络活动数据和传感器数据),故实际上会难以修复.值缺失和异常也很常见,且处理方式可与处理非规整信息类似.大致处理方法如下:
- **过滤掉或删除非规整或有值缺失的数据:**这通常是必须的,但的确会损失这些数据里那些好的信息.
- **填充非规整或缺失的数据:**可以根据其他的数据来填充非规整或缺失的数据.方法包括用零值、全局期望或中值来填充,或是根据相邻或类似的数据点来做插值(通常针对时序数据)等.选择正确的方式并不容易,它会因数据、应用场景和个人经验而不同.
- **对异常值做鲁棒处理:**异常值的主要问题在于即使它们是极值也不一定就是错的.到底是对是错通常很难分辨.异常值可被移除或是填充,但的确存在某些统计技术(如鲁棒回归)可用于处理异常值或是极值.
- **对可能的异常值进行转换:**另一种处理异常值的或极值的方法是进行转换.对那些可能存在异常值或值域覆盖过大的特征,利用如对数或高斯核对其转换.这类转换有助于降低变量存在的值跳跃的影响,并将非线性关系变为线性的.
非规整数据和缺失数据的填充
下面的代码对发行日期有问题的数据采取填充策略,即用发行日期的中位数来填充问题数据:
# 对发行日期有问题的数据采取填充策略,即用发行日期的中位数来填充问题数据:
years_pre_processed = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x)).collect() #发行年份,缺失为1900
years_pre_processed_array = np.array(years_pre_processed)
# 首先计算发行年份的平均数和中位数(选取的数据不包含非规整数据)。
# 然后用numpy的函数来找出year_pre_processed_array中的非规整数据点的序号(1900为非规则数据)。
# 最后通过该序号来将中位数作为非规则数据的发行年份。
mean_year = np.mean(years_pre_processed_array[years_pre_processed_array!=1900]) #对规整数据求均值
median_year = np.median(years_pre_processed_array[years_pre_processed_array!=1900]) #对规整数据求中位数
index_bad_data = np.where(years_pre_processed_array==1900)[0] #如果是[0][0],只会替换第一个非规整数据
years_pre_processed_array[index_bad_data] = median_year
print("Mean year of release: %d" % mean_year)
print("Median year of release: %d" % median_year)
print("Index of '1900' after assigning median: %s" % np.where(years_pre_processed_array == 1900)[0])
Mean year of release: 1989 Median year of release: 1995 Index of '1900' after assigning median: []
四、从数据中提取有用特征
在完成对数据的初步探索、处理和清理后,便可从中提取可供机器学习模型训练用的特征. **特征(feature)**指那些用于模型训练的变量.每一行数据包含可供提取到训练样本中的各种信息.从根本上说,几乎所有机器学习模型都是与用向量表示的数值特征打交道;因此,需要将原始数据转换为数值.
特征可以概括地分为如下几种:
- **数值特征(numerical feature):**这些特征通常为实数或整数,比如年龄.
- **类别特征(categorical feature):**它们的取值只能是可能状态集合中的某一种.我们数据集中的用户性别、职业或电影类别便是这类.
- **文本特征(text feature):**它们派生自数据中的文本内容,比如电影名、描述或是评论.
- **其他特征:**大部分其他特征都最终表示为数值.比如图像、视频和音频可被表示为数值数据的集合.地理位置则可由经纬度或地理散列(geohash)表示.
4.1 数值特征
原始的数值和一个数值特征之间的区别是什么? 实际上,任何数值数据都能作为输入变量.但是,机器学习模型中所学习的是各个特征所对应的向量的权值.这些权值在特征值到输出或是目标变量(指在监督学习模型中)的映射过程中扮演重要角色.
由此我们会使用那些合理的特征,让模型能从这些特征学到特征值和目标变量之间的关系.比如年龄就是一个合理的特征.年龄的增加和某项支出直接之间可能就存在直接关系.类似地,高度也是一个可直接使用的数值特征.
当数值特征仍处于原始形式时,其可用性相对较低,但可以转化为更有用的表示形式.位置信息便是如此.若使用原始位置信息(比如使用经纬度表示的),我们的模型可能学习不到该信息和某个输出之间的有用关系,这就使得该信息的可用性不高,除非数据点的确很密集.然而若对位置进行聚合或挑选后(比如聚焦为一个城市或国家),便容易和特定输出之间存在某种关联了.
4.2 类别特征
当类别特征仍为原始形式时,其取值来自所有可能值所构成的集合而不是一个数字,故不能作为输入.如例子中的用户职业便是一个类别特征变量,其可能取值有学生,程序员等.
这样的类别特征也称作名义(nominal)变量,即其各个可能取值之间没有顺序关系.相反,那些存在顺序关系的(比如评级)则被称为有序(ordinal)变量.
将类别特征表示为数字i形式,常可借助k之1(1-of-k)方法进行.将名义变量表示为可用于机器学习任务的形式,会需要借助如k之1编码这样的方法.有序变量的原始值可能就能直接使用,但也常会经过和名义变量一样的编码处理.
假设变量可取的值有k个.如果对这些值用1到k编序,则可以用长度为k的二元向量来表示一个变量的取值.在这个向量里,该取值对应的序号所在的元素为1,其他元素都为0.
我们可以取回occupation的所有可能取值:
# 职业
all_occupations = user_fields.map(lambda fields: fields[3]).distinct().collect()
all_occupations.sort()
# print(all_occupations)
# 依次对各可能的职业分配序号(从0开始编号):
idx = 0
all_occupations_dict = {}
for o in all_occupations:
all_occupations_dict[o] = idx
idx += 1
# 看一下"k之1"编码会对新的例子分配什么值
print("Encoding of 'doctor': %d" % all_occupations_dict['doctor'])
print("Encoding of 'programmer': %d" % all_occupations_dict['programmer'])
# 编码programmer的取值.首先需创建一个长度和可能的职业数目相同的numpy数组,其各元素值为0,这可通过numpy的zeros函数实现.
# 之后提取单词programmer的序号,并将数组中对应该序号的那个元素值赋为1:
K = len(all_occupations_dict)
binary_x = np.zeros(K)
k_programmer = all_occupations_dict['programmer']
binary_x[k_programmer] = 1
print("Binary feature vector: %s" % binary_x)
print("Length of binary vectory: %d" % K)
Encoding of 'doctor': 2 Encoding of 'programmer': 14 Binary feature vector: [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.] Length of binary vectory: 21
4.3 派生特征
从现有的一个或多个变量派生出新的特征常常是有帮助的.理想情况下,派生出的特征能比原始属性带来更多信息.
从原始数据派生特征的例子包括计算平均值,中位值,方差,和,差,最大值或最小值以及计数.
数值特征到类别特征的转换也很常见,比如划分为区间特征.进行这类转换的变量常见的有年龄,地理位置和时间.
将时间戳转为类别特征 下面以对评级时间的转换为例,说明如何将数值数据转换为类别特征.该时间的格式为Unix的时间戳.我们可以用Python的datetime模块从中提取出日期,时间以及点钟(hour)信息.其结果将是由各评级对应的点钟数所构成的RDD.
# 定义一个函数将评级时间戳提取为datatime的格式:
def extract_datetime(ts):
import datetime
return datetime.datetime.fromtimestamp(ts)
# 首先使用map将时间戳属性转换为Python int 类型.
# 然后通过extract_datetime函数将各时间戳转为datetime类型的对象,进而提取其点钟数
timestamps = rating_data.map(lambda fields: int(fields[3])) #时间戳,比如 881250949
hour_of_day = timestamps.map(lambda ts: extract_datetime(ts).hour) # 时钟
hour_of_day.take(5)
[23, 3, 15, 13, 13]
假设想要更为精确的表示,可以将点钟数划分到一天中的不同阶段.创建一个以点钟数为输入的函数来返回相应的时间段:
# 将点钟数划分到一天中的不同时段
def assign_tod(hr):
times_of_day = {
'morning' : range(7, 12),
'lunch' : range(12, 14),
'afternoon' : range(14, 18),
'evening' : range(18, 24),
'night' : range(0, 7)
}
for k, v in times_of_day.items():
if hr in v:
return k
time_of_day = hour_of_day.map(lambda hr: assign_tod(hr))
time_of_day.take(5)
['evening', 'night', 'afternoon', 'lunch', 'lunch']
我们已将时间戳变量转为点钟数,再接着转为了时间段,从而得到了一个类别特征.我们可以借助之前提到的k之1编码方法来生成其相应的二元特征向量.
4.4 文本特征
从某种意义上说,文本特征也是一种类别特征或派生特征.
文本的处理方式有很多种.自然语言处理便是专注于文本内容的处理,表示和建模的一个领域.
在这里仅介绍一种简单且标准化的文本特征提取方法.该方法被视为**词袋(bag-of word)**表示法.
词袋法将一段文本视为由其中的文本或数字组成的集合,其处理过程如下:
- 分词(tokenization):首先会应用某些分词方法来将文本分隔为一个由词(一般如单词,数字等)组成的集合.可用的方法如空白分隔法.这种方法在空白处对文本分隔并可能还删除其他如标点符号和其他非字母或数字字符.
- **删除停用词(stop words removal):**之后,它通常会删除常见的单词,比如the, and和but(这些词被称作停用词).
- **提取词干(stemming):**下一步则是词干的提取.这是指将各个词简化为其基本的形式或者干词.常见的例子如复数变为单数.提取的方法有很多种,文本处理算法库中常常会包括多种词干提取方法.
- 向量化(vectorization):最后一步就是用向量来表示处理好的词.二元向量可能是最为简单的表示方法.它用1和0来分别表11示是否存在某个词.从根本上说,这与之前提到的k之1编码相同.它需要一个词的字典来实现词到索引序号的映射.随着遇到的词增多,各种词可能达树百万.由此,使用稀疏矩阵来表示就很挂机.这种表示只记录某个词是否出现过,从而节省内存和磁盘空间,以及计算时间.
提取简单的文本特征 以数据集中的电影标题为例,来示范如何提取文本特征为二元矩阵.
# 首先需创建一个函数来过滤掉电影标题中可能存在的发行年月.
# 使用Python的正则表达式模块re来寻找标题里位于括号之间的年份.如果找到与表达式匹配的字段,我们将提取标题中匹配起始位置(即左括号所在的位置)之前的部分.
def extract_title(raw):
import re
# 该表达式找寻括号之间的非单词(数字)
grps = re.search("\((\w+)\)", raw) # \w:用于匹配字母,数字或下划线字符;
# “+”元字符规定其前导字符必须在目标对象中连续出现一次或多次
if grps:
# 只选取标题部分,并删除末尾的空白字符
return raw[:grps.start()].strip()
else:
return raw
# 从movie_fields RDD里提取出原始的电影标题:
raw_titles = movie_fields.map(lambda fields: fields[1])
# 用前5个原始标题来测试一下extract_title函数:
for raw_title in raw_titles.take(5):
print(extract_title(raw_title))
Toy Story GoldenEye Four Rooms Get Shorty Copycat
# 简单空白分词法:
movie_titles = raw_titles.map(lambda m: extract_title(m))
title_terms = movie_titles.map(lambda t: t.split(" "))
print(title_terms.take(5))
[['Toy', 'Story'], ['GoldenEye'], ['Four', 'Rooms'], ['Get', 'Shorty'], ['Copycat']]
我们需要创建一个字词典,实现词到一个整数序号的映射,以便能为每一个词分配一个对应到向量元素的序号.
# 首先使用Spark的flatMap函数来扩展title_terms RDD中每个记录的字符串列表,以得到一个新的字符串RDD.该RDD的每个记录是一个名为all_terms的词.
# 之后取回所有不同的词,并给他们分配序号.其做法和之前对职业进行k之1编码完全相同:
#取回所有可能的词,以便构建一个词到序号的映射字典
all_terms = title_terms.flatMap(lambda x: x).distinct().collect()
# 创建一个新的字典来保存词,并分配k之1序号
idx = 0
all_terms_dict = {}
for term in all_terms:
all_terms_dict[term] = idx
idx += 1
print("Total number of terms: %d" % len(all_terms_dict))
print("Index of term 'Dead': %d" % all_terms_dict['Dead'])
print("Index of term 'Rooms': %d" % all_terms_dict['Rooms'])
Total number of terms: 2645 Index of term 'Dead': 9 Index of term 'Rooms': 2
也可以通过Spark的zipWithIndex函数来更高效得到相同结果:以各值的RDD为输入,对值进行合并,生成新的键值对RDD,其主键为词,值为词在词字典中的序号.用collectAsMap将该RDD以Python的dict函数形式返回到驱动程序.
all_terms_dict2 = title_terms.flatMap(lambda x: x).distinct().zipWithIndex().collectAsMap()
print("Index of term 'Dead': %d" % all_terms_dict2['Dead'])
print("Index of term 'Rooms': %d" % all_terms_dict2['Rooms'])
Index of term 'Dead': 9 Index of term 'Rooms': 2
最后一步是创建一个函数.该函数将一个词集合转换为一个稀疏向量的表示. 具体实现时,会创建一个空白稀疏矩阵,该矩阵只有一行,列数为字典的总词数. 之后逐一检查输入集合中的每一个词,看它是否在词字典中.如果在,就给矩阵里相应序数位置的向量赋值1:
# 该函数输入一个词列表,并用k之1编码类似的方式将其编码为一个scipy稀疏向量
def create_vector(terms, term_dict):
from scipy import sparse as sp
num_terms = len(term_dict)
x = sp.csc_matrix((1, num_terms))
for t in terms:
if t in term_dict:
idx = term_dict[t]
x[0, idx] = 1
return x
# 对提取出的各个词的RDD的各记录都应用该函数
all_terms_bcast = sc.broadcast(all_terms_dict) #该字典可能会极大
# print(title_terms.take(5))
# print(all_terms_bcast.value)
term_vectors = title_terms.map(lambda terms: create_vector(terms, all_terms_bcast.value))
term_vectors.take(5)
[<1x2645 sparse matrix of type '<class 'numpy.float64'>' with 2 stored elements in Compressed Sparse Column format>, <1x2645 sparse matrix of type '<class 'numpy.float64'>' with 1 stored elements in Compressed Sparse Column format>, <1x2645 sparse matrix of type '<class 'numpy.float64'>' with 2 stored elements in Compressed Sparse Column format>, <1x2645 sparse matrix of type '<class 'numpy.float64'>' with 2 stored elements in Compressed Sparse Column format>, <1x2645 sparse matrix of type '<class 'numpy.float64'>' with 1 stored elements in Compressed Sparse Column format>]
现在每一个电影标题都被转换为一个稀疏向量.可以看到那些提取出了2个词的标题所对应的向量里也是2个非零元素,而只提取了1个词的则只对应到了1个非零元素.
4.5 正则化特征
在将特征提取为向量形式后,一种常见的预处理方式是将数值数据正则化(normalization).其背后的思想是将各个数值特征进行转换,以将它们的值域规范到一个标准区间内.正则化的方法有如下几种:
- **正则化特征:**这实际上是对数据集中的单个特征进行转换.比如减去平均值(特征对齐)或是进行标准的正则转换(以使得该特征的平均值和标准差分别为0和1).
- **正则化特征向量:**这通常是对数据中的某一行的所有特征进行转换,以让转换后的特征向量的长度标准化.也就是缩放向量中的各个特征以使得向量的范数为1(常指一阶或二阶范数).
下面将用第二种情况举例说明:
# 向量正则化可通过numpy的norm函数来实现.
# 先计算一个随机向量的二阶范数,然后让向量中的每一个元素都除该范数,从而得到正则化后的向量:
np.random.seed(42) # 如果不设置随机种子值,则生成随机数因时间差异而不同.
x = np.random.randn(10)
norm_x_2 = np.linalg.norm(x)
normalized_x = x / norm_x_2
print("x:\n%s" % x)
print("2-Norm of x: %2.4f" % norm_x_2)
print("Normalized x:\n%s" % normalized_x)
print("2-Norm of normalized_x: %2.4f" % np.linalg.norm(normalized_x))
x: [ 0.49671415 -0.1382643 0.64768854 1.52302986 -0.23415337 -0.23413696 1.57921282 0.76743473 -0.46947439 0.54256004] 2-Norm of x: 2.5908 Normalized x: [ 0.19172213 -0.05336737 0.24999534 0.58786029 -0.09037871 -0.09037237 0.60954584 0.29621508 -0.1812081 0.20941776] 2-Norm of normalized_x: 1.0000
用MLlib正则化特征 Spark在其MLlib机器学习库中内置了一些函数用于特征的缩放和标准化.它们包括供标准正态变换的StandardScaler,以及提供与上述相同的特征向量正则化的Normalizer.
from pyspark.mllib.feature import Normalizer
normalizer = Normalizer() # 导入所需类后,初始化
vector = sc.parallelize([x])
normalized_x_mllib = normalizer.transform(vector).first().toArray()
print("x:\n%s" % x)
print("2-Norm of x: %2.4f" % norm_x_2)
print("Normalized x MLlib:\n%s" % normalized_x_mllib)
print("2-Norm of normalized_x_mllib: %2.4f" % np.linalg.norm(normalized_x_mllib))
x: [ 0.49671415 -0.1382643 0.64768854 1.52302986 -0.23415337 -0.23413696 1.57921282 0.76743473 -0.46947439 0.54256004] 2-Norm of x: 2.5908 Normalized x MLlib: [ 0.19172213 -0.05336737 0.24999534 0.58786029 -0.09037871 -0.09037237 0.60954584 0.29621508 -0.1812081 0.20941776] 2-Norm of normalized_x_mllib: 1.0000
###4.6 用软件包提取特征 Spark支持Scala,Java和Python的绑定.我们可以通过这些语言所开发的软件包,借助其中完善的工具箱来实现特征的处理和提取,以及向量表示.
特征提取可借助的软件包有scikit-learn, gensim, scikit-image, matplotlib, Python的NLTK, Java编写的OpenNLP以及用Scala编写的Breeze和Chalk.实际上,Breeze自Spark 1.0开始就成为Spark的一部分了.















 1254
1254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









