






1、创建一个core
- 前提在tomcat部署好solr,启动tomcat,访问solr,创建my_core
2.将solr-6.5.0/dist中的solr-dataimporthandler、solr-dataimporthandler-extras的jar包copy到tomcat\webapps\solr\WEB-INF\lib下;
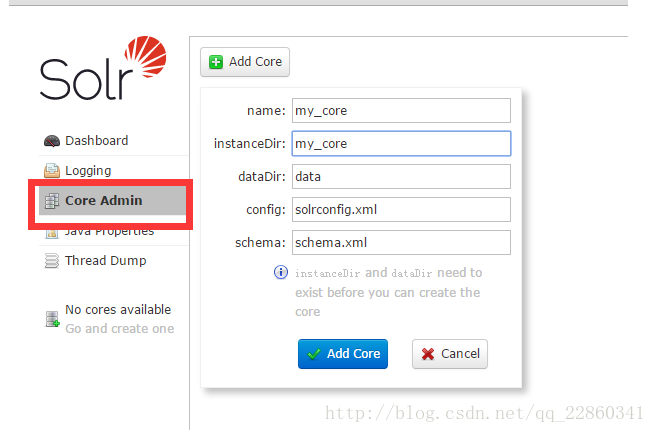
3.在solr_home目录下创建my_core文件夹(名称与下图的instanceDir一致,建议下图中的name也和该文件夹名一致);
4.在my_core文件夹下创建data和conf文件夹;
5.将solr-6.5.0\example\example-DIH\solr\solr\conf所有文件和文件夹都copy到solr_home\my_core\conf下;
6.如图所示,conf文件夹下必须包含solrcomfig.xml和schema.xml,若没有schema.xml, 将图所示文件改为schema.xml即可。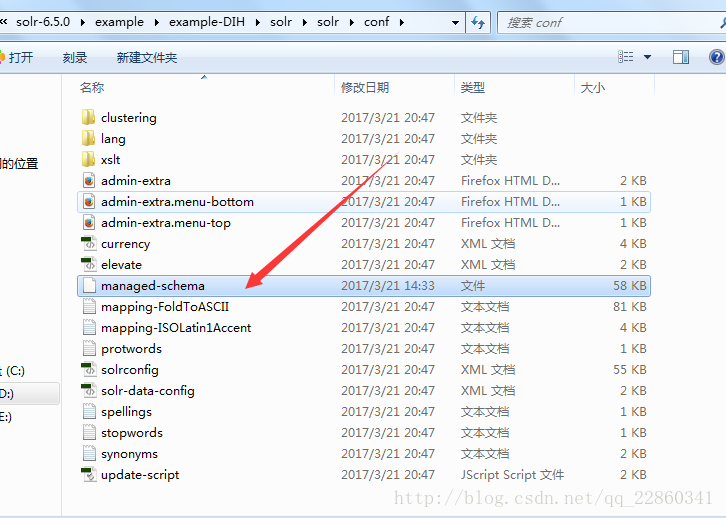
7.重启tomcat,创建my_core.
2、solr分词
- 这里使用的是mmseg4j 分词,
- 将文件里的jar包拷贝到Tomcat\webapps\solr\WEB-INF\lib下;
- 在 你的solr_home\ 目录下新建一个 dic 文件夹 , 把 新下载的词库(data文件夹下)拷贝到 dic 目录下;
- 在 solr_home\my_core\conf\schema.xml 文件的里添加如下:
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="D:/solrHome/dic"> </tokenizer> </analyzer> </fieldtype> <fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="maxword" dicPath="D:/solrHome/dic"> </tokenizer> </analyzer> </fieldtype> <fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="D:/solrHome/dic"> </tokenizer> </analyzer> </fieldtype> <field name="name" type="textMaxWord" indexed="true" stored="true" multiValued="true" /> <field name="description" type="textMaxWord" indexed="true" stored="true" multiValued="true" />
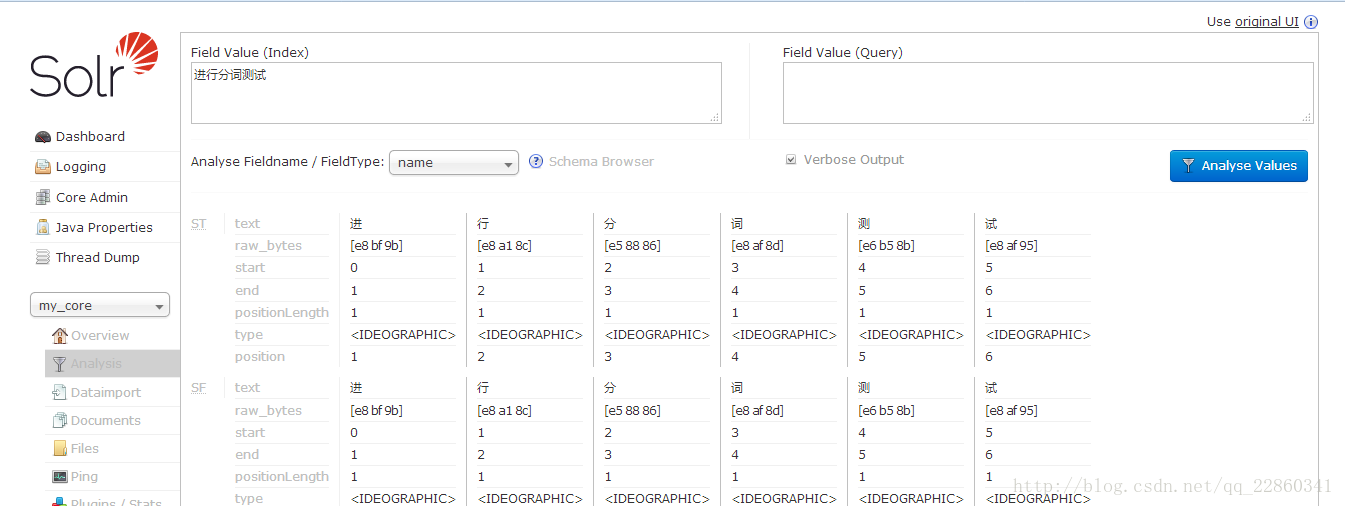
6.开启服务如下进行分词测试,如下图分词















 126
126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









