









打算把两年前做的Android平台上的手写体数字识别软件的实现过程一步一步地写下来,提供完整的代码给和我当年一样对这种基础的模式识别毫无头绪的同学。不过我现在还是对这些算法一知半解。。。
整个算法处理流程如下:

首先是识别算法的数据集的准备,这里使用MNIST手写体图像集。MNIST是研究人员采集的很多很多不同的人手写的数字扫描成的图像集,包含60000个训练样本和10000个测试样本,每个样本是8位的灰度图像。可以从这里下载http://yann.lecun.com/exdb/mnist/,数据集包含训练集和测试集,分别包含图像文件和标签文件,训练集以如下的结构存储(测试集类似):
TRAINING SET LABEL FILE (train-labels-idx1-ubyte)
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte label
0009 unsigned byte label
........
xxxx unsigned byte label
The labels values are 0 to 9.
TRAINING SET IMAGE FILE (train-images-idx3-ubyte)
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte pixel
0017 unsigned byte pixel
........
xxxx unsigned byte pixel 一开始用的MATLAB,由于用的不太熟练,就改用C#进行处理了。首先提取灰度图像的像素点,然后根据设定的阈值(也可以采用动态阈值等方法)进行二值化,再进行归一化处理,原始灰度图像为28x28,裁编之后均为20x20的图像。
原始图像如下:
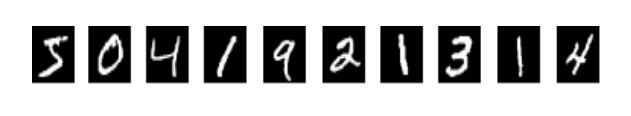
归一化之后的图像如下:
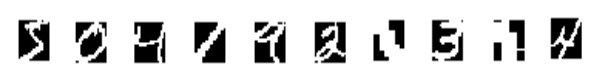
MNIST处理的代码可以在这里获取:
https://sourceforge.net/projects/andocrrecog/files/PreProcessMNIST/
经过处理后所有训练样本和测试样本都被转换成20x20的归一化图像。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









