







 在高并发环境中,分布式缓存如Memcache用于减轻数据库压力和提高响应速度。 Memcache采用key-value存储,利用LRU算法管理内存。分布式架构通过一致性哈希算法解决服务器增减引起的键映射变动问题,分布式session同步确保集群间会话一致,同时讨论了缓存容灾措施。
在高并发环境中,分布式缓存如Memcache用于减轻数据库压力和提高响应速度。 Memcache采用key-value存储,利用LRU算法管理内存。分布式架构通过一致性哈希算法解决服务器增减引起的键映射变动问题,分布式session同步确保集群间会话一致,同时讨论了缓存容灾措施。
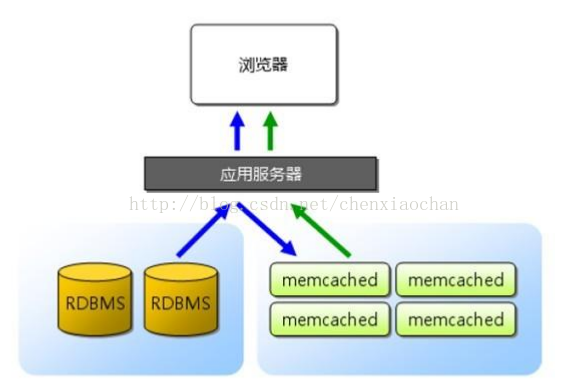
高并发环境下,大量的读写请求涌向数据库,磁盘的处理速度与内存显然不在一个量级,从减轻数据库的压力和提高系统响应速度两个角度来考虑,一般都会在数据库之前加一层缓存。由于单台机器的内存资源以及承载能力有限,并且,如果大量使用本地缓存,也会使相同的数据被不同的节点存储多份,对内存资源造成较大的浪费,因此,才催生出了分布式缓存。
Memcache
memcache是一款开源的高性能的分布式内存对象缓存系统,用于在应用中减少对数据库的访问,提高应用的访问速度,并降低数据库的负载。为了在内存中提供数据的高速查找能力,memcache使用key-value的形式存储和访问数据,在内存中维护一张巨大的HashTable,使得对数据查询的时间复杂度降低到O(1),保证了对数据的高性能访问。内存的空间总是有限的,当内存没有更多的空间来存储新的数据时,memcache就会使用LRU(LeastRecently Used)算法,将最近不常访问的数据淘汰掉,以腾出空间来存放新的数据。
memcache存储支持的数据格式也是灵活多样的,通过对象的序列化机制,可以将更高层抽象的对象
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1085
1085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









