






文章目录
2. 爬虫设计
爬虫设计是数据收集过程中至关重要的环节,直接影响到数据的质量和数量。下面详细介绍爬虫设计的各个方面,包括爬虫工具选择、爬虫策略、反爬机制应对、数据提取与存储、数据清洗等内容。通过精心设计和实施爬虫,我们将确保从去哪儿网、马蜂窝和小红书等平台高效获取高质量的旅游数据。
2.1 马蜂窝爬虫
2.1.1 爬虫工具选择
- 编程语言:Python
- 爬虫框架:Selenium(用于浏览器自动化)
- 解析库:BeautifulSoup(用于解析HTML)
2.1.2 爬虫策略
- 目标网站:马蜂窝(https://www.mafengwo.cn/)
- 目标数据:山东地区的攻略和游记
- 流程概述:
- 打开马蜂窝首页并进行搜索。
- 提取搜索结果页面中的攻略和游记链接。
- 分别访问每个攻略和游记页面,提取内容并保存到本地文件。
2.1.3 反爬机制应对
-
模拟用户行为:
- 使用随机时间间隔(
time.sleep(random.randint(0, 3)))来避免频繁请求。
- 使用随机时间间隔(
-
隐藏自动化痕迹:
-
设置ChromeOptions,排除
enable-automation开关,并禁用自动化控制的特性:options.add_experimental_option('excludeSwitches', ['enable-automation']) options.add_argument("--disable-blink-features=AutomationControlled")
-
2.1.4 数据提取与存储
-
步骤详解:
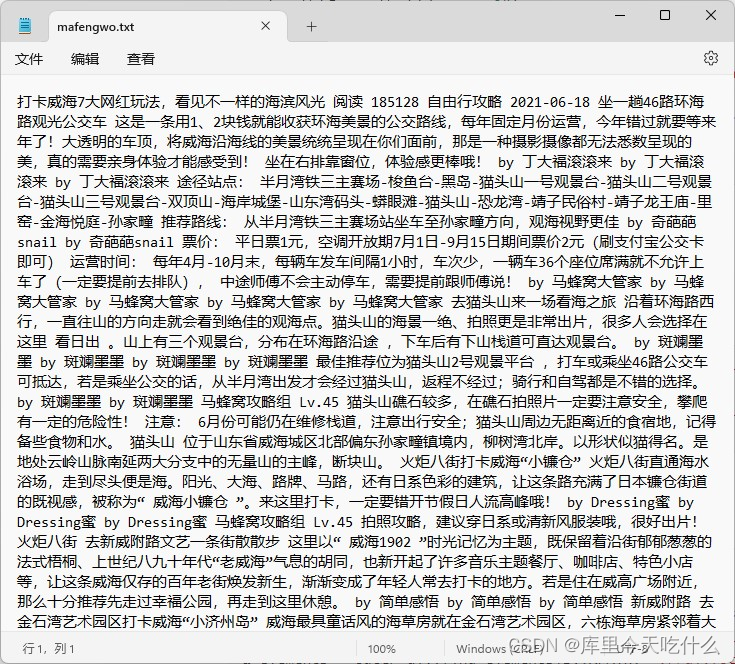
代码用于从马蜂窝网站上抓取与“山东”相关的攻略和游记内容,并将这些内容保存到本地文件中。
以下是对代码的详细分析:导入必要的模块
import random import time from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC- 导入
random和time模块用于随机等待时间和强制等待时间。 BeautifulSoup用于解析网页内容。selenium及其相关模块用于控制浏览器、查找元素以及等待特定条件。
配置文件路径和ChromeDriver路径
file_path = 'C:\\Users\\okk\\Desktop\\mafengwo.txt' chrome_driver_path = 'D:\\App\\chromedriver\\chromedriver.exe'file_path为保存抓取内容的文件路径。chrome_driver_path为ChromeDriver的路径,用于控制Chrome浏览器。
初始化Selenium WebDriver
s = Service(chrome_driver_path) options = webdriver.ChromeOptions() options.add_experimental_option('excludeSwitches', ['enable-automation']) options.add_argument("--disable-blink-features=AutomationControlled") driver = webdriver.Chrome(service=s, options=options)- 使用
Service对象和指定的ChromeDriver路径创建一个Chrome服务对象。 - 设置浏览器选项以绕过一些反爬机制。
- 初始化Chrome WebDriver实例。
打开马蜂窝网站并搜索“山东”
driver.get("https://www.mafengwo.cn/") driver.maximize_window() wait = WebDriverWait(driver, 10) wait.until(EC.visibility_of_element_located((By.ID, '_j_index_search_input_all'))) start_input = driver.find_element(By.ID, '_j_index_search_input_all') start_input.send_keys('山东') search_button = driver.find_element(By.ID, '_j_index_search_btn_all') search_button.click() time.sleep(random.randint(0, 3))- 打开马蜂窝首页并最大化窗口。
- 等待搜索输入框出现并输入“山东”,然后点击搜索按钮。
- 随机等待一段时间以模拟正常用户行为。
获取攻略和游记的链接
element = driver.find_element(By.XPATH, '//*[@id="_j_mfw_search_main"]/div[1]/div/div/a[3]') notes = element.get_attribute('href') element = driver.find_element(By.XPATH, '//*[@id="_j_mfw_search_main"]/div[1]/div/div/a[4]') guides = element.get_attribute('href')- 使用XPath定位到“攻略”和“游记”链接,并获取它们的
href属性。
抓取攻略内容
driver.get(guides) wait = WebDriverWait(driver, 10) wait.until(EC.visibility_of_element_located((By.ID, '_j_search_result_left'))) outer_div = driver.find_element(By.ID, '_j_search_result_left') a_elements = outer_div.find_elements(By.XPATH, './/div[@class="flt1"]/a') hrefs = [a_element.get_attribute('href') for a_element in a_elements] for href in hrefs: driver.get(href) wait = WebDriverWait(driver, 10) wait.until(EC.visibility_of_element_located((By.CLASS_NAME, 'sideL'))) soup = BeautifulSoup(driver.page_source, 'html.parser') content_box = soup.find('div', class_='sideL') all_text = ' '.join(content_box.stripped_strings) with open(file_path, 'a', encoding='utf-8') as file: file.write(all_text + '\n') time.sleep(3)- 打开“攻略”链接并等待页面加载完成。
- 提取攻略页面中的所有相关链接。
- 遍历这些链接,逐个打开,等待内容加载完毕后,使用BeautifulSoup解析内容。
- 提取页面内容并保存到本地文件。
抓取游记内容
driver.get(notes) wait = WebDriverWait(driver, 10) wait.until(EC.visibility_of_element_located((By.ID, '_j_search_result_left'))) outer_div = driver.find_element(By.ID, '_j_search_result_left') a_elements = outer_div.find_elements(By.XPATH, './/div[@class="flt1"]/a') hrefs = [a_element.get_attribute('href') for a_element in a_elements] for href in hrefs: driver.get(href) wait = WebDriverWait(driver, 10) wait.until(EC.visibility_of_element_located((By.CLASS_NAME, '_j_content_box'))) soup = BeautifulSoup(driver.page_source, 'html.parser') content_box = soup.find(class_="_j_content_box") all_text = ' '.join(content_box.stripped_strings) with open(file_path, 'a', encoding='utf-8') as file: file.write(all_text + '\n') time.sleep(3)- 打开“游记”链接并等待页面加载完成。
- 提取游记页面中的所有相关链接。
- 遍历这些链接,逐个打开,等待内容加载完毕后,使用BeautifulSoup解析内容。
- 提取页面内容并保存到本地文件。
关闭浏览器
driver.quit()存储方式:
将提取的文本内容按行写入到指定文件路径:
file_path = 'C:\\Users\\okk\\Desktop\\mafengwo.txt' - 导入
2.1.5 数据展示
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









