







接到个小活,要实现一个局域网内的小服务器,需求如下:
1.实现静态文件下发功能,主要是apk安装包和html及其相关文件;
2.实现数据接口,用于存储和查询网内其他设备发来的数据;
3.实际使用者电脑能力一般,环境搭建和操作越简单越好。
最近在学Python,正好来练练手。话不多说,开搞!
开发环境:Windows7 + Python3.5.2
第一步,当然是要把服务器跑起来啦!
查了下原来超级简单,只要用命令行进入想作为服务器目录的目录,并运行如下命令:
python -m SimpleHTTPServer 8000查了下这个错误,原来SimpleHTTPServer是Python 2.X的模块,3.X中需要用http.server,于是修改如下:
python -m http.server 8080
再打开浏览器,访问http://127.0.0.1:8000/
果然看到了目录的文件列表。
在服务器目录里随便丢了个index.html,浏览器访问http://127.0.0.1:8000/index.html:
成功!
第二步,用Python代码跑服务器
命令行一句话的事,用代码当然也很简单:
import http.server as hs
httpAddress = ('', 8000)
httpd = hs.HTTPServer(httpAddress, RequestHandler)
httpd.serve_forever()其中httpAddress为(url, port)的格式,url为空表示指向本机默认地址127.0.0.1,8000是端口号,改成其他未被占用的也可以。
那么RequestHandler是什么呢?
第三步,实现RequestHandler
RequestHandler其实是对http.server.BaseHTTPRequestHandler这个基础类的继承,即对http请求的响应。但它本身不包含任何方法,需要自行实现。
项目中没有用到post请求,因此只需实现do_GET方法:
import os
import http.server as hs
class RequestHandler(hs.BaseHTTPRequestHandler):
def do_GET(self):
self.full_path = os.getcwd() + self.path
print(self.path)
print(self.full_path)
pass
httpAddress = ('', 8000)
httpd = hs.HTTPServer(httpAddress, RequestHandler)
httpd.serve_forever()
第四步,区分请求类型
获取访问地址后,当然是根据后缀名区分请求类型并各自处理咯。
结合需求和逻辑,服务器需要依照先后顺序判断并处理以下几类:
1.请求的文件不存在时,抛回错误页面并提示错误原因;
2.请求指向某个数据接口时,执行指定的python脚本并返回结果;
3.请求指向某个文件时,返回该文件;
4.以上情况皆不符合,抛回错误页面并提示错误原因。
项目中对这些请求分别建立包含test和act两个方法的类并一次调用,类似于:
cases = [case1(), case2(), case3(), case4()]
for case in cases:
if case.test(self):
case.act(self)
break接下来就是实现每种请求的处理啦!以下几个是重点:
第五步,请求指定文件
前面已经拿到了请求文件的绝对地址,通过文件IO方法即可判断目标文件是否存在。
若文件存在,则读取文件内容并写入请求文件对象(通过self.wfile获取),对终端来说即是返回了该文件。
html文件里通常会包含css、js、图片、音频等各种引用,但实际访问时浏览器会自动对其所有引用文件单独发起get请求,所以服务器这边无需特殊对待,当做数个独立的文件请求来处理就行。
但是要注意,如果地址是类似url?param1=value1¶m2=value2的形式,判断和返回文件内容时需要先把后面的参数部分截掉。代码如下:
def handle_file(self, full_path):
try:
#处理过程中需先截掉参数,否则会判断为文件不存在
full_path = full_path.split("?")
full_path = full_path[0]
#判断文件类型以设置mimetype
mimetype = ""
if self.path.endswith(".html"):
mimetype='text/html'
if self.path.endswith(".jpg"):
mimetype='image/jpg'
if self.path.endswith(".png"):
mimetype='image/png'
if self.path.endswith(".gif"):
mimetype='image/gif'
if self.path.endswith(".js"):
mimetype='application/javascript'
if self.path.endswith(".css"):
mimetype='text/css'
if self.path.endswith(".apk"):
mimetype='application/vnd.android.package-archive'
self.send_response(200)
self.send_header('Content-type', mimetype)
self.end_headers()
with open(full_path, 'rb') as f:
self.wfile.write(f.read())
except IOError as msg:
msg = "'{0}' cannot be read: {1}".format(self.path, msg)
self.handle_error(msg)往文件夹里丢了张小图片,试着访问下:
再试试访问下包含这个文件的页面:
成功!
第六步,请求数据接口
数据接口的实现思路也很简单:
1.服务器上准备好所需的python脚本,对应不同数据接口的功能
2.终端直接以url+参数的形式访问数据接口(即对应的Python脚本);
3.服务器判断出这种情况后,执行该Python脚本并传入参数;
4.Python脚本被执行,根据参数对目标文件(或数据库)进行增删改查等操作;
5.Python脚本的执行结果以文本方式传回,作为本次数据请求的回调。
import argparse
try:
parser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument('--id', type = int, default = -1)
parser.add_argument('--name', type = str, default = None)
args = parser.parse_args()
if args.id < 0:
print('{"result":"False","msg":"invalid id"}')
else:
id = args.id
name = args.name
name = name.encode(encoding = "utf-8")
print('{"result":"True","id":"%d","name":"%s"}' %(id, name))
except BaseException as e:
print('{"result":"False","msg":"%s"}' %str(e))其中,脚本调用是通过subprocess.check_output()方法实现的。该方法会创建一个子进程以命令行方式执行指定的指令或脚本,父进程会等待其执行完毕并返回输出结果。
为了与传统接口形式统一,项目中的http请求参数是以?param1=value1¶m2=value2的形式传递的;但调用Python脚本时,参数需要以--param1=value1{空格}--param2=value2……的形式传递,因此需要对其进行转换。
实现以上功能的代码如下:
def run_cgi(self, fullpath):
#运行脚本并得到格式化的输出
#参数以url?param1=1¶m2=2……的方式传递
path = fullpath.split("?")
if len(path) > 1:
params = path[1]
params = params.split("&")
shell = []
shell.append("python")
shell.append(path[0])
for param in params:
shell.append("--" + param)
data = subprocess.check_output(shell)
else:
data = subprocess.check_output(["python", path[0]])
self.send_content(page = str(data, encoding = 'utf-8'))def send_content(self, page, status = 200):
self.send_response(status)
self.send_header("Content-type", 'text/html')
self.end_headers()
self.wfile.write(bytes(page, encoding = 'utf-8'))import argparse
try:
parser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument('--id', type = int, default = -1)
parser.add_argument('--name', type = str, default = None)
args = parser.parse_args()
if args.id < 0:
print('{"result":"False","msg":"invalid id"}')
else:
id = args.id
name = args.name
name = name.encode(encoding = "utf-8")
print('{"result":"True","id":"%d","name":"%s"}' %(id, name))
except BaseException as e:
print('{"result":"False","msg":"%s"}' %str(e))打开浏览器,访问该脚本并传入参数:
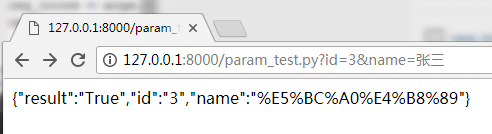
成功!
第七步,异常处理
经过上面几个步骤,服务功能基本搭得差不多了。剩下的就是处理下异常情况,即生成一个包含错误内容的html页面:
Error_Page = """
<html>
<meta http-equiv="content-type" content="text/html;charset=UTF-8" />
<body>
<h1>Error accessing {path}</h1>
<p>{msg}</p>
</body>
</html>
"""访问个空地址试一试:
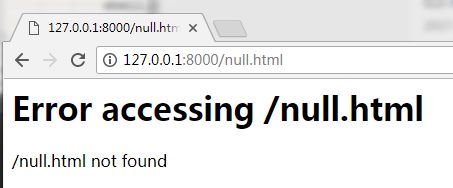
成功!
至此,全部功能完成。鞠躬。
项目源码:Python_Service
参考资料
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









