








 本文详细介绍了如何实现一个简单的决策树算法,包括数据集的获取、信息熵和信息增益的计算、决策树的绘制以及分类预测。通过实例展示了如何对苹果和杨桃的特征进行分析,构建决策树模型,并进行预测。最后,给出了一个决策树的字典表示和预测示例。
本文详细介绍了如何实现一个简单的决策树算法,包括数据集的获取、信息熵和信息增益的计算、决策树的绘制以及分类预测。通过实例展示了如何对苹果和杨桃的特征进行分析,构建决策树模型,并进行预测。最后,给出了一个决策树的字典表示和预测示例。
一、获取数据集
水果中苹果和杨桃外部特征比较鲜明,例如下面两张苹果、杨桃图片,苹果颜色为红色、形状大致为椭圆形、表面光滑没有棱角、带叶子,杨桃则是黄色、五角星形、带有棱角、没叶子。

利用上述特征统计一些苹果和杨桃数据:
- 颜色: 1-红色 0-黄色
- 形状: 1-椭圆形 0-五角星形
- 棱角: 1-有棱角 0-无棱角
- 带叶: 1-带叶子 0-不带叶子
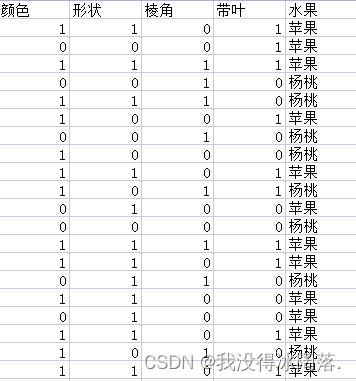
1、提取数据
利用CSV库将指定特征分类,将除去第一行的数据提取出来,作为本次实验的数据集

其中第一行就是决策树的每一个节点,存到lables中;再将特征对应每一种情况存到了labels中。

# 获取数据集
def createDataSet(filename):
# 读取文件
data = open(filename, 'rt', encoding='gbk')
reader = csv.reader(data)
# 获取标签列
handlers = next(reader)
lables = handlers[:-1]
# 数据列表
dataSet = []
for row in reader:
# 读取除第一行的数据
dataSet.append(row[:])
# 特征对应的所有可能的情况
labels_full = {
}
for i in range(len(lables)):
labelList = [example[i] for example in dataSet]
uniqueLabel = set(labelList)
labels_full[lables[i]] = uniqueLabel
return dataSet, lables, labels_full
2、划分数据
dataSet输入的数据,axis是labels中对应坐标,value是对应属性下的属性值。
# 划分数据集
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
# 给定特征值等于想要的特征值
if 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











