






#iOS 获取字符串中的单个字符
要取到单个字符,就要知道字符串的编码方式,这样才能够定位每个字符在内存中的位置。但是,iOS的字符串编码是不固定的,因此,需要设置一个统一的编码格式,将所有其他格式的字符串都转化为统一的格式,然后就可以根据编码规则取到单个字符了。在这里,使用UTF-8编码。UTF-8编码的使用范围比较广泛,客户端与服务器之间传输的数据大多以UTF-8编码。
关于UTF-8的详细说明可以Wiki下:UTF-8。
下图是UTF-8编码的格式:
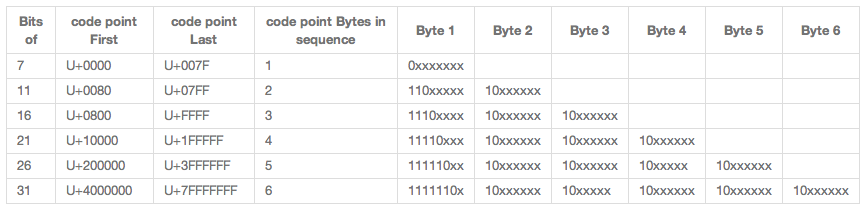
开发的流程大概是:
- 将NSString字符串转成UTF-8格式的char串。
- 从头依次读取char串中的字节。
- 根据上图中的'Byte 1'字段,判断当前字符占几个字节,并获取这几个字节。
- 将获取的几个字节转成NSString字符串对象。
- 获取下一个字符,进行3,只到获取最后的字符。
**有一点要注意:
<!-- lang: cpp -->
NSString *string = [NSString stringWithFormat:@"1a张"];
const char *chars = [string cStringUsingEncoding:NSUTF8StringEncoding];
for (int i = 0; i < strlen(chars); i++) {
printf("%x", chars[i]);
}
输出:3161ffffffe5ffffffbcffffffa0
在iOS中,非ASCII字符的前面都会加上ffffff,而不是直接使用UTF-8中规定的起始值。
下面是代码实现(使用类别):
NSString+StringToWords.h
<!-- lang: cpp -->
#import <Foundation/Foundation.h>
@interface NSString (StringToWords)
- (NSArray *)words;
@end
NSString+StringToWords.h
<!-- lang: cpp -->
#import "NSString+StringToWords.h"
@implementation NSString (StringToWords)
- (NSArray *)words
{
#if ! __has_feature(objc_arc)
NSMutableArray *words = [[[NSMutableArray alloc] init] autorelease];
#else
NSMutableArray *words = [[NSMutableArray alloc] init];
#endif
const char *str = [self cStringUsingEncoding:NSUTF8StringEncoding];
char *word;
for (int i = 0; i < strlen(str);) {
int len = 0;
if (str[i] >= 0xFFFFFFFC) {
len = 6;
} else if (str[i] >= 0xFFFFFFF8) {
len = 5;
} else if (str[i] >= 0xFFFFFFF0) {
len = 4;
} else if (str[i] >= 0xFFFFFFE0) {
len = 3;
} else if (str[i] >= 0xFFFFFFC0) {
len = 2;
} else if (str[i] >= 0x00) {
len = 1;
}
word = malloc(sizeof(char) * (len + 1));
for (int j = 0; j < len; j++) {
word[j] = str[j + i];
}
word[len] = '\0';
i = i + len;
NSString *oneWord = [NSString stringWithCString:word encoding:NSUTF8StringEncoding];
free(word);
[words addObject:oneWord];
}
return words;
}
@end















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









