







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、SQL9 查找除复旦大学的用户信息
- 二、SQL10 用where过滤空值练习
- 三、SQL14 操作符混合运用
- 四、SQL15 查看学校名称中含北京的用户
- 五、SQL18 分组计算练习题
- 六、SQL24 统计每个用户的平均刷题数
- 七、SQL25 查找山东大学或者性别为男生的信息
- 八、SQL29 计算用户的平均次日留存率
- 九、SQL31 提取博客URL中的用户名
- 十、SQL33 找出每个学校GPA最低的同学
- 十一、SQL34 统计复旦用户8月练题情况
- 十二、SQL196 查找入职员工时间排名倒数第三的员工所有信息
- 十三、SQL212 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
- 十四、窗口函数演示
- 十五、SQL215 查找在职员工自入职以来的薪水涨幅情况
- 十六、SQL219 获取员工其当前的薪水比其manager当前薪水还高的相关信息
- 十七、SQL226 将employees表的所有员工的last_name和first_name拼接起来
- 十八、SQL229 批量插入数据,不使用replace操作
- 十九、SQL232 针对actor表创建视图actor_name_view
- 二十、SQL233 针对上面的salaries表emp_no字段创建索引idx_emp_no
- 二十一、SQL235 构造一个触发器audit_log
- 二十二、SQL236 删除emp_no重复的记录,只保留最小的id对应的记录。
- 二十三、SQL237 将所有to_date为9999-01-01的全部更新为NULL
- 二十四、SQL238 将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005
- 二十五、SQL240 在audit表上创建外键约束,其emp_no对应employees_test表的主键id
- 二十六、SQL248 平均工资
- 二十七、SQL249 分页查询employees表,每5行一页,返回第2页的数据
- 二十八、SQL251 使用含有关键字exists查找未分配具体部门的员工的所有信息。
- 二十九、SQL255 给出employees表中排名为奇数行的first_name
- 三十、SQL263 牛客每个人最近的登录日期(四)
- 三十一、SQL264 牛客每个人最近的登录日期(五)
- 三十二、SQL269 考试分数(四)
- 三十三、SQL270 考试分数(五)
- 三十四、SQL280 实习广场投递简历分析(三)
- 三十五、SQL282 最差是第几名(二)
- 三十六、SQL285 获得积分最多的人(三)
前言
执行顺序:FROM --> WHERE --> GROUP BY --> HAVING --> SELECT --> ORDER BY
一、SQL9 查找除复旦大学的用户信息
描述
题目:现在运营想要查看除复旦大学以外的所有用户明细,请你取出相应数据
示例:user_profile

建表代码如下:
drop table if exists user_profile;
CREATE TABLE `user_profile` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`gender` varchar(14) NOT NULL,
`age` int ,
`university` varchar(32) NOT NULL,
`province` varchar(32) NOT NULL);
INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学','BeiJing');
INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学','Shanghai');
INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学','BeiJing');
INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学','ZheJiang');
INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学','Shandong');
根据输入,你的查询应返回以下结果:

查询代码如下:
select
device_id
,gender
,age
,university
from
user_profile
where
university != '复旦大学';
# university <> '复旦大学';
# university not in ('复旦大学');
# university not like '复旦大学';
PS:sql中判断不等于时可以使用’!=‘、’<>’、‘not in '、'not like’表示
二、SQL10 用where过滤空值练习
描述
题目:现在运营想要对用户的年龄分布开展分析,在分析时想要剔除没有获取到年龄的用户,请你取出所有年龄值不为空的用户的设备ID,性别,年龄,学校的信息。
示例:user_profile

建表代码如下:
drop table if exists user_profile;
CREATE TABLE `user_profile` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`gender` varchar(14) NOT NULL,
`age` int ,
`university` varchar(32) NOT NULL,
`province` varchar(32) NOT NULL);
INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学','BeiJing');
INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学','Shanghai');
INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学','BeiJing');
INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学','ZheJiang');
INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学','Shandong');
根据输入,你的查询应返回以下结果:

查询代码如下:
# select
device_id
,gender, age
,university
from user_profile
where age is not null;
# age <> '';
# age != 'null';
# age <> 'null';
PS:sql中判断空值有以上四种方法
三、SQL14 操作符混合运用
描述
题目:现在运营想要找到gpa在3.5以上(不包括3.5)的山东大学用户 或 gpa在3.8以上(不包括3.8)的复旦大学同学进行用户调研,请你取出相应数据
示例:user_profile

建表代码如下:
drop table if exists user_profile;
CREATE TABLE `user_profile` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`gender` varchar(14) NOT NULL,
`age` int ,
`university` varchar(32) NOT NULL,
`province` varchar(32) NOT NULL,
`gpa` float);
INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学','BeiJing',3.4);
INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学','Shanghai',4.0);
INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学','BeiJing',3.2);
INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学','ZheJiang',3.6);
INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学','Shandong',3.8);
根据输入,你的查询应返回以下结果:

查询代码如下:
select
device_id,
gender,
age,
university,
gpa
from
user_profile
where
# (university = '山东大学'
# and gpa > 3.5)
# or (university = '复旦大学'
# and gpa > 3.8);
university = '山东大学'and gpa > 3.5 or
university = '复旦大学 and gpa > 3.8;
PS:sql中逻辑运算符or的优先级小于and
四、SQL15 查看学校名称中含北京的用户
描述
题目:现在运营想查看所有大学中带有北京的用户的信息,请你取出相应数据。
示例:用户信息表:user_profile

建表代码如下:
drop table if exists user_profile;
CREATE TABLE `user_profile` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`gender` varchar(14) NOT NULL,
`age` int ,
`university` varchar(32) NOT NULL,
`gpa` float);
INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学',3.4);
INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学',4.0);
INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学',3.2);
INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学',3.6);
INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学',3.8);
INSERT INTO user_profile VALUES(6,2131,'male',28,'北京师范大学',3.3);
根据输入,你的查询应返回以下结果:

查询代码如下:
select
device_id,
age,
university
from
user_profile
where
# university like '%北京%';
university like '北京%';
PS:sql中的匹配符号
%:表示任意 0 个或多个字符。可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示。
_ :表示任意单个字符。匹配单个任意字符,它常用来限制表达式的字符长度语句。
[]:表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。
[^] :表示不在括号所列之内的单个字符。其取值和 [] 相同,但它要求所匹配对象为指定字符以外的任一个字符。
查询内容包含通配符时,由于通配符的缘故,导致我们查询特殊字符 “%”、“_”、“[” 的语句无法正常实现,而把特殊字符用 “[ ]” 括起便可正常查询。
五、SQL18 分组计算练习题
描述
题目:现在运营想要对每个学校不同性别的用户活跃情况和发帖数量进行分析,请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量。
用户信息表:user_profile
30天内活跃天数字段(active_days_within_30)
发帖数量字段(question_cnt)
回答数量字段(answer_cnt)

建表代码如下:
drop table if exists user_profile;
CREATE TABLE `user_profile` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`gender` varchar(14) NOT NULL,
`age` int ,
`university` varchar(32) NOT NULL,
`gpa` float,
`active_days_within_30` float,
`question_cnt` float,
`answer_cnt` float
);
INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学',3.4,7,2,12);
INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学',4.0,15,5,25);
INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学',3.2,12,3,30);
INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学',3.6,5,1,2);
INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学',3.8,20,15,70);
INSERT INTO user_profile VALUES(6,2131,'male',28,'山东大学',3.3,15,7,13);
INSERT INTO user_profile VALUES(7,4321,'male',28,'复旦大学',3.6,9,6,52);
根据输入,你的查询应返回以下结果:

查询代码如下:
-- 解法一:分组聚合
select
gender
,university
,count(1) as user_num
,round(avg(active_days_within_30),1) as avg_active_day
,round(avg(question_cnt),1) as avg_question_cnt
from user_profile
group by university,gender;
-- 解法二:利用窗口函数
select distinct
gender
,university
,count(1) over (partition by university,gender) as user_num
,round(avg(active_days_within_30) over (partition by university,gender),1) as avg_active_day
,round(avg(question_cnt) over (partition by university,gender),1) as avg_question_cnt
from user_profile
order by university,gender;
PS:
(1)distinct起到去重作用;
(2)round(value,n) 其中value:数值。可为储存数值的字段。n:小数点位数,为自然数,0表示保留整数,1表示保留一位小数,以此类推,四舍五入;
(3)count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL;count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL;count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空。
六、SQL24 统计每个用户的平均刷题数
描述
题目:运营想要查看参加了答题的山东大学的用户在不同难度下的平均答题题目数,请取出相应数据
用户信息表:user_profile

第一行表示:id为1的用户的常用信息为使用的设备id为2138,性别为男,年龄21岁,北京大学,gpa为3.4,在过去的30天里面活跃了7天,发帖数量为2,回答数量为12
题库练习明细表:question_practice_detail

第一行表示:id为1的用户的常用信息为使用的设备id为2138,在question_id为111的题目上,回答错误
表:question_detail

建表代码如下:
drop table if exists `user_profile`;
drop table if exists `question_practice_detail`;
drop table if exists `question_detail`;
CREATE TABLE `user_profile` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`gender` varchar(14) NOT NULL,
`age` int ,
`university` varchar(32) NOT NULL,
`gpa` float,
`active_days_within_30` int ,
`question_cnt` int ,
`answer_cnt` int
);
CREATE TABLE `question_practice_detail` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`question_id`int NOT NULL,
`result` varchar(32) NOT NULL
);
CREATE TABLE `question_detail` (
`id` int NOT NULL,
`question_id`int NOT NULL,
`difficult_level` varchar(32) NOT NULL
);
INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学',3.4,7,2,12);
INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学',4.0,15,5,25);
INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学',3.2,12,3,30);
INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学',3.6,5,1,2);
INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学',3.8,20,15,70);
INSERT INTO user_profile VALUES(6,2131,'male',28,'山东大学',3.3,15,7,13);
INSERT INTO user_profile VALUES(7,4321,'male',28,'复旦大学',3.6,9,6,52);
INSERT INTO question_practice_detail VALUES(1,2138,111,'wrong');
INSERT INTO question_practice_detail VALUES(2,3214,112,'wrong');
INSERT INTO question_practice_detail VALUES(3,3214,113,'wrong');
INSERT INTO question_practice_detail VALUES(4,6543,111,'right');
INSERT INTO question_practice_detail VALUES(5,2315,115,'right');
INSERT INTO question_practice_detail VALUES(6,2315,116,'right');
INSERT INTO question_practice_detail VALUES(7,2315,117,'wrong');
INSERT INTO question_practice_detail VALUES(8,5432,117,'wrong');
INSERT INTO question_practice_detail VALUES(9,5432,112,'wrong');
INSERT INTO question_practice_detail VALUES(10,2131,113,'right');
INSERT INTO question_practice_detail VALUES(11,5432,113,'wrong');
INSERT INTO question_practice_detail VALUES(12,2315,115,'right');
INSERT INTO question_practice_detail VALUES(13,2315,116,'right');
INSERT INTO question_practice_detail VALUES(14,2315,117,'wrong');
INSERT INTO question_practice_detail VALUES(15,5432,117,'wrong');
INSERT INTO question_practice_detail VALUES(16,5432,112,'wrong');
INSERT INTO question_practice_detail VALUES(17,2131,113,'right');
INSERT INTO question_practice_detail VALUES(18,5432,113,'wrong');
INSERT INTO question_practice_detail VALUES(19,2315,117,'wrong');
INSERT INTO question_practice_detail VALUES(20,5432,117,'wrong');
INSERT INTO question_practice_detail VALUES(21,5432,112,'wrong');
INSERT INTO question_practice_detail VALUES(22,2131,113,'right');
INSERT INTO question_practice_detail VALUES(23,5432,113,'wrong');
INSERT INTO question_detail VALUES(1,111,'hard');
INSERT INTO question_detail VALUES(2,112,'medium');
INSERT INTO question_detail VALUES(3,113,'easy');
INSERT INTO question_detail VALUES(4,115,'easy');
INSERT INTO question_detail VALUES(5,116,'medium');
INSERT INTO question_detail VALUES(6,117,'easy');
查询应返回以下结果(结果在小数点位数保留4位,4位之后四舍五入):

查询代码如下:
-- 解法一
select
university
,difficult_level
,round(count(qpd.question_id) / count(distinct u.device_id),4) as avg_answer_cnt
from user_profile as u, question_practice_detail as qpd, question_detail as qd
where u.device_id = qpd.device_id and qpd.question_id = qd.question_id
and university = '山东大学'
group by university,difficult_level;
-- 解法二
select
university,
difficult_level,
round(count(qpd.question_id) / count(distinct up.device_id), 4) as avg_answer_cnt
from user_profile as up
inner join question_practice_detail as qpd
on up.device_id = qpd.device_id
inner join question_detail as qd
on qpd.question_id = qd.question_id
where university = '山东大学'
group by university, difficult_level;
七、SQL25 查找山东大学或者性别为男生的信息
描述
题目:现在运营想要分别查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据,请取出相应结果,结果不去重。
示例:user_profile

建表代码如下:
drop table if exists `user_profile`;
CREATE TABLE `user_profile` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`gender` varchar(14) NOT NULL,
`age` int ,
`university` varchar(32) NOT NULL,
`gpa` float,
`active_days_within_30` int ,
`question_cnt` int ,
`answer_cnt` int
);
INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学',3.4,7,2,12);
INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学',4.0,15,5,25);
INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学',3.2,12,3,30);
INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学',3.6,5,1,2);
INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学',3.8,20,15,70);
INSERT INTO user_profile VALUES(6,2131,'male',28,'山东大学',3.3,15,7,13);
INSERT INTO user_profile VALUES(7,4321,'male',28,'复旦大学',3.6,9,6,52);
根据示例,你的查询应返回以下结果(注意输出的顺序,先输出学校为山东大学再输出性别为男生的信息):

查询代码如下:
select
device_id
,gender
,age
,gpa
from user_profile
where university = '山东大学'
union all
select
device_id
,gender
,age
,gpa
from user_profile
where gender = 'male';
PS:sql中union与union all的区别
1.显示结果不同
union会自动压缩多个结果集合中的重复结果,而union all则将所有的结果集全部显示出来。
2.对重复结果的处理不同
union all是直接连接,取到的是所有值,记录可能有的重复;union是取唯一值,记录没有重复。
所以union在进行表链接后会筛选掉重复的记录,union all不会去除重复记录。
3.对排序的处理不同
union会按照字段的顺序进行排序;union all 只是将两个结果集合并后就返回。从效率上讲,union all要比 union快的多,所以如果确定合并的两个结果集中没有重复且不需要排序就用union all。
八、SQL29 计算用户的平均次日留存率
描述
题目:现在运营想要查看用户在某天刷题后第二天还会再来刷题的平均概率。请你取出相应数据。
示例:question_practice_detail

建表代码如下:
drop table if exists `question_practice_detail`;
CREATE TABLE `question_practice_detail` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`question_id`int NOT NULL,
`result` varchar(32) NOT NULL,
`date` date NOT NULL
);
INSERT INTO question_practice_detail VALUES(1,2138,111,'wrong','2021-05-03');
INSERT INTO question_practice_detail VALUES(2,3214,112,'wrong','2021-05-09');
INSERT INTO question_practice_detail VALUES(3,3214,113,'wrong','2021-06-15');
INSERT INTO question_practice_detail VALUES(4,6543,111,'right','2021-08-13');
INSERT INTO question_practice_detail VALUES(5,2315,115,'right','2021-08-13');
INSERT INTO question_practice_detail VALUES(6,2315,116,'right','2021-08-14');
INSERT INTO question_practice_detail VALUES(7,2315,117,'wrong','2021-08-15');
INSERT INTO question_practice_detail VALUES(8,3214,112,'wrong','2021-05-09');
INSERT INTO question_practice_detail VALUES(9,3214,113,'wrong','2021-08-15');
INSERT INTO question_practice_detail VALUES(10,6543,111,'right','2021-08-13');
INSERT INTO question_practice_detail VALUES(11,2315,115,'right','2021-08-13');
INSERT INTO question_practice_detail VALUES(12,2315,116,'right','2021-08-14');
INSERT INTO question_practice_detail VALUES(13,2315,117,'wrong','2021-08-15');
INSERT INTO question_practice_detail VALUES(14,3214,112,'wrong','2021-08-16');
INSERT INTO question_practice_detail VALUES(15,3214,113,'wrong','2021-08-18');
INSERT INTO question_practice_detail VALUES(16,6543,111,'right','2021-08-13');
根据示例,你的查询应返回以下结果:

查询代码如下:
-- 解法一
select
count(date2) / count(date1) as avg_ret
from (
select distinct qpd.device_id, qpd.date as date1,
uniq_id_date.date as date2
from question_practice_detail as qpd
left join (
# select device_id, date
select distinct device_id, date
from question_practice_detail
) as uniq_id_date
on qpd.device_id = uniq_id_date.device_id
# and uniq_id_date.date = qpd.date + interval 1 day
and date_add(qpd.date, interval 1 day) = uniq_id_date.date
) as id_last_next_date;
-- 解法二
select
count(q2.device_id) / count(q1.device_id) as avg_ret
from (
select distinct device_id, date
from question_practice_detail
) as q1
left join (
select distinct device_id, date
from question_practice_detail
) as q2
on q1.device_id = q2.device_id and
# q1.date + interval 1 day = q2.date
date_add(q1.date, interval 1 day) = q2.date;
-- 解法三
select avg(if(datediff(date2, date1)=1, 1, 0)) as avg_ret
from (
select
distinct device_id,
date as date1,
lead(date) over (partition by device_id order by date) as date2
# lead(date,1) over (partition by device_id order by date) as date2
# lead(date,1,0) over (partition by device_id order by date) as date2
from (
select distinct device_id, date
from question_practice_detail
) as uniq_id_date
) as id_last_next_date;
-- 解法四
select
avg(if(datediff(date1,date2)=-1,1,0)) as avg_ret
from (
select distinct
device_id
,date as date1
,lead(date,1) over (partition by device_id order by date) as date2
from question_practice_detail
) as t
where date1 <> date2 or date2 is null; --思考下为什么要对date2做空值筛选
-- 解法五
select
avg(if(datediff(date1,date2)=-1,1,0)) as avg_ret
from (
select distinct
device_id
,date as date1
,lead(date,1,0) over (partition by device_id order by date) as date2
from question_practice_detail
) as t
where date1 <> date2;
PS:Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
函数语法如下:
lag(exp_str,offset,defval) over(partion by …order by …)
lead(exp_str,offset,defval) over(partion by …order by …)
其中exp_str是字段名,offset是偏移量,即取上1个或上n个的值,假设当前行在表中排在第4行,则offset 为3,则表示我们所要找的数据行就是表中的第1行或第7行(即4-3=1或4+3=7);defval是默认值,当在表中从当前行位置向前或向后数n行已经超出了表的范围时,则将defval这个参数值作为函数的返回值,若没有指定默认值,则返回null。
常用的时间函数:
select now() as '当前日期时间'
,curdate() as '当前日期1', current_date() as '当前日期2', current_date as '当前日期3', date(now()) as '当前日期'
,year(now()) as '当前年份', month(now()) as ‘当前月’, day(now()) as '当前日', curtime() as '当前时刻' -- 时分秒
,hour(now()) as '当前时', minute(now()) as '当前分', second(now()) as '当前秒';
select weekofyear(now()) as '当前周'
,dayofweek(now()) as '星期' -- 当天是一周内的周几,该函数中一周自周日始,周日对应1...
,date_format(now(),'%Y-%m-%d') as '日期'
,date_format(now(),'%W %h:%i') as '星期 时间'
,str_to_date('2024-06-18 10:20:30','%Y-%m-%d') as '日期 '
,date_add(current_date,INTERVAL 1 DAY) AS '明天'
,date_add(current_date,INTERVAL -1 DAY) AS '昨天';
-- datediff(end_date,start_date)
SELECT datediff(current_date,'2024-06-05') AS '天数';
-- timestampdiff(unit,begin,end)
select timestampdiff(day,'2024-5-05',current_date) as '天数',
timestampdiff(month,'2024-05-05',current_date) as '月份';
九、SQL31 提取博客URL中的用户名
描述
题目:对于申请参与比赛的用户,blog_url字段中url字符后的字符串为用户个人博客的用户名,现在运营想要把用户的个人博客用户字段提取出单独记录为一个新的字段,请取出所需数据。
示例:user_submit

建表代码如下:
drop table if exists user_submit;
CREATE TABLE `user_submit` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`profile` varchar(100) NOT NULL,
`blog_url` varchar(100) NOT NULL
);
INSERT INTO user_submit VALUES(1,2138,'180cm,75kg,27,male','http:/url/bisdgboy777');
INSERT INTO user_submit VALUES(1,3214,'165cm,45kg,26,female','http:/url/dkittycc');
INSERT INTO user_submit VALUES(1,6543,'178cm,65kg,25,male','http:/url/tigaer');
INSERT INTO user_submit VALUES(1,4321,'171cm,55kg,23,female','http:/url/uhsksd');
INSERT INTO user_submit VALUES(1,2131,'168cm,45kg,22,female','http:/url/sysdney');
根据示例,你的查询应返回以下结果:

查询代码如下:
-- 方法一:替换法 replace(string, '被替换部分','替换后的结果')
select
device_id, replace(blog_url,'http:/url/','') as user_name
from user_submit;
-- 方法二:截取法 substr(string, start_point, length*可选参数*)
select
device_id, substr(blog_url,length('http:/url/')+1,length(blog_url)-length('http:/url/')) as user_nam
from user_submit;
-- 方法三:删除法 trim('被删除字段' from 列名)
select
device_id, trim('http:/url/' from blog_url) as user_name
from user_submit;
-- 方法四:字段切割法 substring_index(string, '切割标志', 位置数)
-- 按照'切割标志'进行分段,-1代表最后一段,-2代表后2段,3代表前3段;如需截取中间段,则需嵌套处理
select
device_id, substring_index(blog_url,'/',-1) as user_name
from user_submit;
十、SQL33 找出每个学校GPA最低的同学
描述
题目:现在运营想要找到每个学校gpa最低的同学来做调研,请你取出每个学校的最低gpa。
示例:user_profile

建表代码如下:
drop table if exists user_profile;
CREATE TABLE `user_profile` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`gender` varchar(14) NOT NULL,
`age` int ,
`university` varchar(32) NOT NULL,
`gpa` float,
`active_days_within_30` int ,
`question_cnt` int ,
`answer_cnt` int
);
INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学',3.4,7,2,12);
INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学',4.0,15,5,25);
INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学',3.2,12,3,30);
INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学',3.6,5,1,2);
INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学',3.8,20,15,70);
INSERT INTO user_profile VALUES(6,2131,'male',28,'山东大学',3.3,15,7,13);
INSERT INTO user_profile VALUES(7,4321,'male',28,'复旦大学',3.6,9,6,52);
根据示例,你的查询结果应参考以下格式,输出结果按university升序排序:

查询代码如下:
-- 方法一:利用join右连接 (思考下为什么需要用到右连接)
select a.device_id, a.university, a.gpa
from user_profile a
right join
(
select university, min(gpa) as gpa
from user_profile
group by university
) as b
on a.university=b.university and a.gpa=b.gpa
order by a.university;
-- 方法二:利用窗口函数row_number()
select
device_id,
university,
gpa
from (
select
*
,row_number() over (partition by university order by gpa asc)
as rk
from user_profile
) as univ_min
where rk = 1
order by university;
-- 方法三:利用窗口函数min()
select
device_id
,university
,gpa
from (
select
*
,min(gpa) over (partition by university) as gpa_min
from user_profile
) as t
where t.gpa= gpa_min
order by university;
十一、SQL34 统计复旦用户8月练题情况
描述
题目: 现在运营想要了解复旦大学的每个用户在8月份练习的总题目数和回答正确的题目数情况,请取出相应明细数据,对于在8月份没有练习过的用户,答题数结果返回0.
示例:用户信息表user_profile

示例:question_practice_detail

建表代码如下:
drop table if exists `user_profile`;
drop table if exists `question_practice_detail`;
CREATE TABLE `user_profile` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`gender` varchar(14) NOT NULL,
`age` int ,
`university` varchar(32) NOT NULL,
`gpa` float,
`active_days_within_30` int ,
`question_cnt` int ,
`answer_cnt` int
);
CREATE TABLE `question_practice_detail` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`question_id`int NOT NULL,
`result` varchar(32) NOT NULL,
`date` date NOT NULL
);
INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学',3.4,7,2,12);
INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学',4.0,15,5,25);
INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学',3.2,12,3,30);
INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学',3.6,5,1,2);
INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学',3.8,20,15,70);
INSERT INTO user_profile VALUES(6,2131,'male',28,'山东大学',3.3,15,7,13);
INSERT INTO user_profile VALUES(7,4321,'male',28,'复旦大学',3.6,9,6,52);
INSERT INTO question_practice_detail VALUES(1,2138,111,'wrong','2021-05-03');
INSERT INTO question_practice_detail VALUES(2,3214,112,'wrong','2021-05-09');
INSERT INTO question_practice_detail VALUES(3,3214,113,'wrong','2021-06-15');
INSERT INTO question_practice_detail VALUES(4,6543,111,'right','2021-08-13');
INSERT INTO question_practice_detail VALUES(5,2315,115,'right','2021-08-13');
INSERT INTO question_practice_detail VALUES(6,2315,116,'right','2021-08-14');
INSERT INTO question_practice_detail VALUES(7,2315,117,'wrong','2021-08-15');
INSERT INTO question_practice_detail VALUES(8,3214,112,'wrong','2021-05-09');
INSERT INTO question_practice_detail VALUES(9,3214,113,'wrong','2021-08-15');
INSERT INTO question_practice_detail VALUES(10,6543,111,'right','2021-08-13');
INSERT INTO question_practice_detail VALUES(11,2315,115,'right','2021-08-13');
INSERT INTO question_practice_detail VALUES(12,2315,116,'right','2021-08-14');
INSERT INTO question_practice_detail VALUES(13,2315,117,'wrong','2021-08-15');
INSERT INTO question_practice_detail VALUES(14,3214,112,'wrong','2021-08-16');
INSERT INTO question_practice_detail VALUES(15,3214,113,'wrong','2021-08-18');
INSERT INTO question_practice_detail VALUES(16,6543,111,'right','2021-08-13');
根据示例,你的查询应返回以下结果:

查询代码如下:
-- 方法一
select
u.device_id,
u.university,
count(question_id) as question_cnt,
sum(if(result = 'right', 1, 0)) as right_question_cnt
from user_profile as u
left join (
select
device_id,
question_id,
result
from question_practice_detail
where month(date) = '8'
) as q
on u.device_id = q.device_id
where u.university = '复旦大学'
group by u.device_id;
-- 方法二
select
u.device_id
,university
,sum(if(question_id is null,0,1)) as question_id -- 也可以用count(question_id)
,sum(if(result = 'right',1,0)) as result
from user_profile as u
left join question_practice_detail as qpd
on u.device_id = qpd.device_id
where u.university = '复旦大学' and (month(date) = '8' or date is null) -- 思考下为什么用这个筛选条件
group by u.device_id;
十二、SQL196 查找入职员工时间排名倒数第三的员工所有信息
描述
查找入职员工时间排名倒数第三的员工所有信息
示例:员工employees表

建表代码如下:
drop table if exists `employees` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');
INSERT INTO employees VALUES(10012,'1953-11-07','Mary','Sluis','F','1989-09-12');
INSERT INTO employees VALUES(10013,'1954-05-01','Chirstian','Koblick','M','1994-09-15');
根据示例,你的查询应返回以下结果:

查询代码如下:
-- 方法一:利用窗口函数dense_rank()
select
emp_no,birth_date,first_name,last_name,gender,hire_date
from (
select
*
,dense_rank() over (order by hire_date desc) as rk
from employees
) as t
where t.rk = 3;
-- 方法二:利用分组去重
select
*
from employees
where hire_date = (
select hire_date
from employees
group by hire_date
order by hire_date desc
# limit 1 offset 2
limit 2,1
);
-- 方法三:利用distinct去重
select
*
from employees
where hire_date = (
select distinct hire_date
from employees
order by hire_date desc
# limit 1 offset 2
limit 2,1
);
PS:
一、排序函数:
rank()排序相同时会重复,总数不变,即会出现1、1、3这样的排序结果;
dense_rank()排序相同时会重复,总数会减少,即会出现1、1、2这样的排序结果;
row_number()排序相同时不会重复,会根据顺序排序。
这三种排序函数得到的列别名可用于order by 排序,因为order by执行在select之后。
where, group by, having都不可引用该列,因为这些语句执行在select之前,此时函数尚未计算出值。
二、limit函数
limit有两种方式。limit a,b 后缀两个参数的时候(参数必须是一个整数常量),其中a是指记录开始的偏移量,b是指从第a+1条开始,取b条记录;limit b 后缀一个参数的时候,是直接取值到第多少位,类似于:limit 0,b 。
三、distinct 和 group by 的区别
两者都可以用来去重。不同之处,distinct 是针对要查询的全部字段去重,而 group by 可以针对要查询的全部字段中的部分字段去重,它的作用主要是:获取数据表中以分组字段为依据的其他统计数据。使用group by 时一般会用到聚合函数。聚合函数对一组值执行计算,并返回单个值,也被称为组函数。 聚合函数经常与 select 语句的 group by 子句的having一同使用
SQL中提供的聚合函数可以用来统计、求和、求最值等等。
分类:
–count:统计行数量
–sum:获取单个列的合计值
–avg:计算某个列的平均值
–max:计算列的最大值
–min:计算列的最小值
十三、SQL212 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
描述
SQL212 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
有一个员工表employees简况如下:

有一个薪水表salaries简况如下:

建表代码如下:
drop table if exists `employees` ;
drop table if exists `salaries` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10003,43311,'2001-12-01','9999-01-01');
INSERT INTO salaries VALUES(10004,74057,'2001-11-27','9999-01-01');
请你查找薪水排名第二多的员工编号emp_no、薪水salary、last_name以及first_name,不能使用order by完成,以上例子输出为:

查询代码如下:
-- 方法一:max()嵌套
select
e.emp_no,salary,last_name,first_name
from employees as e
left join (
select
emp_no,salary,to_date
from salaries
where salary = (
select max(salary)
from salaries
where salary != (
select
max(salary)
from salaries
)
)
) as s
on e.emp_no = s.emp_no
where salary is not null and to_date = '9999-01-01';
-- 方法二:自身连接(解题思路值得学习)
select
e.emp_no,
salary,
last_name,
first_name
from employees as e
join salaries as s
on e.emp_no = s.emp_no
where salary = (
select
s1.salary
from salaries as s1
left join salaries as s2
on s1.salary <= s2.salary
group by s1.salary
having count(distinct s2.salary) = 2)
and to_date = '9999-01-01';
PS:窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
语法为:<窗口函数> over (partition by 分组字段 order by 排序字段), 其中分组和排序字段不是必须项,视问题情况而定。窗口函数主要分为3类,分别是聚合窗口函数、排序窗口函数、偏移窗口函数。
聚合窗口函数是avg、sum、count、max、min等;
排序窗口函数是rank、dense_rank、row_number;
偏移窗口函数是lag、lead。
十四、窗口函数演示
语法表达式:函数名([expr]) over(partition by<要分列的组> order by<要排序的列> rows between<数据范围>)
over是关键字,用来指定函数执行的窗口范围,包含三个分析子句:
三个分析子句:分组(partition by)子句,排序(order by)子句,窗口(rows)子句
如果后面括号中什么都不写,则意味着窗口包含满足where 条件的所有行,窗口函数基于所有行进行计算
如果不为空,则支持以下语法来设置窗口。
rows between 2 preceding and current row – 取当前行和前面两行
rows between 3 preceding and 1 following – 从前面三行和下面一行,总共五行
rows between unbounded preceding and current row – 包括之前所有的行和本行
rows between current row and unbounded following – 包括本行和之后所有的行
当order by存在,后面窗口从句缺失时,窗口规范默认是rows between unbounded preceding and current row.——包括本行和之前的所有的行
当order by和窗口从句两者都缺失时, 窗口规范默认是 rows between unbounded preceding and unbounded following——包括之前所有的行和之后所有的行
示例:test表

建表语句:
drop table if exists test;
create table test (`id` int ,`group` varchar(10) ,`num` int );
insert into test
select 1,'A',100 union all
select 2,'A',200 union all
select 3,'A',200 union all
select 4,'A',300 union all
select 1,'B',1000 union all
select 2,'B',500 union all
select 3,'B',500 union all
select 1,'C',10000 union all
select 5,'A',50;
【聚合窗口函数】
1.avg(value) over ()

查询代码如下:
select
`id`
,`group`
,`num`
,avg(`num`) over ()
,avg(`num`) over (partition by `group`)
,avg(`num`) over (order by `num`)
,avg(`num`) over (partition by `group` order by `num`)
from test
order by `group`;
2.sum(value) over ()

查询代码如下:
select
`id`
,`group`
,`num`
,sum(`num`) over ()
,sum(`num`) over (partition by `group`)
,sum(`num`) over (order by `num`)
,sum(`num`) over (partition by `group` order by `num`)
from test
order by `group`;
3.count(value) over ()

查询代码如下:
select
`id`
,`group`
,`num`
,count(`num`) over ()
,count(`num`) over (partition by `group`)
,count(`num`) over (order by `num`)
,count(`num`) over (partition by `group` order by `num`)
from test
order by `group`;
4.max(value) over ()

查询代码如下:
select
`id`
,`group`
,`num`
,max(`num`) over ()
,max(`num`) over (partition by `group`)
,max(`num`) over (order by `num`)
,max(`num`) over (partition by `group` order by `num`)
from test
order by `group`;
5.min(value) over ()

查询代码如下:
select
`id`
,`group`
,`num`
,min(`num`) over ()
,min(`num`) over (partition by `group`)
,min(`num`) over (order by `num`)
,min(`num`) over (partition by `group` order by `num`)
from test
order by `group`;
【排序窗口函数】
1.rank() over ()

查询代码如下:
select
`id`
,`group`
,`num`
,rank() over ()
,rank() over (partition by `group`)
,rank() over (order by `num`)
,rank() over (partition by `group` order by `num`)
from test
order by `group`;
2.dense_rank() over ()

查询代码如下:
select
`id`
,`group`
,`num`
,dense_rank() over ()
,dense_rank() over (partition by `group`)
,dense_rank() over (order by `num`)
,dense_rank() over (partition by `group` order by `num`)
from test
order by `group`;
3.row_number() over ()

查询代码如下:
select
`id`
,`group`
,`num`
,row_number() over ()
,row_number() over (partition by `group`)
,row_number() over (order by `num`)
,row_number() over (partition by `group` order by `num`)
from test
order by `group`;
4.ntile(n) over ()
用于将分组数据按照顺序切分成n个相等的小切片,为每一行分配该小切片的数字序号。如果切片不均匀,默认增加第一个切片的分布。

查询代码如下:
select
`id`
,`group`
,`num`
,ntile(3) over ()
,ntile(3) over (partition by `group`)
,ntile(3) over (order by `num`)
,ntile(3) over (partition by `group` order by `num`)
from test
order by `group`;
【偏移窗口函数】
1.lag(value, offset, default) over ()
它用于访问结果集中当前行的前面的行中的数据。

查询代码如下:
-- 写法一
select
`id`
,`group`
,`num`
,lag(`num`) over ()
,lag(`num`) over (partition by `group`)
,lag(`num`) over (order by `num`)
,lag(`num`) over (partition by `group` order by `num`)
from test
order by `group`;
-- 写法二
select
`id`
,`group`
,`num`
,lag(`num`,1,null) over ()
,lag(`num`,1,null) over (partition by `group`)
,lag(`num`,1,null) over (order by `num`)
,lag(`num`,1,null) over (partition by `group` order by `num`)
from test
order by `group`;
2.lead(value, offset, default) over ()
它用于访问结果集中当前行的后面的行中的数据。

查询代码如下:
-- 方法一
select
`id`
,`group`
,`num`
,lead(`num`,1,null) over ()
,lead(`num`,1,null) over (partition by `group`)
,lead(`num`,1,null) over (order by `num`)
,lead(`num`,1,null) over (partition by `group` order by `num`)
from test
order by `group`;
-- 方法二
select
`id`
,`group`
,`num`
,lead(`num`) over ()
,lead(`num`) over (partition by `group`)
,lead(`num`) over (order by `num`)
,lead(`num`) over (partition by `group` order by `num`)
from test
order by `group`;
3.first_value(value) over ()
它从定义的窗口中返回第一个值,基于指定的排序顺序。这个函数非常有用,尤其是在需要从每个分组中提取最初记录的情景中。

查询代码如下:
select
`id`
,`group`
,`num`
,first_value(`num`) over ()
,first_value(`num`) over (partition by `group`)
,first_value(`num`) over (order by `num`)
,first_value(`num`) over (partition by `group` order by `num`)
from test
order by `group`;
4.last_value(value) over ()
last_value函数与first_value函数用法大致相同,不同的是,其获取的是窗口中的最后一个值。

查询代码如下:
select
`id`
,`group`
,`num`
,last_value(`num`) over ()
,last_value(`num`) over (partition by `group`)
,last_value(`num`) over (order by `num`)
,last_value(`num`) over (partition by `group` order by `num`)
from test
order by `group`;
十五、SQL215 查找在职员工自入职以来的薪水涨幅情况
描述
请你查找在职员工自入职以来的薪水涨幅情况,给出在职员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序,以上例子输出为
(注: to_date为薪资调整某个结束日期,或者为离职日期,to_date='9999-01-01’时,表示依然在职,无后续调整记录)
有一个员工表employees简况如下:

有一个薪水表salaries简况如下:

建表代码如下:
查询结果为:

查询代码如下:
-- 方法一
select
a.emp_no,
(b.salary-a.salary) as growth
from ( -- 入职工资表
select
e.emp_no,
s.salary
from employees as e
join salaries as s
on e.emp_no = s.emp_no
where e.hire_date = s.from_date
) as a
join ( -- 现在工资表
select
e.emp_no,
s.salary
from employees as e
join salaries as s
on e.emp_no = s.emp_no
where s.to_date = '9999-01-01'
) as b
on a.emp_no = b.emp_no
order by growth asc;
-- 方法二
select
e.emp_no, (s2.salary-s1.salary) growth
from employees e
join salaries s1
on e.emp_no=s1.emp_no and e.hire_date=s1.from_date
join salaries s2
on e.emp_no=s2.emp_no and s2.to_date='9999-01-01'
order by growth;
-- 方法三 思考下窗口函数的用法
select
emp_no,
case count(1)
when 1 then 0
else sum(case when r2 = 1 then salary * -1 else salary end )
end as growth
from(
select
*,
row_number() over (partition by emp_no order by from_date desc) as r1,
row_number() over (partition by emp_no order by from_date asc ) as r2,
first_value(to_date) over(partition by emp_no order by to_date desc) as f_dt
from
salaries s
) t
where
f_dt = '9999-01-01' and (r1 = 1 or r2 = 1)
group by
emp_no
order by
growth asc;
十六、SQL219 获取员工其当前的薪水比其manager当前薪水还高的相关信息
描述
获取员工其当前的薪水比其manager当前薪水还高的相关信息,
第一列给出员工的emp_no,
第二列给出其manager的manager_no,
第三列给出该员工当前的薪水emp_salary,
第四列给该员工对应的manager当前的薪水manager_salary
有一个,部门关系表dept_emp简况如下:

有一个部门经理表dept_manager简况如下:

有一个薪水表salaries简况如下:

建表代码如下:
drop table if exists `dept_emp` ;
drop table if exists `dept_manager` ;
drop table if exists `salaries` ;
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO dept_emp VALUES(10001,'d001','1986-06-26','9999-01-01');
INSERT INTO dept_emp VALUES(10002,'d001','1996-08-03','9999-01-01');
INSERT INTO dept_manager VALUES('d001',10002,'1996-08-03','9999-01-01');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'1996-08-03','9999-01-01');
查询结果如下:

查询代码如下:
select de.emp_no , dm.emp_no, s.salary, s1.salary
#目的:造了一张所有员工的薪资表以及加上一列其部门经理的薪资
#先造一张薪资表
from (dept_emp de join salaries s on de.emp_no = s.emp_no)
#造一张部门经理薪资表
join (dept_manager dm join salaries s1 on dm.emp_no = s1.emp_no)
#按照部门号去做笛卡尔积目的达成
on de.dept_no = dm.dept_no
where s.salary > s1.salary;
十七、SQL226 将employees表的所有员工的last_name和first_name拼接起来
描述
请将employees表的所有员工的last_name和first_name拼接起来作为Name,中间以一个空格区分。
现有员工表employees如下:

建表代码如下:
drop table if exists `employees` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');
示例查询结果为:

查询代码如下:
select
concat(rtrim(last_name), ' ', ltrim(first_name)) as Name
# ,concat_ws(' ',rtrim(last_name),ltrim(first_name)) as Name
from employees;
PS:
ltrim, rtrim, 和 trim 函数分别用来除去字符串开始的空格、尾部空格、 开始和尾部空格:
ltrim(" vbscript “),输出 “vbscript " —返回不带前空格
rtrim(” vbscript “),输出 " vbscript” —返回不带后空格
trim(” vbscript "),输出 “vbscript” —返回前后不带空格
rim(leading ‘vbs’ from ‘vbscriptvbs’),输出‘scriptvbs’
trim(trailing ‘vbs’ from ‘vbscriptvbs’) ,输出’vbscript’
trim(both ‘vbs’ from ‘vbscriptvbs’) ,输出’cript’
常见的列转行函数
一、concat()函数
1、定义:将多个字符串连接成一个字符串。
2、使用语法:concat(str1,‘-’ str2,…)
返回字符串参数不能为null,否则返回值为null。
示例
查询代码如下:
select
concat(null,'/',first_name)
,concat(first_name,'/',null)
,concat(first_name,null,last_name)
,concat(first_name,'/',last_name,'/',gender)
from employees;
二、concat_ws()函数
1、定义:将多个字符串连接成一个字符串,可以一次性指定分隔符-,要不然有10个参数写10个太麻烦了。
2、使用语法:concat(‘-’,str1, str2,…)
返回字符串参数可以为空,但分隔符不能为null,否则返回值为null。
示例

查询代码如下:
select
concat_ws('/',null,last_name)
,concat_ws('/',first_name,null)
,concat_ws(null,first_name,last_name)
,concat_ws('/',first_name,last_name,gender)
from employees;
三、group_concat()函数
1、定义:参数是可以直接使用order by排序的,适合多表查询,把对应表和这个表相关的组成一个组一条记录。
2、使用语法:concat(str1, str2 order by str2 asc separator ‘~’)
示例

查询代码如下:
select
group_concat(gender)
,group_concat(emp_no,'/',gender)
,group_concat(emp_no,'/',gender,'/',day(hire_date))
from employees;
十八、SQL229 批量插入数据,不使用replace操作
描述
创建一个actor表,包含如下列信息
| 列表 | 类型 | 是否为NULL | 含义 |
|---|---|---|---|
| actor_id | smallint(5) | not null | 主键id |
| first_name | varchar(5 | not null | 名字 |
| last_name | varchar(45) | not null | 姓氏 |
| last_update | timestamp | not null | 最后更新时间,默认是系统的当前时间 |
并向表中插入以下数据:
‘1’,‘PENELOPE’,‘GUINESS’,‘2006-02-15 12:34:33’
‘2’,‘NICK’,‘WAHLBERG’,‘2006-02-15 12:34:33’
另有一个actor_n表

建表代码如下:
create table if not exists `actor_n`(
actor_id smallint(5) not null,
first_name varchar(45) not null,
last_name varchar(45) not null,
last_update timestamp not null,
primary key (actor_id)
);
insert into actor_n values ('1','PENELOPE','GUINESS','2006-02-15 12:34:33'),
('2','NICK','WAHLBERG','2006-02-15 12:34:33');
现向actor表中插入数据,操作代码如下:
-- 创建表
create table if not exists `actor`(
actor_id smallint(5) not null,
first_name varchar(45) not null,
last_name varchar(45) not null,
last_update timestamp not null,
primary key (actor_id)
);
-- 插入数据:方法一
insert into actor values ('1','PENELOPE','GUINESS','2006-02-15 12:34:33'),
('2','NICK','WAHLBERG','2006-02-15 12:34:33');
-- 插入数据:方法二
insert into actor
select
actor_id,first_name,last_name,last_update
from actor_n;
对于表actor插入如下数据,如果数据已经存在,请忽略(不支持使用replace操作)
插入代码需调整为:
insert ignore into actor values ('1','PENELOPE','GUINESS','2006-02-15 12:34:33'),
('2','NICK','WAHLBERG','2006-02-15 12:34:33');
PS:常见的插入指令的区别
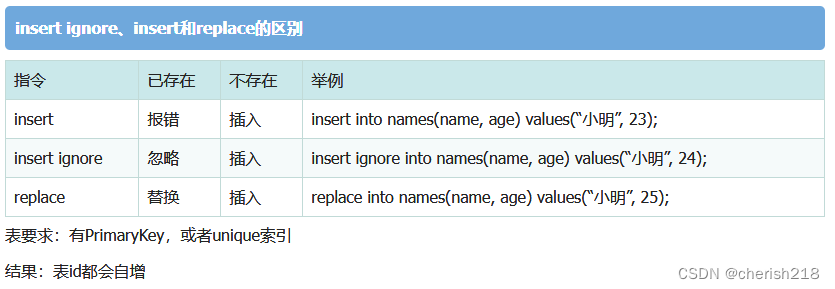
十九、SQL232 针对actor表创建视图actor_name_view
描述
针对actor表创建视图actor_name_view,只包含first_name以及last_name两列,并对这两列重新命名,first_name为first_name_v,last_name修改为last_name_v,插入2条数据:
(‘1’, ‘PENELOPE’, ‘GUINESS’, ‘2006-02-15 12:34:33’), (‘2’, ‘NICK’, ‘WAHLBERG’, ‘2006-02-15 12:34:33’);
然后打印视图名字和插入的数据
操作代码如下:
-- 建表
CREATE TABLE actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update datetime NOT NULL);
-- 插入数据
insert into actor values ('1', 'PENELOPE', 'GUINESS', '2006-02-15 12:34:33'),
('2', 'NICK', 'WAHLBERG', '2006-02-15 12:34:33');
-- 创建视图
#方法一
create view actor_name_view (first_name_v, last_name_v) as
select first_name, last_name from actor;
#方法二
create view actor_name_view as
select first_name as first_name_v, last_name as last_name_v from actor;
PS:视图是一个虚拟表(非真实存在),其本质是:根据SQL语句获取动态的数据集,并为其命名。用户使用时只需使用“名称”即可获取结果集,并可以将其当作表来使用。
创建视图语法:
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
修改视图语法:
ALTER [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)] AS
SELECT…
删除视图语法:
DROP VIEW [IF EXISTS] v1;
插入、更新与表用法一样,视图本质上就是虚拟表。
二十、SQL233 针对上面的salaries表emp_no字段创建索引idx_emp_no
针对salaries表emp_no字段创建索引idx_emp_no,查询emp_no为10005,使用强制索引。
建表代码如下:
drop table if exists salaries;
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
create index idx_emp_no on salaries(emp_no);
INSERT INTO salaries VALUES(10005,78228,'1989-09-12','1990-09-12');
INSERT INTO salaries VALUES(10005,94692,'2001-09-09','9999-01-01');
操作代码如下:
-- 强制索引
select * from salaries force index (idx_emp_no) where emp_no = '10005';
-- 普通索引
select * from salaries use index (idx_emp_no) where emp_no = '10005';
-- 禁止索引
select * from salaries ignore index (idx_emp_no) where emp_no = '10005';
PS:
show indexs from '表名'; //查看表的索引
show keys from '表名'; //查看表的索引
show status like '%Handler_read%'; //查看索引的使用情况
handler_read_key:这个值越高越好,越高表示使用索引查询到的次数
handler_read_rnd_next:这个值越高,说明查询低效
alter table 表名 add primary key pk_nm(列名); //增加主键索引
alter table 表名 drop primary key(列名); //删除主键索引
alter table 表名 add unique(列名); //添加唯一索引
alter table 表名 add index 索引名(列1, 列2...); //添加普通索引
create index 索引的名字 on 表名(列名); //添加普通索引
create unique index 索引的名字 on 表名(列名); //创建唯一索引
CREATE [UNIQUE] [CLUSTERED| NONCLUSTERED] INDEX <索引名>
ON <表名>(<列名1>[ASC|DESC] [, <列名2>[ASC|DESC]...])
alter table 表名 rename as/to 新表名 //变更表名
alter table 表名 modify 列名 int auto_increment; //修改列
alter table 表名 add 列名 varchar(255) not null after 列名; //增加字段在某字段之后
alter table 表名 drop 列名; //删除字段
ALTER TABLE table_name MODIFY COLUMN column_name datatype; //修改字段
ALTER TABLE table_name ALTER COLUMN column_name SET DEFAULT default_value; //添加默认值
ALTER TABLE table_name DROP INDEX index_name //删除索引
DROP TABLE table_name //删除表
TRUNCATE TABLE table_name //只删除数据,不删除表本身
DROP DATABASE database_name //删除数据库
//使用 ALTER TABLE 添加 NOT NULL 约束的基本语法如下:
ALTER TABLE table_name MODIFY column_name datatype NOT NULL;
//使用 ALTER TABLE 添加 UNIQUE 约束的基本语法如下:
ALTER TABLE table_name
ADD CONSTRAINT MyUniqueConstraint UNIQUE(column1, column2...);
//使用 ALTER TABLE 添加 CHECK 约束的基本语法如下:
ALTER TABLE table_name
ADD CONSTRAINT MyUniqueConstraint CHECK (CONDITION);
//使用 ALTER TABLE 添加主键约束的基本语法如下:
ALTER TABLE table_name
ADD CONSTRAINT MyPrimaryKey PRIMARY KEY (column1, column2...);
//添加外键约束语法如下:
ALTER TABLE <数据表名> ADD CONSTRAINT <外键名>
FOREIGN KEY(<列名>) REFERENCES <主表名> (<列名>);
//删除外键约束语法如下:
ALTER TABLE <表名> DROP FOREIGN KEY <外键约束名>;
//使用 ALTER TABLE 删除 UNIQUE 约束的基本语法如下:
ALTER TABLE table_name
DROP CONSTRAINT MyUniqueConstraint;
//如果您使用的是 MySQL,请修改为:
ALTER TABLE table_name
DROP INDEX MyUniqueConstraint;
//使用 ALTER TABLE 删除主键约束的基本语法如下:
ALTER TABLE table_name
DROP CONSTRAINT MyPrimaryKey;
//如果您使用的是 MySQL,请修改为:
ALTER TABLE table_name
DROP PRIMARY KEY;
二十一、SQL235 构造一个触发器audit_log
描述
构造一个触发器audit_log,在向employees_test表中插入一条数据的时候,触发插入相关的数据到audit中。
CREATE TABLE employees_test(
CREATE TABLE employees_test(
ID INT PRIMARY KEY NOT NULL,
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
NOT NULL,
AGE INT NOT NULL,
不为空,
ADDRESS CHAR(50),
地址字符(50),
SALARY REAL
实际真实的
);
CREATE TABLE audit(
CREATE TABLE审计(
EMP_no INT NOT NULL,
EMP_no INT NOT NULL,
NAME TEXT NOT NULL
名称文本不为空
);
后台会往employees_test插入一条数据:
INSERT INTO employees_test (ID,NAME,AGE,ADDRESS,SALARY)VALUES (1, ‘Paul’, 32, ‘California’, 20000.00 );
INTO employees_test(ID,NAME,AGE,ADDRESS,SALARY)VALUES(1,‘Paul’,32,‘California’,20000.00);
然后从audit里面使用查询语句:
select * from audit;
从审计中选择 *;
建表代码如下:
drop table if exists audit;
drop table if exists employees_test;
CREATE TABLE employees_test(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
CREATE TABLE audit(
EMP_no INT NOT NULL,
NAME TEXT NOT NULL
);
操作代码如下:
create trigger audit_log
after insert on employees_test
for each row
begin
insert into audit values(new.id,new.name);
end
PS:在MySQL中,创建触发器语法如下:
CREATE TRIGGER trigger_name
trigger_time trigger_event ON tbl_name
FOR EACH ROW
trigger_stmt
其中:
trigger_name:标识触发器名称,用户自行指定;
trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句,每条语句结束要分号结尾。
【NEW 与 OLD 详解】
MySQL 中定义了 NEW 和 OLD,用来表示
触发器的所在表中,触发了触发器的那一行数据。
具体地:
在 INSERT 型触发器中,NEW 用来表示将要(BEFORE)或已经(AFTER)插入的新数据;
在 UPDATE 型触发器中,OLD 用来表示将要或已经被修改的原数据,NEW 用来表示将要或已经修改为的新数据;
在 DELETE 型触发器中,OLD 用来表示将要或已经被删除的原数据;
使用方法: NEW.columnName (columnName 为相应数据表某一列名)
二十二、SQL236 删除emp_no重复的记录,只保留最小的id对应的记录。
描述
删除emp_no重复的记录,只保留最小的id对应的记录。
CREATE TABLE IF NOT EXISTS titles_test (
id int(11) not null primary key,
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
insert into titles_test values (‘1’, ‘10001’, ‘Senior Engineer’, ‘1986-06-26’, ‘9999-01-01’),
(‘2’, ‘10002’, ‘Staff’, ‘1996-08-03’, ‘9999-01-01’),
(‘3’, ‘10003’, ‘Senior Engineer’, ‘1995-12-03’, ‘9999-01-01’),
(‘4’, ‘10004’, ‘Senior Engineer’, ‘1995-12-03’, ‘9999-01-01’),
(‘5’, ‘10001’, ‘Senior Engineer’, ‘1986-06-26’, ‘9999-01-01’),
(‘6’, ‘10002’, ‘Staff’, ‘1996-08-03’, ‘9999-01-01’),
(‘7’, ‘10003’, ‘Senior Engineer’, ‘1995-12-03’, ‘9999-01-01’);
删除后titles_test表为(注:最后会select * from titles_test表来对比结果)
建表代码如下:
drop table if exists titles_test;
CREATE TABLE titles_test (
id int(11) not null primary key,
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
insert into titles_test values
('1', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('2', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('3', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('4', '10004', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('5', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('6', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('7', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01');
查询代码如下:
-- 常规解法
delete from titles_test
where id not in
(
select min(id)
from titles_test
group by emp_no
);
//遭遇问题:you can't specify target table 'titles_test' for update in FROM clause
//原因:在MYSQL里,不能先select一个表的记录,在按此条件进行更新和删除同一个表的记录,
//解决办法:将select得到的结果,再通过中间表select一遍,这样就规避了错误,这个问题只出现于mysql,mssql和oracle不会出现此问题。
delete from titles_test
where id not in
(
select *
from (
select min(id)
from titles_test
group by emp_no
) as t
);
PS:mysql不允许在子查询的同时删除原表数据
二十三、SQL237 将所有to_date为9999-01-01的全部更新为NULL
描述
将所有to_date为9999-01-01的全部更新为NULL,且 from_date更新为2001-01-01。
示例表:titles_test

建表代码如下:
drop table if exists titles_test;
CREATE TABLE titles_test (
id int(11) not null primary key,
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
insert into titles_test values
('1', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('2', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('3', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('4', '10004', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('5', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('6', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('7', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01');
更新效果如下:

操作代码如下:
-- 插入数据
insert into titles_test values ('8', '10005', 'Tibetan Cherry', '1986-11-03', '9999-01-01');
-- 删除数据
delete from titles_test where id = '8';
-- 更新数据
update titles_test set to_date = NULL,from_date = '2001-01-01' where to_date = '9999-01-01';
//注意NULL不能加引号
二十四、SQL238 将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005
描述
将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005,其他数据保持不变,使用replace实现。
示例表:titles_test

建表代码如下:
drop table if exists titles_test;
CREATE TABLE titles_test (
id int(11) not null primary key,
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
insert into titles_test values
('1', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('2', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('3', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('4', '10004', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('5', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('6', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('7', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01');
表格更新效果如下:

操作代码如下:
-- 使用replace
update titles_test
set emp_no = replace(emp_no, 10001, 10005)
where id = 5;
-- 使用insert
insert into titles_test
values(5, 10001 ,'Senior Engineer', '1986-06-26', '9999-01-01')
on duplicate key update emp_no = 10005;
-- 使用replace into
replace into titles_test
values(5, 10005 ,'Senior Engineer', '1986-06-26', '9999-01-01') ;
PS:“on duplicate key” 是在执行插入操作时的一个选项,它指示在遇到已经存在的键值时要执行的操作。当在数据库中使用插入操作时,如果键值已经存在,会触发错误。使用“on duplicate key”选项可以定义在遇到这种情况时要执行的操作。
例如,在MySQL中,可以在INSERT语句中使用“ON DUPLICATE KEY UPDATE”语句来指定在遇到重复键时要执行的操作。这个选项后面通常跟着一个或多个列名和值对,表示在遇到重复键时更新这些列的值。
二十五、SQL240 在audit表上创建外键约束,其emp_no对应employees_test表的主键id
在audit表上创建外键约束,其emp_no对应employees_test表的主键id。
示例表1:employees
建表代码如下:
drop table if exists employees;
-- 方法一
CREATE TABLE employees_test(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
-- 方法二
CREATE TABLE employees_test(
ID INT NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
primary key (id)
);
示例表2:audit
建表代码如下:
drop table if exists audit;
CREATE TABLE audit(
EMP_no INT NOT NULL,
create_date datetime NOT NULL
);
操作代码如下:
alter table audit add constraint fk1 foreign key (emp_no) references employees_test(id);
//创建外键语句结构:
ALTER TABLE table_name
constraint 约束名 foreign key(外键列)
references 主键表(主键列)
//创建主键语句结构:
ALTER TABLE table_name
constraint 约束名 primary key (主键列);
二十六、SQL248 平均工资
描述
查找排除在职(to_date = ‘9999-01-01’ )员工的最大、最小salary之后,其他的在职员工的平均工资avg_salary。
示例表:salaries

建表代码如下:
drop table if exists `salaries` ;
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` float(11,3) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO salaries VALUES(10001,85097,'2001-06-22','2002-06-22');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10003,43699,'2000-12-01','2001-12-01');
INSERT INTO salaries VALUES(10003,43311,'2001-12-01','9999-01-01');
INSERT INTO salaries VALUES(10004,70698,'2000-11-27','2001-11-27');
INSERT INTO salaries VALUES(10004,74057,'2001-11-27','9999-01-01');
所求结果如下:

操作代码为:
//使用聚合函数求解为最优解
select
(sum(salary)-max(salary)-min(salary)) / (count(1)-2) as avg_salary
from salaries
where to_date = '9999-01-01';
二十七、SQL249 分页查询employees表,每5行一页,返回第2页的数据
描述
分页查询employees表,每5行一页,返回第2页的数据
示例表:employees

建表代码如下:
drop table if exists `employees` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');
所示结果为:

操作代码为:
select *
from employees
limit 5,5;
//一般分页使用 order by + limit 。本题要求5行/页,则第二页显示第6-10行。
limit x,y x:偏移量 y:要获取的个数
limit 5,5; 偏移量为5,取5条记录
limit y offset x
limit 5 offset 5; 取5条记录,偏移量为5
二十八、SQL251 使用含有关键字exists查找未分配具体部门的员工的所有信息。
描述
使用含有关键字exists查找未分配具体部门的员工的所有信息。
示例表1:employees

示例例2:dept_emp

建表代码如下:
drop table if exists employees;
drop table if exists dept_emp;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');
INSERT INTO dept_emp VALUES(10001,'d001','1986-06-26','9999-01-01');
INSERT INTO dept_emp VALUES(10002,'d001','1996-08-03','9999-01-01');
INSERT INTO dept_emp VALUES(10003,'d004','1995-12-03','9999-01-01');
INSERT INTO dept_emp VALUES(10004,'d004','1986-12-01','9999-01-01');
INSERT INTO dept_emp VALUES(10005,'d003','1989-09-12','9999-01-01');
INSERT INTO dept_emp VALUES(10006,'d002','1990-08-05','9999-01-01');
INSERT INTO dept_emp VALUES(10007,'d005','1989-02-10','9999-01-01');
INSERT INTO dept_emp VALUES(10008,'d005','1998-03-11','2000-07-31');
INSERT INTO dept_emp VALUES(10009,'d006','1985-02-18','9999-01-01');
INSERT INTO dept_emp VALUES(10010,'d005','1996-11-24','2000-06-26');
INSERT INTO dept_emp VALUES(10010,'d006','2000-06-26','9999-01-01');
查询结果展示如下:

操作代码如下:
-- 解法一
select *
from employees as e
where not exists (
select *
from dept_emp as d
where e.emp_no = d.emp_no
);
-- 解法二
select *
from employees
where emp_no not in
(
select emp_no
from dept_emp
)
PS:
EXISTS语句:执行employees.length次
指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
IN 语句:只执行一次
确定给定的值是否与子查询或列表中的值相匹配。in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。所以相对内表比较小的时候,in的速度较快。
二十九、SQL255 给出employees表中排名为奇数行的first_name
示例表:employees

建表代码如下:
drop table if exists `employees` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
查询结果展示如下:

操作代码如下:
select
e.first_name as first
from employees as e
left join ( //思考下为会么要用表连接来做?
select
*
,row_number() over (order by first_name) as rn
from employees
) as t
on e.first_name = t.first_name
where rn % 2 != 0 ;
三十、SQL263 牛客每个人最近的登录日期(四)
描述
牛客每天有很多人登录,请你统计一下牛客每个日期登录新用户个数。
有一个登录(login)记录表,简况如下:

建表代码如下:
drop table if exists login;
CREATE TABLE `login` (
`id` int(4) NOT NULL,
`user_id` int(4) NOT NULL,
`client_id` int(4) NOT NULL,
`date` date NOT NULL,
PRIMARY KEY (`id`));
INSERT INTO login VALUES
(1,2,1,'2020-10-12'),
(2,3,2,'2020-10-12'),
(3,1,2,'2020-10-12'),
(4,2,2,'2020-10-13'),
(5,1,2,'2020-10-13'),
(6,3,1,'2020-10-14'),
(7,4,1,'2020-10-14'),
(8,4,1,'2020-10-15');
查询结果展示如下:

操作代码如下:
-- 解法一
SELECT l.date, IFNULL(a.new_num, 0)
FROM login as l
LEFT JOIN(
SELECT date, COUNT(user_id) AS new_num
FROM login
WHERE (date, user_id) IN(
SELECT MIN(date), user_id
FROM login
GROUP BY user_id)
GROUP BY date)a
ON a.date = l.date
GROUP BY l.date
ORDER BY l.date;
-- 解法二
select a.date,
sum(case when t_rank=1 then 1 else 0 end) new
from
(select *, row_number() over(partition by user_id order by date) t_rank
from login) a
group by date;
PS:ifnull(expression, alt_value)函数是SQL中的一个条件判断函数,主要用于处理查询结果可能出现的NULL值问题。当某个字段或表达式的值为NULL时,IFNULL()会返回指定的替代值alt_value,否则返回原字段或表达式的实际值。
三十一、SQL264 牛客每个人最近的登录日期(五)
描述
牛客每天有很多人登录,请你写出一个sql语句查询每个日期新用户的次日留存率,结果保留小数点后面3位数(3位之后的四舍五入),并且查询结果按照日期升序排序。
有一个登录(login)记录表,简况如下:

建表代码如下:
drop table if exists login;
CREATE TABLE `login` (
`id` int(4) NOT NULL,
`user_id` int(4) NOT NULL,
`client_id` int(4) NOT NULL,
`date` date NOT NULL,
PRIMARY KEY (`id`));
INSERT INTO login VALUES
(1,2,1,'2020-10-12'),
(2,3,2,'2020-10-12'),
(3,1,2,'2020-10-12'),
(4,2,2,'2020-10-13'),
(5,1,2,'2020-10-13'),
(6,3,1,'2020-10-14'),
(7,4,1,'2020-10-14'),
(8,4,1,'2020-10-15');
上面的例子查询结果如下:

操作代码如下:
-- 解法一
select
date
,sum(case when (user_id,date) in (select user_id,date_add(date,interval -1 day) from login) and
(user_id,date) in (select user_id,min(date) from login group by user_id) then 1 else 0 end)/
(select count(date) from login where
(user_id,date) in (select user_id,min(date) from login group by user_id))
as p
from login
group by date;
-- 解法二
select t0.date,
ifnull(round(count(distinct t2.user_id)/(count(t1.user_id)),3),0) as p
from
(
select date
from login
group by date
) t0
left join
(
select user_id,min(date) as date
from login
group by user_id
)t1
on t0.date=t1.date
left join login as t2
on t1.user_id=t2.user_id and datediff(t2.date,t1.date)=1
group by t0.date;
三十二、SQL269 考试分数(四)
描述
请你写一个sql语句查询各个岗位分数升序排列之后的中位数位置的范围,并且按job升序排序。
示例:grade

建表代码如下:
drop table if exists grade;
CREATE TABLE grade(
`id` int(4) NOT NULL,
`job` varchar(32) NOT NULL,
`score` int(10) NOT NULL,
PRIMARY KEY (`id`));
INSERT INTO grade VALUES
(1,'C++',11001),
(2,'C++',10000),
(3,'C++',9000),
(4,'Java',12000),
(5,'Java',13000),
(6,'B',12000),
(7,'B',11000),
(8,'B',9999);
查询结果如下:

操作代码如下:
-- 使用floor
SELECT job,
floor(( count(*) + 1 )/ 2 ) AS start,
floor(( count(*) + 2 )/ 2 ) AS end
FROM grade
GROUP BY job
ORDER BY job;
-- 使用ceiling
select job
,case when count(score)%2=0 then ceiling(count(score)/2) else ceiling(count(score)/2)
end as start
,case when count(score)%2=0 then ceiling(count(score)/2+1) else ceiling(count(score)/2)
end as end
from grade
group by job
order by job;
-- 使用round
select job, round(count(id)/2) as start, round((count(id)+1)/2) as end
from grade
group by job
order by job;
-- 使用floor+ceiling
select job, floor((count(job) + 1)/2) as start, ceiling((count(job) + 1)/2) as end
from grade
group by job
order by job
PS:
ceil() / ceiling() 向上取整;示例: ceil(1.2) = 2
floor() 向下取整;示例: floor(1.2) = 1
round() 四舍五入
三十三、SQL270 考试分数(五)
描述
请你写一个sql语句查询各个岗位分数的中位数位置上的所有grade信息,并且按id升序排序。
示例表:grade

建表代码如下:
drop table if exists grade;
CREATE TABLE grade(
`id` int(4) NOT NULL,
`job` varchar(32) NOT NULL,
`score` int(10) NOT NULL,
PRIMARY KEY (`id`));
INSERT INTO grade VALUES
(1,'C++',11001),
(2,'C++',10000),
(3,'C++',9000),
(4,'Java',12000),
(5,'Java',13000),
(6,'B',12000),
(7,'B',11000),
(8,'B',9999);
查询结果如下:

操作代码如下:
-- 解法一
select id,job,score,t.rn as t_rank
from
(select *
,(row_number() over (partition by job order by score desc)) as rn
,(count(score) over (partition by job)) as num
from grade)t
where abs(t.rn-(t.num+1)/2)<1 //想一想为什么这样用?
order by id;
-- 解法二
select t1.id
,t1.job
,t1.score
,t1.s_rank
from
(select id,job,score
,(row_number()over(partition by job order by score desc))as s_rank
from grade)t1
join
(select job
,case when count(score)%2=0 then ceiling(count(score)/2) else ceiling(count(score)/2)
end as start1
,case when count(score)%2=0 then ceiling(count(score)/2+1) else ceiling(count(score)/2)
end as end1
from grade
group by job)t2
on t1.job=t2.job
where t1.s_rank=t2.start1&nbs***bsp;t1.s_rank=t2.end1
order by t1.id;
三十四、SQL280 实习广场投递简历分析(三)
描述
请你写出SQL语句查询在2025年投递简历的每个岗位,每一个月内收到简历的数目,和对应的2026年的同一个月同岗位,收到简历的数目,最后的结果先按first_year_mon月份降序,再按job降序排序显示。
示例:resume_info

建表代码如下:
drop table if exists resume_info;
CREATE TABLE resume_info (
id int(4) NOT NULL,
job varchar(64) NOT NULL,
date date NOT NULL,
num int(11) NOT NULL,
PRIMARY KEY (id));
INSERT INTO resume_info VALUES
(1,'C++','2025-01-02',53),
(2,'Python','2025-01-02',23),
(3,'Java','2025-01-02',12),
(4,'C++','2025-01-03',54),
(5,'Python','2025-01-03',43),
(6,'Java','2025-01-03',41),
(7,'Java','2025-02-03',24),
(8,'C++','2025-02-03',23),
(9,'Python','2025-02-03',34),
(10,'Java','2025-02-04',42),
(11,'C++','2025-02-04',45),
(12,'Python','2025-02-04',59),
(13,'C++','2026-01-04',230),
(14,'Java','2026-01-04',764),
(15,'Python','2026-01-04',644),
(16,'C++','2026-01-06',240),
(17,'Java','2026-01-06',714),
(18,'Python','2026-01-06',624),
(19,'C++','2026-02-14',260),
(20,'Java','2026-02-14',721),
(21,'Python','2026-02-14',321),
(22,'C++','2026-02-24',134),
(23,'Java','2026-02-24',928),
(24,'Python','2026-02-24',525),
(25,'C++','2027-02-06',231);
查询结果如下:

查询代码如下:
-- 解法一
select
distinct
t1.job
,t1.date1 as first_year_mon
,t1.num as first_year_cnt
,t2.date1 as second_year_mon
,t2.num as second_year_cnt
from
(
select
job
,date_format(date,'%Y-%m') as date1
,sum(num) over (partition by job,date_format(date,'%Y-%m')) as num
from resume_info
where year(date) = '2025'
) t1
left join (
select
job
,date_format(date,'%Y-%m') as date1
,sum(num) over (partition by job,date_format(date,'%Y-%m')) as num
from resume_info
where year(date) = '2026'
) t2
on t1.job = t2.job
where left(t1.date1,4)+1=left(t2.date1,4) and right(t1.date1,2)=right(t2.date1,2)
order by first_year_mon desc,job desc;
-- 解法二
// 查询在2025年投递简历的每个岗位,每个月内收到简历的数量和,对应的2026年的同月同岗位收到简历的数量,最后的结果先
//按first_year_mon月份降序,再按job降序排序显示
SELECT h1.job,first_year_mon,first_year_cnt,second_year_mon,second_year_cnt
FROM
-- 2025年的
(SELECT job,DATE_FORMAT(DATE,'%Y-%m') AS first_year_mon,SUM(num) AS first_year_cnt
FROM resume_info
WHERE DATE LIKE '2025%' -- 符合最左前缀匹配原则,也走索引
GROUP BY job,first_year_mon) AS h1
-- inner join 假装优化下,inner可以省略
INNER JOIN
-- 2026年的
(SELECT job,DATE_FORMAT(DATE,'%Y-%m') AS second_year_mon,SUM(num) AS second_year_cnt
FROM resume_info
WHERE DATE LIKE '2026%' -- 符合最左前缀匹配原则,也走索引
GROUP BY job,second_year_mon) AS h2
-- 表连接条件:两表job相同且月份相同,
-- 因date日期类型经过 DATE_FORMAT()后变成 字符串,所以使用right()函数取后两位即为月数
ON h1.job=h2.job AND right(first_year_mon,2)=right(second_year_mon,2)
-- 排序
ORDER BY first_year_mon DESC,h1.job DESC;
PS:
RIGHT(s,n) 返回字符串 s 的后 n 个字符
LEFT(s,n) 返回字符串 s 的前 n 个字符
MID(s,n,len) 从字符串 s 的 n 位置截取长度为 len 的子字符串,同 SUBSTRING(s,n,len)
LCASE(s) 将字符串 s 的所有字母变成小写字母
三十五、SQL282 最差是第几名(二)
描述
TM小哥和FH小妹在牛客大学若干年后成立了牛客SQL班,班的每个人的综合成绩用A,B,C,D,E表示,90分以上都是A,8090分都是B,7080分为C,60~70为D,E为60分以下
假设每个名次最多1个人,比如有2个A,那么必定有1个A是第1名,有1个A是第2名(综合成绩同分也会按照某一门的成绩分先后)。
每次SQL考试完之后,老师会将班级成绩表展示给同学看。老师想知道学生们综合成绩的中位数是什么档位,请你写SQL帮忙查询一下,如果只有1个中位数,输出1个,如果有2个中位数,按grade升序输出。
示例:class_grade

建表代码:
drop table if exists class_grade;
CREATE TABLE class_grade (
grade varchar(32) NOT NULL,
number int(4) NOT NULL
);
INSERT INTO class_grade VALUES
('A',2),
('C',4),
('B',4),
('D',2);
查询结果如下:

查询代码如下:
select
grade
from (
select
grade
,(select sum(number) from class_grade) as total
,sum(number) over(order by grade) a
,sum(number) over(order by grade desc) b
from class_grade
) t1
where a >= total/2 and b >=total/2
order by grade;
三十六、SQL285 获得积分最多的人(三)
描述
牛客每天有很多用户刷题,发帖,点赞,点踩等等,这些都会记录相应的积分。请你写一个SQL查找积分最高的用户的id,名字,以及他的总积分是多少(可能有多个),查询结果按照id升序排序,
示例1:user

示例2:grade_info

建表代码:
drop table if exists user;
drop table if exists grade_info;
CREATE TABLE user (
id int(4) NOT NULL,
name varchar(32) NOT NULL
);
CREATE TABLE grade_info (
user_id int(4) NOT NULL,
grade_num int(4) NOT NULL,
type varchar(32) NOT NULL
);
INSERT INTO user VALUES
(1,'tm'),
(2,'wwy'),
(3,'zk'),
(4,'qq'),
(5,'lm');
INSERT INTO grade_info VALUES
(1,3,'add'),
(2,3,'add'),
(1,1,'reduce'),
(3,3,'add'),
(4,3,'add'),
(5,3,'add'),
(3,1,'reduce');
查询结果如下:

查询代码如下:
select t1.id,t1.name,t0.grade as grade_sum
from(
select user_id,grade,rank()over(order by grade desc) as t
from(
select user_id,sum(if(type='add',grade_num,-1*grade_num)) as grade
from grade_info
group by user_id
) a0
) t0
join user as t1
on t0.user_id = t1.id
where t=1;















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









