







CentOs7搭建基于Redis-4.0.2的集群环境之图文详解
前言:
我在当前的项目建设过程中,使用到了 Redis 的集群,主要是用来减轻数据库的压力和页面加载速度,说的直接点就是增强用户的体验感,其实 Redis 集群搭建看似简单(我当时也是这么想的),但在实际 Redis 集群搭建的过程中也遇到了一些问题,但通过不懈的努力再加上各种解决问题的手段,最后终于解决了。
为了帮助广大同行也是为了帮助自己,在实际的开发过程中提高开发效率和解决 Redis 集群搭建过程中遇到的一些问题,所以我特意的将 Redis 集群搭建编写为教程,搭建的过程中遇到的问题及解决办法也记录了下来并以博文的形式呈现出来供大家参考,如果不足之处请指出,我会及时加以改正。
在这儿我是用的是Redis最新版本 Reids-4.0.2,Redis 4.0 于今年2017年7月发布。包含几大改进:一个模块系统,更好的复制 (PSYNC2),混合 RDB + AOF 格式,新的记忆命令,同步,集群支持 Nat,活跃的记忆碎片整理,内存使用和性能改进,更快的数据同步等。如果你对 Redis 的安装、数据库操作、数据类型、数据模型及内存优化等还不了解的可以参考 《CentOs7安装与配置Redis服务器详情图文详解 》 在以上这篇博文对以上列举内容作了具体的介绍,如果写得不到之处,我们可以一起探讨,谢谢!!!本片博文是继 《 Redis的单机版 》 之后更上一个层次的教程,Reids集群的搭建,本教程使用的是最新的 CentOs7 及最新 Reids-4.0.2。
声明:
一个合格的集群至少需要三个或三个以上节点组成,按照常规创建三个节点,每个节点一主一备,至少也要6台虚拟机。我的硬件设备承载能力有限,在此用一台虚拟机搭建一个 Redis 的伪分布式集群,使用 6 个 Redis 实例来模拟。和实际的项目开发中,在条件允许的情况下,使用6台服务器一样的操作都能实现。
一、搭建集群需求环境配置
需要使用官方提供的 Ruby 脚本,安装 Ruby 环境,(注意安装 ruby 环境前,先 " yum update "一下,确保服务器上的工具包都是最新的),输入命令 " yum install ruby "和 " yum install rubygems " 进行安装,如下图:

找到 Redis 集群管理工具 " redis-trib.rb " ,这个一看后缀一般都知道是Ruby编写的一个程序,他的主要作用就是将Redis 的各个节点串联起来组成一Redis集群,
那么这个工具在哪儿呢?需要下载吗?我来告诉你,找到 Redis 的解压包所在目录,输入 " cd redis/src/ " 进入 Redis的 src 目录,如下图:

二、搭建 Redis 集群
创建 Redis 实例存放目录 进入 local 目录,输入 " mkdir redis-cluster " 进行创建(cluster 目录你也可以自行定义,不一定要放在这个目录),如下图:
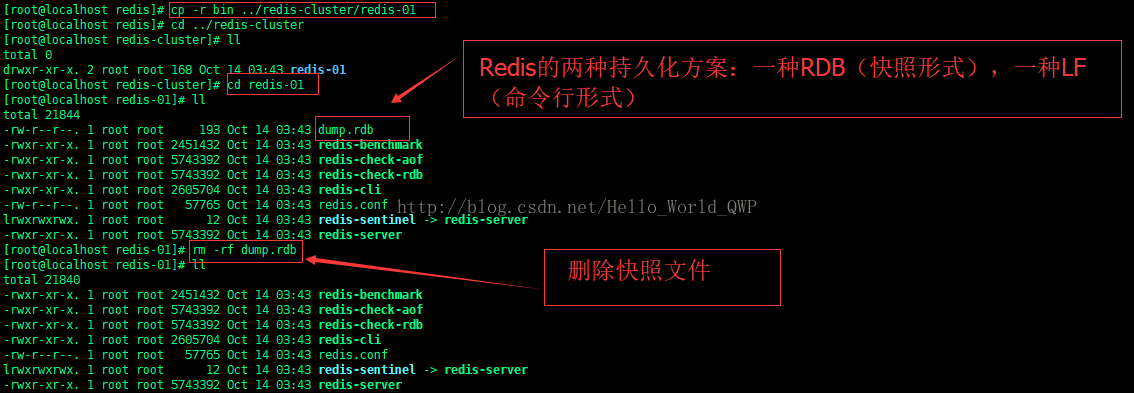
进入到以安装好的 Redis 单机版目录中,如果没有安装,请点击 《 安装Redis 》,将 bin Copy 到 redis-cluster 目录下,并新建 redis-01,
输入命令 " cp -r bin ../redis-cluster/redis-01 " 进行 Copy,
然后进入到 redis-01目录中,删除 Redis 的快照文件,输入命令 " rm -rf dump.rdb " 进行删除,如下图:
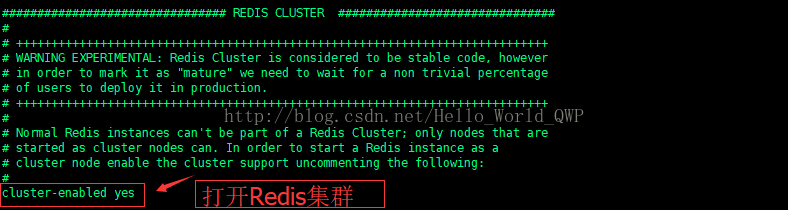
修改 Redis 的端口号,取消 Redis 集群注解 cluster-enabled yes,表示启用 Redis 集群,
输入命令 " vi redis.conf " 进行修改,如下图:

注意:我这儿使用的端口号范围 9001~9006 ,当然你也可以自己定义。
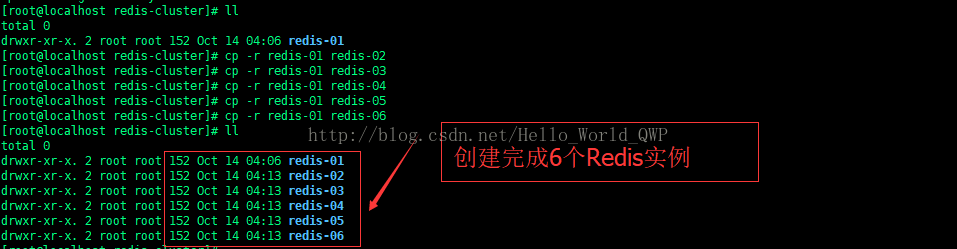
创建 6 个 Redis 实例,已创建完成一个,将当前Redis实例再Copy 5 即可,输入命令 " cp -r redis-01 redis02~06 " 进行创建,实例创建完成后,修改端口号和上面一样,这儿就不再提了,如下图:
将 ruby 脚本拷贝到 redis-cluster 目录中,输入命令 " cp -r redis-trib.rb /usr/local/redis-cluster " 进行 Copy,如下图:

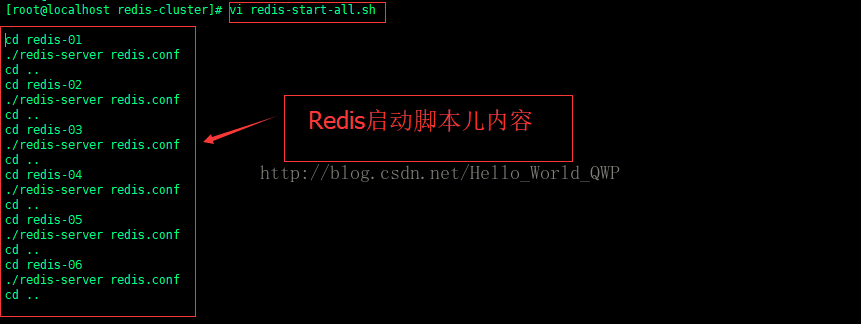
创建集群前,启动这 6 个 Redis 实例,单个启动太麻烦,先创建一个 Redis 启动脚本儿,输入命令 " vi redis-start-all.sh " 进行创建,如下图:
使用 chmod 函数,将 redis-start-all.sh 设置成可执行文件,
输入命令 " chmod +x redis-start-all.sh " 进行设置,如下图:

使用 redis 启动脚本儿,输入命令 " ./redis-start-all.sh " 进行启动,启动完成后,检查是否启动完成,
输入命令 " ps aux|grep redis " 查看,发现 6 个 Redis 实例正常启动成功,如下图:

全部 Redis 启动成功后,
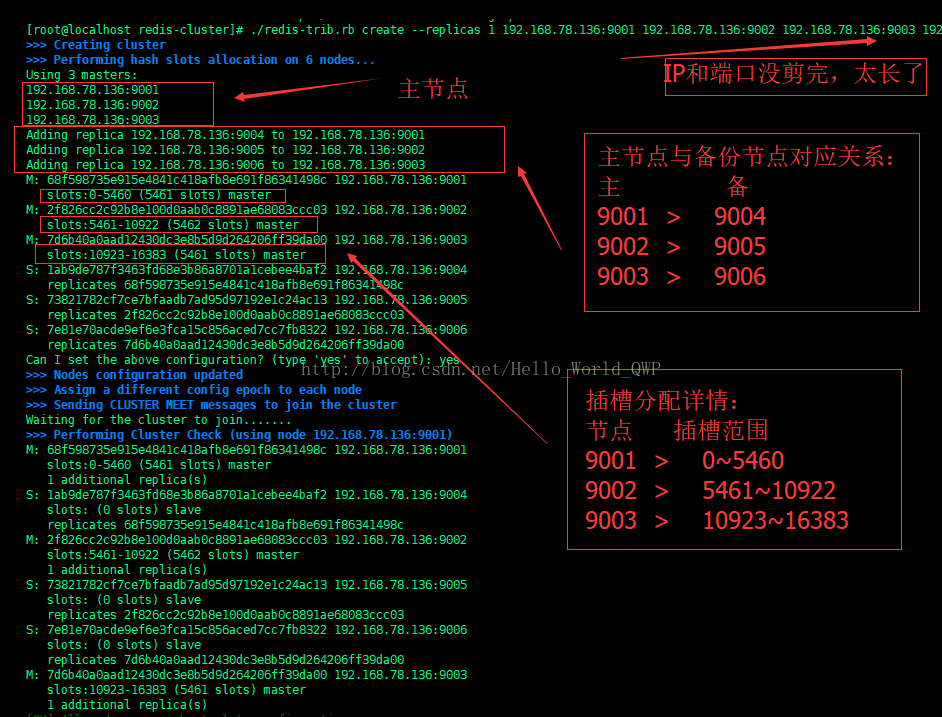
输入命令 " ./redis-trib.rb create --replicas 1 192.168.78.136:9001 192.168.78.136:9002 192.168.78.136:9003 192.168.78.136:9004 192.168.78.136:9005 192.168.78.136:9006 " 创建 cluster,创建成功后如下图:
Redis Cluster 创建成功后,可以尽情的享受你的成功了,
输入命令 " redis-01/redis-cli -c -h 192.168.78.136 -p 9001 " 集群链接成功后,就可以 set/get,如下图:

创建 Redis 集群遇到的问题:
问题一:

解决办法:《 安装 Ruby 接口 》
问题二:

解决办法:《 升级 Ruby 版本 》
问题三:
输入 " ./redis-trib.rb create --replicas 1 192.168.78.136:9001 192.168.78.136:9002 192.168.78.136:9003 192.168.78.136:9004 192.168.78.136:9005 192.168.78.136:9006 " 命令创建 Redis-Cluster 失败!
如下图:

解决办法:《 Redis-Cluster 创建失败解决办法 》
Redis 集群搭建总结:
一、关于 Redis 集群
redis 集群在启动的时候就自动在多个节点间分好片。同时提供了分片之间的可用性:当一部分 redis 节点故障或网络中断,集群也能继续工作。但是,当大面积的节点故障或网络中断(比如大部分的主节点都不可用了),集群就不能使用(节点之间存在着投票的制度,这就是Redis集群为什么至少需要三个节点的缘故)。
所以,从实用性的角度,Redis 集群提供以下功能:
1)、自动把数据切分到多个 redis 节点中 ;
2)、当少部分节点挂了或不通,集群依然能继续工作;
二、关于 redis 的主从模式
为了保证在部分节点故障或网络不通时集群依然能正常工作,集群使用了主从模型,每个哈希槽有一(主节点)到N个副本(N-1个从节点)。在我们刚才的 Redis 集群搭建教程,使用了三个节点,如果节点 01 故障集群就不能正常工作了,因为节点 02 中的哈希槽数据没法操作。但是,如果我们给每一个节点都增加一个从节点,就变成了:(01、02、03)这三个节点是主节点,04、05、06 分别为 01、02、03 的从节点,当其中某个节点挂掉时,集群依然能够正常运作。例如:04 节点是 01 节点的从节点,如果 01 节点故障,集群会将 04 从节点升级为主节点,从而让集群继续正常工作。但是,如果 01 和 04 同时挂掉,那么这个 Redis 集群就不能继续正常运作了。Redis 集群的一致性保证 :
Redis 集群不能保证一致性。比如一个已经向客户端确认写成功的操作,可能会在某些不确定因素的条件下导致操作数据丢失。
造成写操作数据丢失的原因:
是因为主从节点之间通过异步的方式来同步数据。
向 Redis 集群一个写的动作流程:1)客户端向主节点 01 发起写的操作 2)主节点 01 响应客户端写操作成功 3)主节点 01 向它的从节点 04 同步该写的动作。从上面写的流程来看,主节点 01 并没有等从节点 04 写完之后再回复客户端的写操作结果。而是先响应客户端后再将写的动作同步到从节点 04,所以,如果主节点 01 在通知客户端写操作成功之后,但同步给从节点 04 之前,主节点 01 挂了,未将写操作结果同步到从节点,那么当 04 从节点提为主节点时,该写操作就会永远丢失。 就像传统的数据库,在不涉及到分布式的情况下,它每隔一秒向磁盘写一次。为了提高一致性,在写磁盘完成之后再响应客户端,但这样就极大的降低了系统性能。这种写磁盘的方式就等于 Redis 集群中主节点向从节点同步写操作的过程。 所以在性能和一致性之间,需要择其一,鱼和熊掌不能兼得!
三、关于 Redis 集群数据分片
Redis 集群不是使用一致性哈希,而是使用哈希槽。整个 redis 集群有 16384 个哈希槽,决定一个 key 应该分配到那个槽的算法是:计算该 key 的 CRC16 结果再模 16384。
集群中的每个节点负责一部分哈希槽,例如上例中集群有 3 个节点,则:
1)、节点 01 存储的哈希槽范围是:0 ~ 5460
2)、节点 02 存储的哈希槽范围是:5461 ~10922
3)、节点 03 存储的哈希槽范围是:10923~16383
这样的分布方式方便节点的添加和删除。比如,需要新增一个节点 07,只需要把 01、02、03 中的部分哈希槽数据移到 07 节点。同样,如果希望在集群中删除01节点,只需要把 01 节点的哈希槽的数据移到 02 和 03 节点,当 01 节点的数据全部被移走后,01 节点就可以完全从集群中删除。
因为把哈希槽从一个节点移到另一个节点是不需要停机的,所以,增加或删除节点,或更改节点上的哈希槽,都是不需要停机的。
如果多个key都属于一个哈希槽,集群支持通过一个命令、事务或lua脚本同时操作这些key。通过“哈希标签”的概念,用户可以让多个key分配到同一个哈希槽。
哈希标签Redis中国官网(Redis china)的集群文档中有详细的描述,在这里只做个简单介绍:如果key含有大括号”{}”,则只有大括号中的字符串会参与哈希,比如”manager{util}”和”company{util}”这两个key会分配到同一个哈希槽,所以可以在一个命令、事务或lua脚本中同时操作他们。















 1202
1202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









