






在此之前,也看过很多mysql相关的文件资料和书籍,从来没有写过mysql的资料,此篇文章即使自己学习总结,也是自己为了巩固或者分享自己的学习吧,有不对的地方,也请观看着别见怪,也希望来者指正。
首先先了解什么是数据库
数据就是存储数据的仓库,其本质的意义就是文件系统。数据安装特定的格式将数据存储起来,用户可以通过sql对数据中的数据进行增,删,改,查。
关系型数据库的定义
关系型数据:数据库中的记录是有行,还有列的数据库,并且提供了ACID。
ACID:数据库事务的四要素
数据库和表的关系如下图:
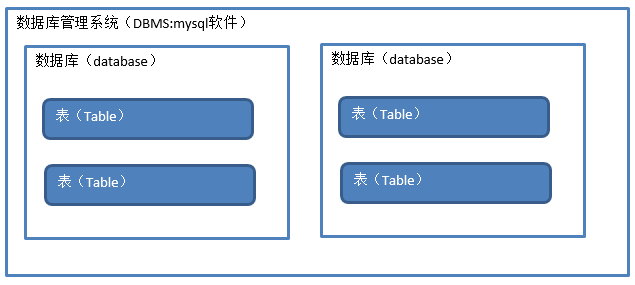
数据库管理系统(DataBase,Management System ,DBMS):是指一种存在操作和管理的数据库的大型系统软件,用于创建,使用并且可以维护数据库,对数据库进行统一管理和控制,以保证数据的安全性和完整性。用户通过数据库管理系统访问数据库中的表内数据库。
MYSQL介绍
mysql是目前最流行关系型数据库管理系统。
SQL介绍
sql全拼是:Structured Query Language的缩写,它的前身是关系数据库原型系统System R所采用的SEQUEL语 言。作为一种访问【关系型数据库的标准语言】,SQL自问世以来得到了广泛的应用,不仅是著名的大型商用数据库产品 Oracle、DB2、Sybase、SQL Server支持它,很多开源的数据库产品如PostgreSQL、MySQL也支持它。
数据库的操作(DDL语句)
创建数据库
create database 数据库名;
create database 数据库名 character set 字符集;
查看数据库
查看数据库服务器中的所有的数据库:
show databases;
查看某个数据库的定义的信息:
show create database 数据库名;删除数据库>不可随意使用
drop database 数据库名称;其他数据库操作命令
切换数据库:
use 数据库名;
查看正在使用的数据库:
select database();
表操作:table 字段类型
常用的类型有:
数字型:
int 浮点型:
double 字符型:
varchar(可变长字符串)
日期类型:
date(只有年月日,没有时分秒)
datetime(年月日,时分秒)
boolean类型:不支持,一般使用tinyint替代(值为0和1)创建表
create table 表名(
字段名 类型(长度) 约束,
字段名 类型(长度) 约束
);
单表约束:
主键约束:primary key
唯一约束:unique
非空约束:not null
注意:
主键约束 = 唯一约束 + 非空约束
查看所有表
show tables;
查看表结构:
desc 表名;删除表
drop table 表名;修改表
alter table 表名 add 列名 类型(长度) 约束; --修改表添加列.
alter table 表名 modify 列名 类型(长度) 约束; --修改表修改列的类型长度及约束.
alter table 表名 change 旧列名 新列名 类型(长度) 约束; --修改表修改列名.
alter table 表名 drop 列名; --修改表删除列.
rename table 表名 to 新表名; --修改表名
alter table 表名 character set 字符集; --修改表的字符集DML语句
插入记录:insert
语法
insert into 表 (列名1,列名2,列名3..) values (值1,值2,值3..); -- 向表中插入某些列
insert into 表 values (值1,值2,值3..); --向表中插入所有列
insert into 表 (列名1,列名2,列名3..) values select (列名1,列名2,列名3..) from 表
insert into 表 values select * from 表
注意:
1. 列名数与values后面的值的个数相等
2. 列的顺序与插入的值得顺序一致
3. 列名的类型与插入的值要一致.
4. 插入值得时候不能超过大长度.
5. 值如果是字符串或者日期需要加引号’’ (一般是单引号)
例如:
INSERT INTO sort(sid,sname) VALUES('s001', '电器');
INSERT INTO sort(sid,sname) VALUES('s002', '服饰');
INSERT INTO sort VALUES('s003', '化妆品');
INSERT INTO sort VALUES('s004','书籍');更新记录:update
update 表名 set 字段名=值,字段名=值;
update 表名 set 字段名=值,字段名=值 where 条件;
注意:
1. 列名的类型与修改的值要一致.
2. 修改值得时候不能超过大长度.
3. 值如果是字符串或者日期需要加’’.
删除记录:delete
delete from 表名 [where 条件];
注:删除方式:
- delete :一条一条删除,不清空auto_increment记录数。
- truncate :直接将表删除,重新建表,auto_increment将置为零,从新开始。
完整DQL语法顺序
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN
< right_table >
ON
< join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT
< limit_number >
简单查询
SQL语法关键字:
案例:
1. 查询所有的商品.
select * from product;
1. 查询商品名和商品价格.
select pname,price from product;
1. 别名查询,使用的as关键字,as可以省略的. 表别名:
select * from product as p;
列别名:
select pname as pn from product;
1. 去掉重复值.
select distinct price from product;
1. 查询结果是表达式(运算查询):将所有商品的价格+10元进行显示.
select pname,price+10 from product;
条件查询
SQL语法关键字:
WHERE
案例:
1. 查询商品名称为十三香的商品所有信息:
select * from product where pname = '十三香';
where后的条件写法:
案例:
1. 查询所有的商品,按价格进行排序.(asc-升序,desc-降序)
> ,<,=,>=,<=,<> like 使用占位符 _ 和 % _代表一个字符 %代表任意个字符.
select * from product where pname like '%新%'; in在某个范围中获得值(exists).
select * from product where pid in (2,5,8);
聚合函数(组函数)
特点:只对单列进行操作
常用的聚合函数:
sum():求某一列的和
avg():求某一列的平均值
max():求某一列的大值
min():求某一列的小值
count():求某一列的元素个数
分组
GROUP BY
HAVING
案例:
根据cno字段分组,分组后统计商品的个数.
select cid,count(*) from product group by cid;
根据cno分组,分组统计每组商品的平均价格,并且平均价格> 60;
select cid,avg(price) from product group by cid having avg(price)>60;
注意事项:
1. select语句中的列(非聚合函数列),必须出现在group by子句中
2. group by子句中的列,不一定要出现在select语句中
3. 聚合函数只能出现select语句中或者having语句中,一定不能出现在where语句中。union和union all
union:集合的并集(不包含重复记录)
union all:集合并集(包含重复记录)SQl执行顺序
编写的sql语法顺序如下:
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN
< right_table >
ON
< join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >然而它的执行顺序是这样的:
- 行过滤
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table> 第二步和第三步会循环执行
4 WHERE <where_condition> 第四步会循环执行,多个条件的执行顺序是从左往右的。
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
--列过滤
7 SELECT 分组之后才会执行SELECT
8 DISTINCT <select_list>
--排序
9 ORDER BY <order_by_condition>
-- MySQL附加
10 LIMIT <limit_number> 前9步都是SQL92标准语法。limit是MySQL的独有语法。
1,FROM
对from的左边的表和右边的表计算,产生续表VT1
mysql> select * from product,category;2.ON过滤
对虚表VT1 进行ON筛选,只有那些符合的行才会被记录在虚表VT2中。
注意:这里因为语法限制,使用了'WHERE'代替,从中读者也可以感受到两者之间微妙的关系;
mysql> select * from product a , category b where a.cid=b.id; 3.OUTER JOIN添加外部列
如果指定了 OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表 VT2 中,产生虚拟表VT3 。
如果FROM子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这 三个步骤,一直到处理完所有的表为止。
mysql> select * from product a left outer join category b on a.cid=b.id; # 以左表数据为准
mysql> select * from product a right outer join category b on a.cid=b.id; #以右表数据为准 4.WHERE
对虚拟表VT3 进行WHERE条件过滤。只有符合的记录才会被插入到虚拟表VT4 中。
注意:
此时因为分组,不能使用聚合运算;也不能使用SELECT中创建的别名;
与ON的区别:
如果有外部列,ON针对过滤的是关联表,主表(保留表)会返回所有的列;
如果没有添加外部列,两者的效果是一样的;
应用:
对主表的过滤应该放在WHERE;
对于关联表,先条件查询后连接则用ON,先连接后条件查询则用WHERE;
5.GROUP BY
根据group by子句中的列,对VT4中的记录进行分组操作,产生虚拟表VT5 。
注意:
其后处理过程的语句,如SELECT,HAVING,所用到的列必须包含在GROUP BY中。对于没有出现的,得用聚合函 数;
原因:
GROUP BY改变了对表的引用,将其转换为新的引用方式,能够对其进行下一级逻辑操作的列会减少;
我的理解是:
根据分组字段,将具有相同分组字段的记录归并成一条记录,因为每一个分组只能返回一条记录,除非是被过滤掉 了,而不在分组字段里面的字段可能会有多个值,多个值是无法放进一条记录的,所以必须通过聚合函数将这些具有 多值的列转换成单值;
6.HAVING
对虚拟表VT5 应用having过滤,只有符合的记录才会被 插入到虚拟表VT6 中。
7.SELECT
这个子句对SELECT子句中的元素进行处理,生成VT5表。
(5-J1)计算表达式 计算SELECT 子句中的表达式,生成VT5-J1
8.DISTINCT
寻找VT5-1中的重复列,并删掉,生成VT5-J2
如果在查询中指定了DISTINCT子句,则会创建一张内存临时表(如果内存放不下,就需要存放在硬盘了)。这张临 时表的表结构和上一步产生的虚拟表VT5是一样的,不同的是对进行DISTINCT操作的列增加了一个唯一索引,以此来 除重复数据。
9.ORDER BY
从 VT5-J2 中的表中,根据ORDER BY 子句的条件对结果进行排序,生成VT6表。
注意:
唯一可使用SELECT中别名的地方;
10.LIMIT(MySQL特有)
LIMIT子句从上一步得到的 VT6虚拟表中选出从指定位置开始的指定行数据。
注意:
offset 和 rows 的正负带来的影响;
当偏移量很大时效率是很低的,可以这么做:
采用子查询的方式优化,在子查询里先从索引获取到大id,然后倒序排,再取N行结果集
采用INNER JOIN优化,JOIN子句里也优先从索引获取ID列表,然后直接关联查询获得终结果
解析属性总结
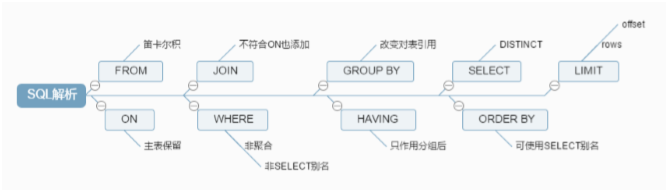
流程分析
1. FROM(将近的两张表,进行笛卡尔积)---VT1
2. ON(将VT1按照它的条件进行过滤)---VT2
3. LEFT JOIN(保留左表的记录)---VT3
4. WHERE(过滤VT3中的记录)--VT4…VTn
5. GROUP BY(对VT4的记录进行分组)---VT5
6. HAVING(对VT5中的记录进行过滤)---VT6
7. SELECT(对VT6中的记录,选取指定的列)--VT7
8. ORDER BY(对VT7的记录进行排序)--VT8
9. LIMIT(对排序之后的值进行分页)--MySQL特有的语法















 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









