









目录
好了,那么上一篇文章我们大概了解了链表的性质以及基本结构
这里我们复习一下:
1.链表在逻辑结构上是连续的 , 在物理结构上不连续
2.结点一般是在堆上申请的
3.从堆上申请来的空间 , 是按照一定策略分配出来的 ,每次申请的空间可能连续 , 可能不连续。
那么这篇文章,我们就来具体探讨一下,如何手搓一个链表,以及链表的具体步骤有哪些。
打印单链表
首先
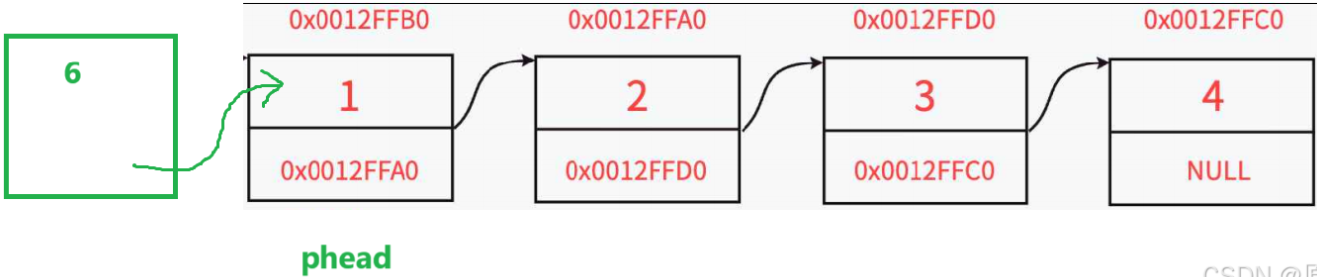
向内存中申请一个 结点大小 的空间

再是初始化结点数据(向结点中存储数据)

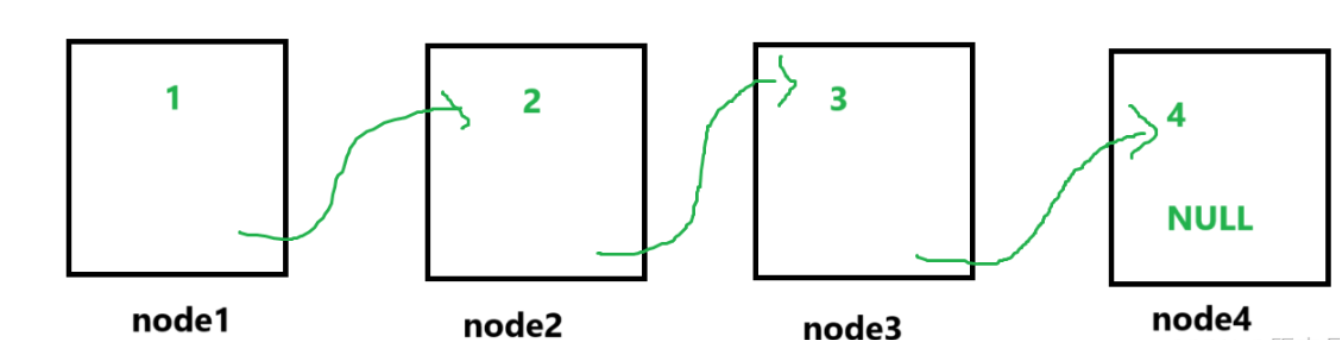
最后一步就是要把他们全部建立联系:

这里通过next指针把这四个节点串在一起。如果画成图的话就应该是这样:
#define _CRT_SECURE_NO_WARNINGS 1
#include "SList.h"
void Test()
{
//手动构造一个链表(结点)
SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node2 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node3 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node4 = (SLTNode*)malloc(sizeof(SLTNode));
//初始化
node1->data = 1;
node2->data = 2;
node3->data = 3;
node4->data = 4;
node1->next = node2;
node2->next = node3;
node3->next = node4;
node4->next = NULL;
}
int main()
{
Test();
return 0;
}以上就是具体的代码实现,那么我们放到vs2022里面一运行,出来的结果就是这样:

那么接下去就是第二个部分。
单链表的实现
1.尾插
在插入数据之前 , 链表中可能没有数据(空链表) , 可能存了数据(非空链表)
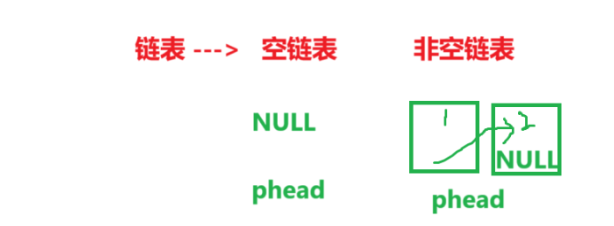
这就是空链表和非空链表的区别,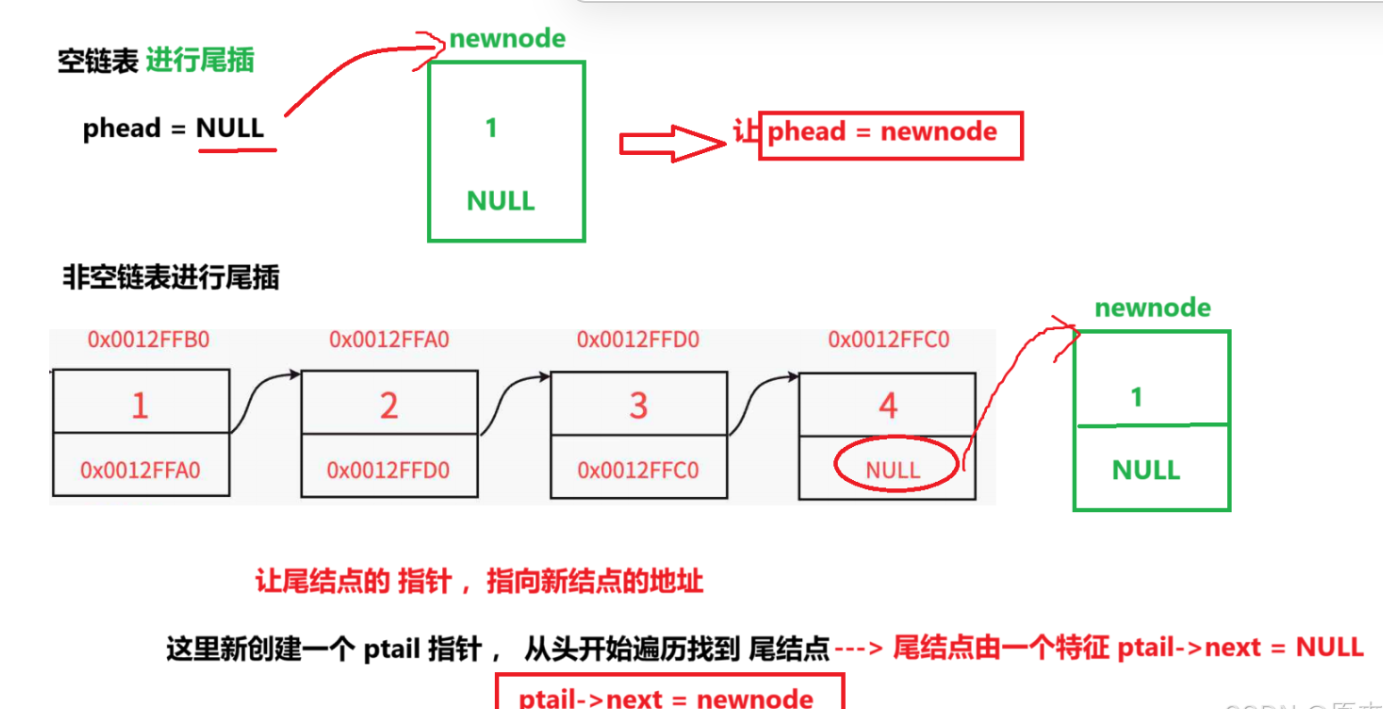 相应的,他们二者也有不同的尾插方法,但总体上一样,非空链表的话,因为我们说到他所在的物理意义上是不连续的,就像你的下级认识你,但是你的下下级可能就不会认识你一样,我的附庸的附庸不是我的附庸,这里就会牵扯到这样的一句经典的古话。所以需要有一个通信员去找到具体办事的人员
相应的,他们二者也有不同的尾插方法,但总体上一样,非空链表的话,因为我们说到他所在的物理意义上是不连续的,就像你的下级认识你,但是你的下下级可能就不会认识你一样,我的附庸的附庸不是我的附庸,这里就会牵扯到这样的一句经典的古话。所以需要有一个通信员去找到具体办事的人员
但是我们这里需要注意的点
1 . 无论是进行尾插,头插,还是在任意位置插入数据,都要 创建一个结点(向内存申请结点大小的空间) ,为了减少代码的重复书写 , 这里可以创建一个函数 STDBuyNode( )
//申请一个结点大小的空间
SLTNode* SLTBuyNode(SLTDateType x)
{
SLTNode* node = (SLTNode*)malloc(sizeof(SLTNode));
if (node == NULL)
{
perror("malloc fail!");
return 1;
}
node->data = x;
node->next = NULL;
return node;
}那我们直接来看一下链表尾插的代码
//尾插
void SLTPushBack(SLTNode** pphead, SLTDateType x)
{
SLTNode* newnode = SLTBuyNode(x);
//链表为空
if (*pphead == NULL)
{
*pphead = newnode;
}
//链表不为空 --> 找尾结点
else
{
SLTNode* ptail = *pphead;
while (ptail->next)//ptail->next != NULL
{
ptail = ptail->next;
}
ptail->next = newnode;
}
}那我们一看这个代码,嗬,还整上二级指针了,这是为什么呢?我这里的传参为什么不能直接用plist去赋值呢?就像这样
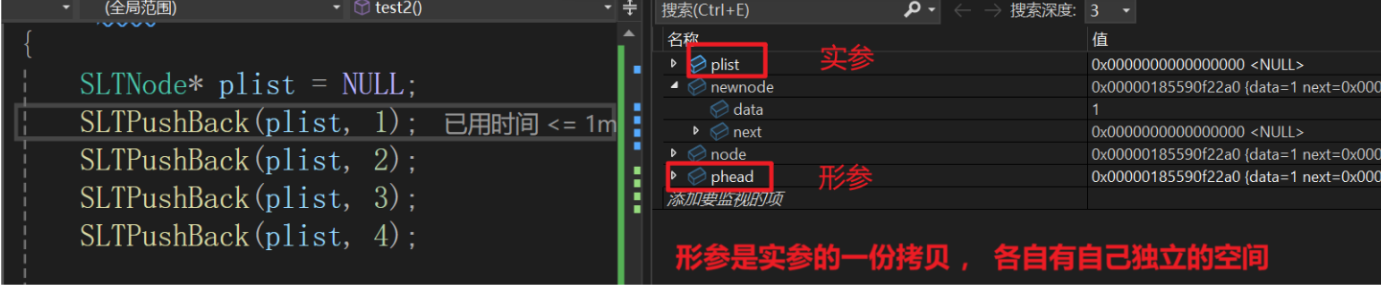 但是事实上也就跟我在图中标注的一样,plist 是结构体指针变量 , 存储的是地址 , 如果想要进行地址的传递 , 需要用到二级指针!(二级指针的理解并不会很难 , 一级指针存放的是地址 , 同样的,二级指针存放的也是地址(一级指针的地址)).
但是事实上也就跟我在图中标注的一样,plist 是结构体指针变量 , 存储的是地址 , 如果想要进行地址的传递 , 需要用到二级指针!(二级指针的理解并不会很难 , 一级指针存放的是地址 , 同样的,二级指针存放的也是地址(一级指针的地址)).
所以我们就得牢记一句话,为了更突出,用图片的方式放上来:

那接下来我们就再来看一下二级指针和一级指针的关系,也像是一个链表一样
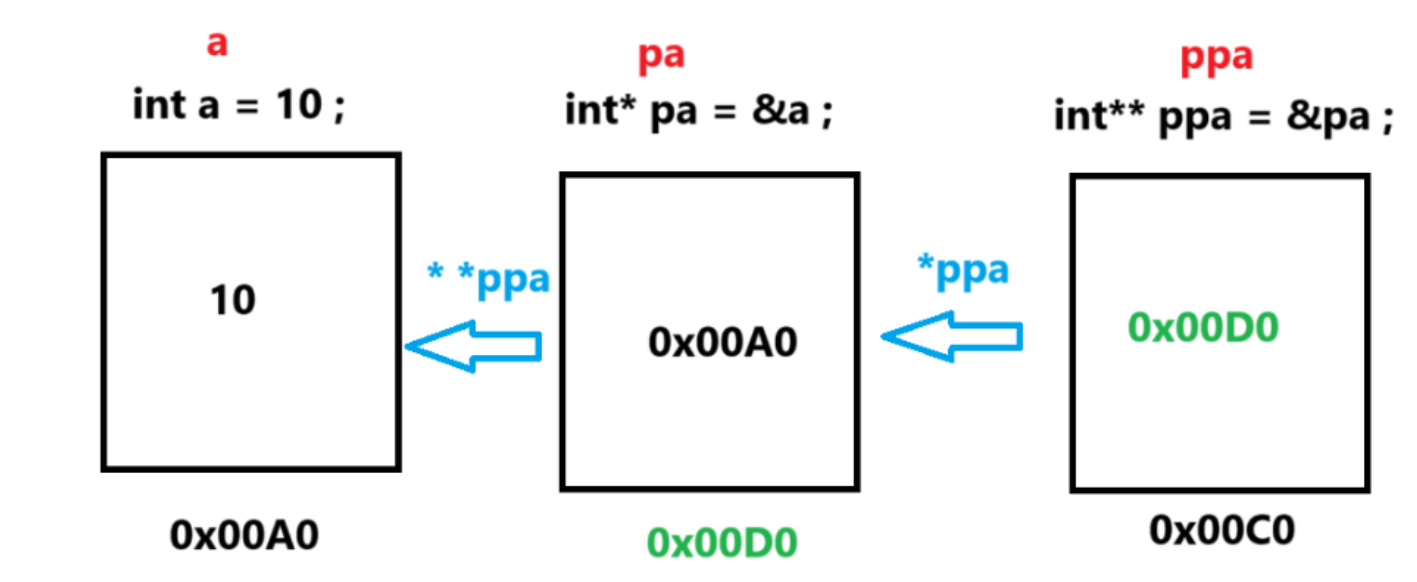

那么在这里,形参和实参对应的关系就很明确了。
2.头插
头插思路是什么呢?
1 . 先申请一块结点大小的空间 --> 新结点(newnode)
2 . 让 新结点 与 头结点 联系起来
3 . 让新结点成为 头结点
我们也说过,链表在物理意义上不连续,所以只需要让我们的新节点的指针域指向原来的头节点就可以了,也就是说换了个大领导,那原先的小领导还在,只要大领导跟小领导对接好工作,整条线还是能正常运行的。
//头插
void SLTPushFront(SLTNode** pphead, SLTDateType x)
{
assert(pphead);
SLTNode* newnode = SLTBuyNode(x);
newnode->next = *pphead;
*pphead = newnode;
}3.尾删
思路:
这里就出现了一个非常重要的细节:不能直接free 掉尾结点 ,因为尾结点的前一个结点的 next指针 依旧指向尾结点,直接free掉尾结点 , 会使next 指针变成野指针
1. 先遍历链表,找到尾结点
2. 存储尾结点前一个结点的next 值
3.让 next 的值 置为 NULL
4.free 掉 尾结点
注意 :当链表中只有一个结点的时候 , 进入不到循环中,此时的prev 依旧是NULL,对NULL解引用,程序会崩!
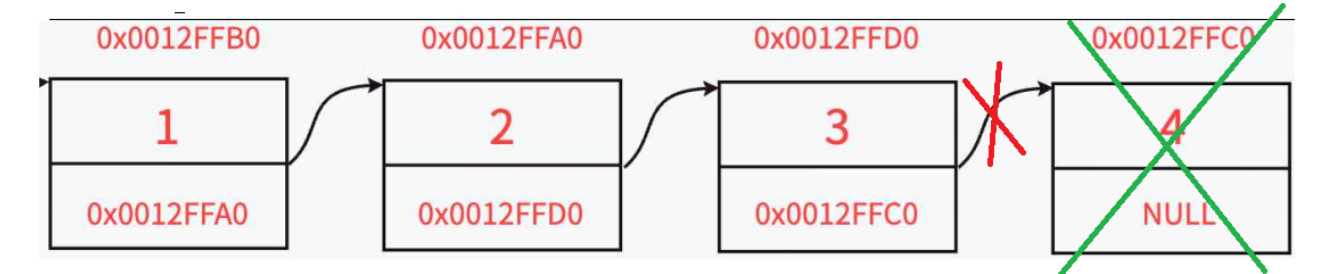
//尾删
void SLTPopBack(SLTNode** pphead)
{
assert(pphead && *pphead);
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* ptail = *pphead;
SLTNode* prev = NULL;
while (ptail->next)
{
prev = ptail;
ptail = ptail->next;
}
prev->next = NULL;
free(ptail);
ptail = NULL;
}
}也就是说,我得用prev先去储存这个节点的指针域让他为空,再释放尾节点,这样的程序才不会越界。
4.头删
思路;1 . 通过头结点的 next值 , 可以知道头结点的下一个结点的地址 , 使phead = phead->next , 就找不回头结点了 , 所以需要创建一个指针变量 , 存储头结点的下一个地址。
2 . 然后free 掉 头结点
3. 改变头结点的值
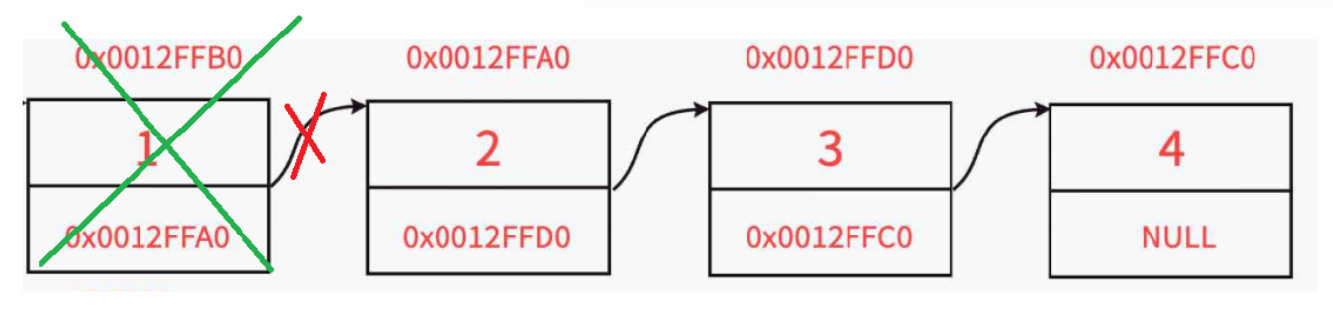 这里的问题和之前头删一样,不再过多叙述。
这里的问题和之前头删一样,不再过多叙述。
//头删
void SLTPopFront(SLTNode** pphead)
{
assert(pphead && *pphead);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}5.查找
通过循环while , 遍历数组 ,直到找到目标结点 , 就返回目标结点 , 没有目标结点,就返回NULL
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataTpye x)
{
SLTNode* pcur = phead;
while (pcur)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
//没找到
return NULL;
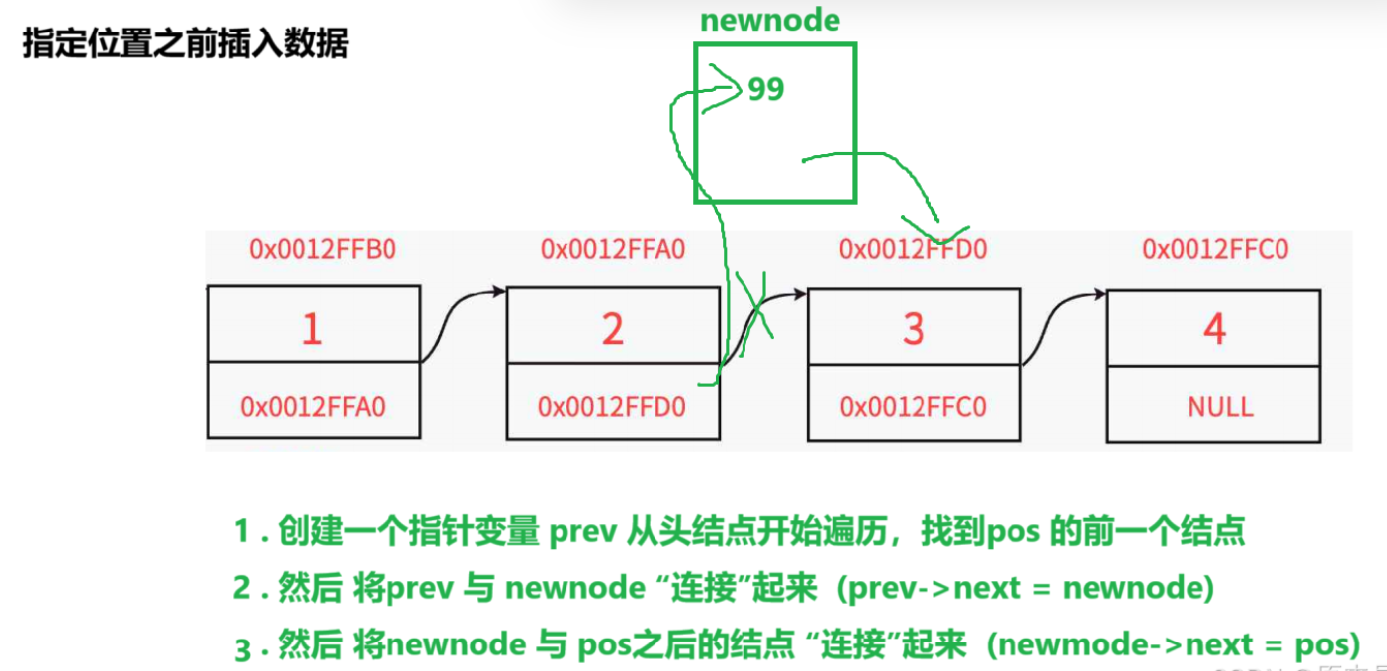
}6.指定位置之前插入数据
思路:通过 创建一个指针变量 prev , 从头开始遍历链表 , 直到找到 pos 结点之前的结点 , 然后使newnode , 与prev 和 pos结点连接起来 。
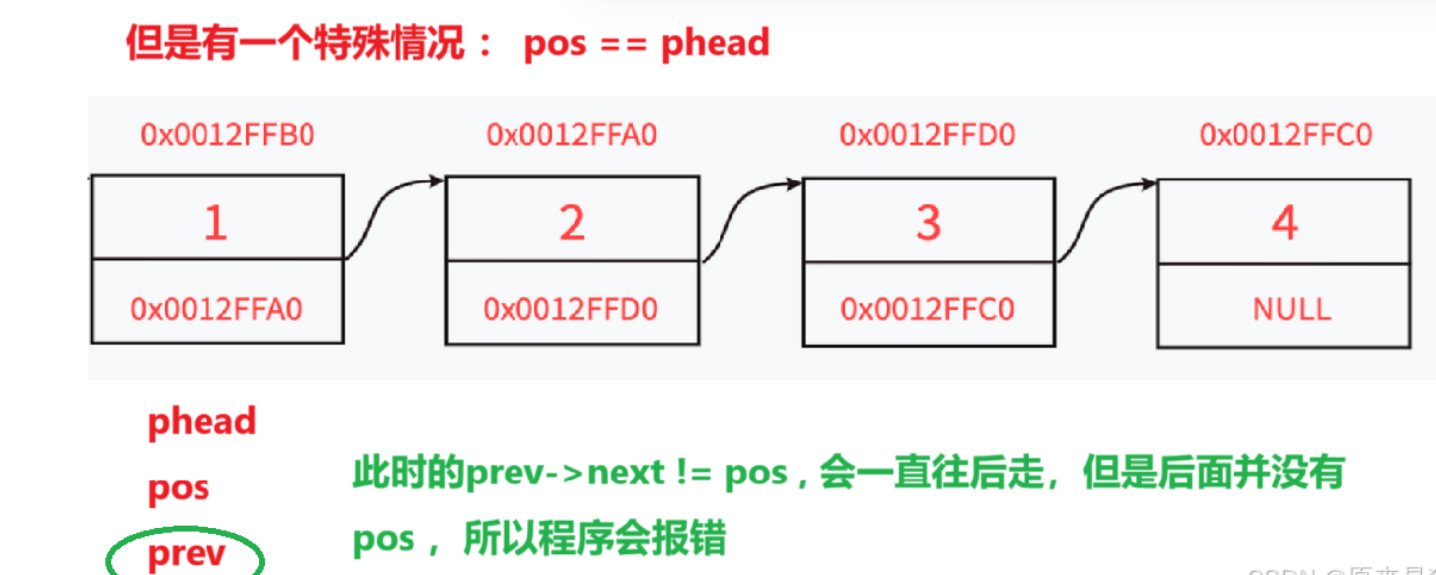
注意:当pos == phead 时,起始prev->next 不等于 pos , 所以prev 会继续往后走,但始终都找不到pos , 程序会出现报错
//指定位置之前插入数据
SLTNode* SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataTpye x)
{
assert(pphead && pos);
if (pos == *pphead)
{
//相当于头插入
SLTPushFront(pphead, x);
}
else
{
SLTNode* newnode = SLTBuyNode(x);
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newnode;
newnode->next = pos;
}
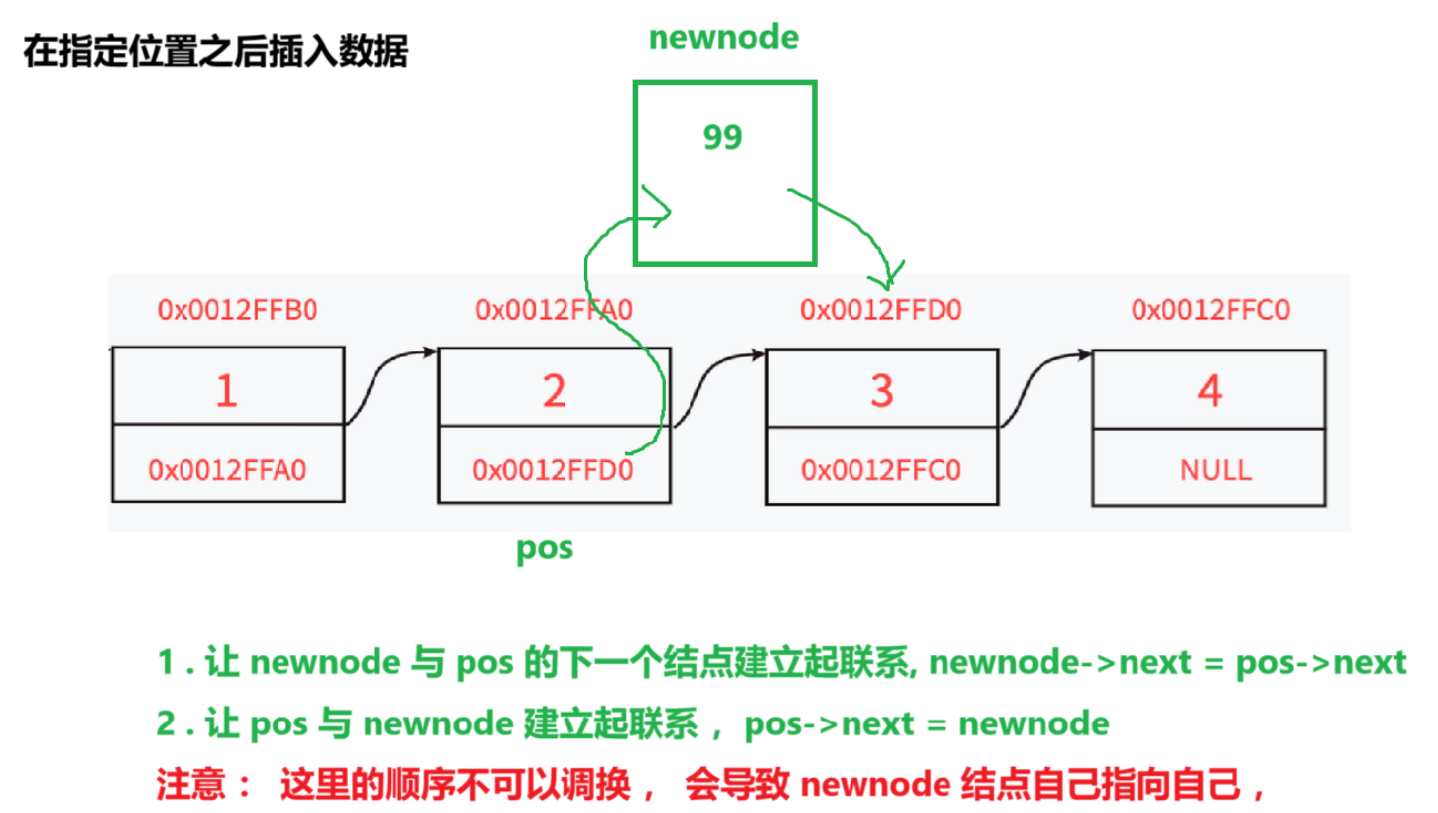
}7.在指定位置之后插入数据
思路:
1 . 在指定位置之后插入数据不需要 知道头指针
2 . 先将 newnode 与 pos 之后的结点建立起联系
3 . 再使 pos 结点 与 newnode 建立起联系
//指定位置之后插入数据
SLTNode* SLTInsertAfter(SLTNode* pos, SLTDataTpye x)
{
assert(pos);
SLTNode* newnode = SLTBuyNode(x);
newnode->next = pos->next;
pos->next = newnode;
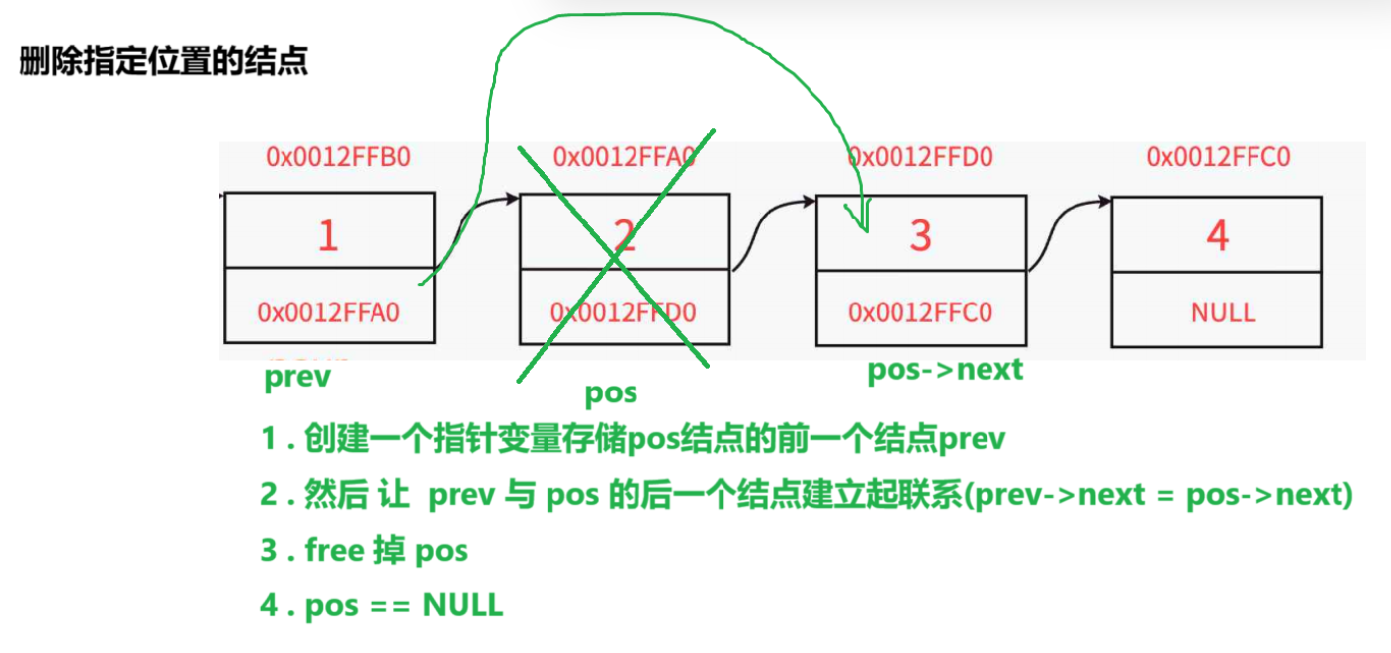
}8.删除pos结点
思路:1 . 创建一个指针变量存储 pos 结点的前一个结点(prev)
2 . 使 prev 与 pos的后一个结点建立联系
3 . free 掉 pos
4 . pos 置为NULL
注意 : 当 pos = phead 时候,prev 会一直往后走,所以对于这种情况需要特殊讨论(相当于头删)
9.删除pos之后的结点
思路:
1 . 为了避免pos 是尾结点 , 之后没有结点的这种情况 ,断言(pos->next)
2 . 创建一个指针变量 , 存储pos 结点的下一个结点(del)
3 . 让pos 与 del 的下一个结点建立起联系
4 . free 掉 del
5 . del 置为 NULL
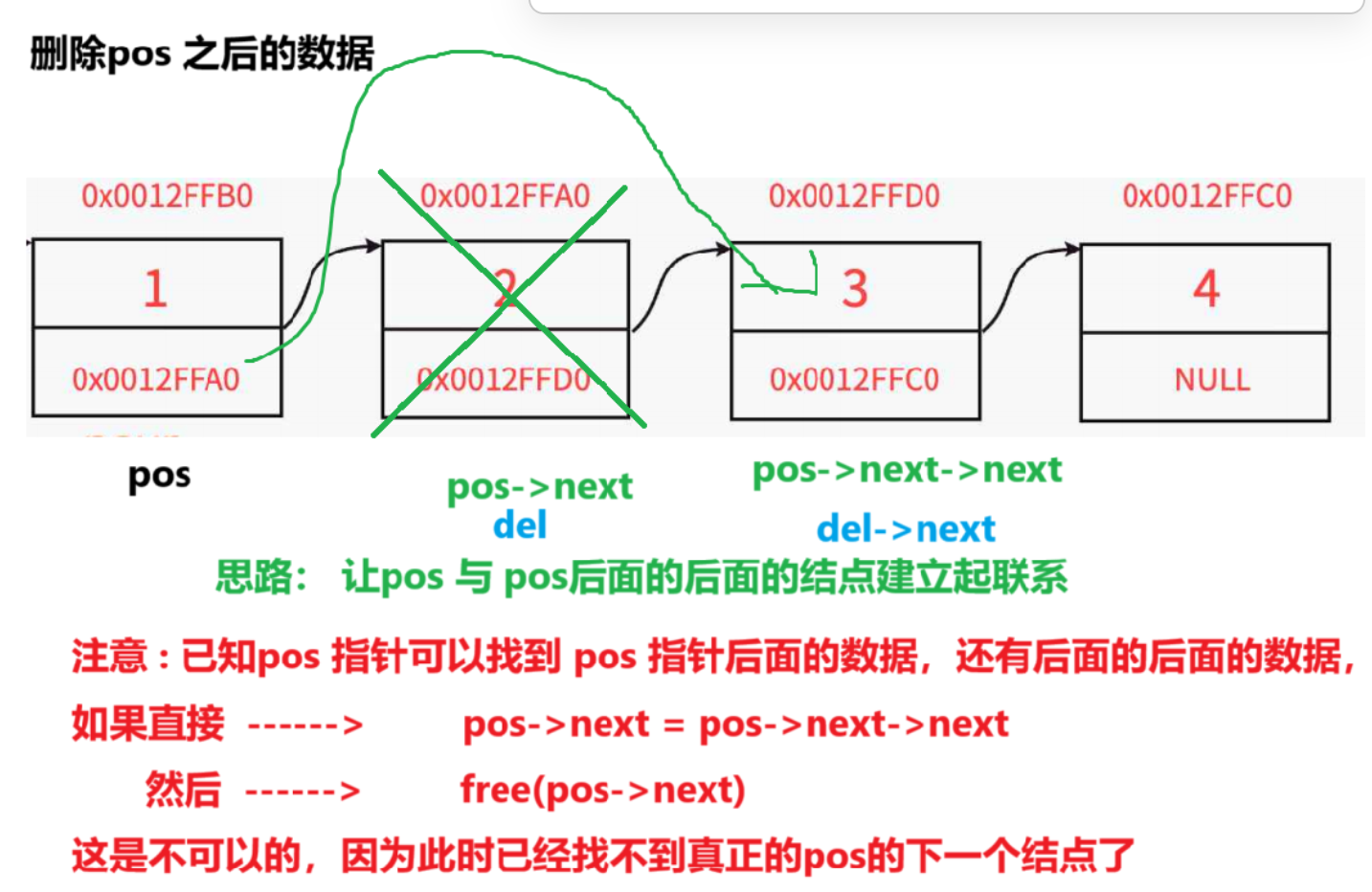
所以我们最后一步才需要一个del来储存真正的pos的下一个节点。
当然,如果pos后面为空,后面是没有数据的,我们要直接规避这种情况的发生。
10.销毁链表
思路:1 . 创建两个指针变量 , pcur (存储当前结点的地址) , next(存储下一个结点地址)
2 . 构建循环体(结束条件是pcur == NULL 时,结束循环) , 把结点一个一个的释放 , 先用next 把 pcur 下一个结点的地址存储起来 , 然后 free 掉 pcur , 再把 next 的值赋给 pcur
3 . 让*pphead 置为 NULL
我们创建链表是一个个创建的,释放的时候也得一个个的释放。
//销毁链表
SLTNode* SLTDestory(SLTNode** pphead)
{
SLTNode* pcur = *pphead;
while (pcur)
{
SLTNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;
}11.链表的复杂度的讨论

我们再回顾一下,在讨论顺序表的时候我们通常所说的是什么

所以这也就呼应了我链表的第一篇文章所留下的疑问,链表到底强在哪?好像链表的名气确实是要比顺序表大很多。当然也不能一味的去说,链表一定比顺序表好 ,它们没有好坏之分 , 不同的场景可以运用不同的表 ,我们需要学习更多的数据结构 来解决不同的算法题。
如果你觉得对你有帮助,可以点赞关注加收藏,感谢您的阅读,我们下一篇文章再见。
一步步来,总会学会的,首先要懂思路,才能有东西写。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









