






不管人类的思维有多么缜密,也存在“智者千虑必有一失”的缺憾。无论计算机技术怎么发展,也不可能穷尽所有的场景,这个世界是不完美的,是有缺陷的,完美的世界只存在于理想中。
对于软件帝国的缔造者来说,程序也是不完美的,异常情况会随时出现,我们需要它为我们描述例外时间,需要它处理非预期的情景,需要它帮我们建立“完美世界”。
前言:浅谈Java异常
1、在Java中,所有的异常都有一个共同的祖先Throwable(可抛出)。
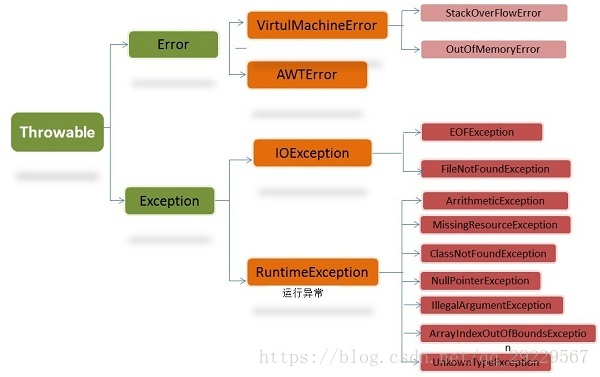
Throwable有两个子类:Exception和error。
Trowable类中常用方法如下:
1. 返回异常发生时的详细信息
public string getMessage();
2. 返回异常发生时的简要描述
public string toString();
3. 返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以声称本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同
public string getLocalizedMessage();
4. 在控制台上打印Throwable对象封装的异常信息
public void printStackTrace();
2、异常分两大类:
①运行时异常:都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不可查异常,这些异常一般由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这些异常的发生。运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。
Java的异常(Throwable)分为可查的异常(checked exceptions)和不可查的异常(unchecked exceptions)。
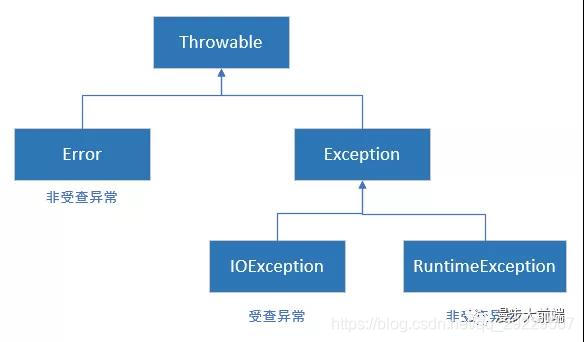
① 可查异常(编译器要求必须处置的异常):正确的程序在运行中,很容易出现的、情理可容的异常状况。除了Exception中的RuntimeException及其子类以外,其他的Exception类及其子类(例如:IOException和ClassNotFoundException)都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。
② 不可查异常(编译器不要求强制处置的异常):包括运行时异常(RuntimeException与其子类)和错误(Error)。
3、异常处理的机制
① 抛出异常:任何Java代码都可以抛出异常。
② 捕获异常:捕捉异常通过try-catch语句或者try-catch-finally语句实现。
finally 块:无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return语句时,finally语句块将在方法返回之前被执行。在以下4种特殊情况下,finally块不会被执行:
1)在finally语句块中发生了异常。
2)在前面的代码中用了System.exit()退出程序。
3)程序所在的线程死亡。
4)关闭CPU。
应该在声明方法抛出异常还是在方法中捕获异常?
捕捉并处理知道如何处理的异常,而抛出不知道如何处理的异常。
总体来说,Java规定:对于可查异常必须捕捉、或者声明抛出。允许忽略不可查的RuntimeException和Error。
Java中使用异常常见的问题
建议110:提倡异常封装
建议111:采用异常链传递异常
建议112:可查异常尽可能转化为不可查异常
建议113:不要在finally中处理返回值
建议114:不要在构造函数中抛出异常
建议115:使用Throwable获得栈信息
建议116:异常只为异常服务
建议117:多使用异常,把性能问题放一边
建议110:提倡异常封装
Java语言的异常处理机制可以确保程序的健壮性,提高系统的可用率,但是Java API提供的异常都是比较低级别的,只有开发人员才能看的懂。而对于终端用户来说,这些异常无异于天书,那该怎么办呢?这就需要我们对异常进行封装。
异常封装有三方面的有点:
1、提高系统的友好性
2、提高系统的可维护性
正确的做法是对异常进行分类处理,并进行封装输出,代码如下:
public void doStuff4(){
try{
//doSomething
}catch(FileNotFoundException e){
log.info("文件未找到,使用默认配置文件....");
e.printStackTrace();
}catch(SecurityException e1){
log.info(" 无权访问,可能原因是......");
e1.printStackTrace();
}
}如此包装后,维护人员看到这样的异常就有了初步的判断,或者检查配置,或者初始化环境,不需要直接到代码层级去分析了。
3、解决Java异常机制自身的缺陷
Java中的异常一次只能抛出一次,比如doStuff方法中有两个逻辑代码片段,如果在第一个逻辑片段中抛出异常,则第二个逻辑片段就不再执行了,也就无法抛出第二个异常了,现在的问题是如何才能一次抛出两个或更多的异常呢?
其实,使用自行封装的异常可以解决该问题,代码如下:
class MyException extends Exception {
// 容纳所有的异常
private List<Throwable> causes = new ArrayList<Throwable>();
// 构造函数,传递一个异常列表
public MyException(List<? extends Throwable> _causes) {
causes.addAll(_causes);
}
// 读取所有的异常
public List<Throwable> getExceptions() {
return causes;
}
}MyException异常只是一个异常容器,可以容纳多个异常,但它本身并不代表任何异常含义,它所解决的是一次抛出多个异常的问题,具体调用如下:
public void doStuff() throws MyException {
List<Throwable> list = new ArrayList<Throwable>();
// 第一个逻辑片段
try {
// Do Something
} catch (Exception e) {
list.add(e);
}
// 第二个逻辑片段
try {
// Do Something
} catch (Exception e) {
list.add(e);
}
// 检查是否有必要抛出异常
if (list.size() > 0) {
throw new MyException(list);
}
}这样一来,DoStuff方法的调用者就可以一次获得多个异常了,也能够为用户提供完整的例外情况说明。可能有人会问:这种情况会出现吗?怎么回要求一个方法抛出多个异常呢?
绝对有可能出现,例如Web界面注册时,展现层依次把User对象传递到逻辑层,Register方法需要对各个Field进行校验并注册,例如用户名不能重复,密码必须符合密码策略等,不要出现用户第一次提交时系统显示" 用户名重复 ",在用户修改用户名再次提交后,系统又提示" 密码长度小于6位 " 的情况,这种操作模式下的用户体验非常糟糕,最好的解决办法就是异常封装,建立异常容器,一次性地对User对象进行校验,然后返回所有的异常。
建议111:采用异常链传递异常
正确的做法是先封装再传递,步骤如下:
比如我们的JavaEE项目一般都有三层结构:持久层,逻辑层,展现层,持久层负责与数据库交互,逻辑层负责业务逻辑的实现,展现层负责UI数据库的处理。
1、把FIleNotFoundException封装为MyException。
2、抛出到逻辑层,逻辑层根据异常代码(或者自定义的异常类型)确定后续处理逻辑,然后抛出到展现层。
3、展现层自行决定要展现什么,如果是管理员则可以展现低层级的异常,如果是普通用户则展示封装后的异常。
在IOException的构造函数中,上一个层级的异常可以通过异常链进行传递,链中传递异常的代码如下所示:
try{
//doSomething
}catch(Exception e){
throw new IOException(e);
}捕捉到Exception异常,然后将其转化为IOException异常并抛出(此方法叫异常转译),调用者获得该异常后再调用getCause方法即可获得Exception的异常信息。
综上所述,异常需要封装和传递,我们在开发时不要“吞噬”异常,也不要赤裸裸的抛出异常,封装后再抛出,或者通过异常链传递,可以达到系统更健壮,更友好的目的。
建议112:可查异常尽可能转化为不可查异常
可查异常(Checked Exception)是正常逻辑的一种补偿手段,特别是对可靠性要求比较高的系统来说,在某些条件下必须抛出可查异常以便由程序进行补偿处理,也就是说可查异常有存在的理由,那为什么要把可查异常转化为非=不可查异常呢?可查异常确实有不足的地方:
1、可查异常使接口声明脆弱
我们要尽量多使用接口编程,可以提高代码的扩展性、稳定性,但是涉及异常问题就不一样了,例如系统初期是一个接口是这样设计的:
interface User{
//修改用户密码,抛出安全异常
public void changePassword() throws MySecurityException;
}可能有多个实现者,也可能抛出不同的异常。
这里会产生两个问题:① 异常时主逻辑的补充逻辑,修改一个补充逻辑,就会导致主逻辑也被修改,也就会出现实现类“逆影响”接口的情景,我们知道实现类是不稳定的,而接口是稳定的,一旦定义异常,则增加了接口的不稳定性,这是面向对象设计的严重亵渎;② 实现的变更最终会影响到调用者,破坏了封装性,这也是迪米特法则锁不能容忍的。
迪米特法则,俗称最少知识法则,就是说,一个对象应当对其它对象有尽可能少的了解,尽量降低类与类之间的耦合度。
迪米特法则的初衷是降低类之间的耦合,由于每个类都减少了不必要的依赖,因此的确可以降低耦合关系。但是凡事都要有度,虽然可以避免与非直接的类通信,但是要通信,必然会通过一个“中介”来发生联系,过分的使用迪米特原则,会产生大量这样的中介和传递类,导致系统的复杂度变大。所以在采用迪米特原则的时间,要反复权衡,既做到结构清晰,又要高内聚低耦合。
在将迪米特法则运用到系统的设计中时,应注意的几点:
① 在类的划分上,应该创建弱耦合的类;
② 在类的结构设计上,每个类都应该尽量降低类的访问权限、降低成员的访问权限;
③ 在类的设计上,只要有可能,一个类应当设计成不变类;
④ 一个对象在对其它对象的引用应当降低到最低。
⑤ 谨慎使用序列化功能;
⑥ 不要暴露类成员,而应该提供相应的访问器。
2、可查异常使代码的可读性降低
一个方法增加了可查异常,则必须有一个调用者对异常进行处理。
用try...catch捕捉异常,代码膨胀很多,可读性也就降低了,特别是多个异常需要捕捉的时候,而且可能在catch中再次抛出异常,这大大降低了代码的可读性。
3、可查异常增加了开发工作量
我们知道异常需要封装和传递,只有封装才能让异常更容易理解,上层模块才能更好的处理,可这会导致低层级的异常没完没了的封装,无端加重了开发的工作量。
可查异常有这么多的缺点,有什么好的方法可以避免或减少这些缺点呢?就是将可查异常转化为不可查异常,但是也不能把所有的异常转化为不可查异常,有很多的未知不确定性。
我们可以在实现类中根据不同情况抛出不同的异常,简化了开发工作,提高了代码的可读性。
那什么样的能转化,什么样的不能转化呢?
当可查异常威胁到系统额安全性、稳定性、可靠性、正确性,则必须处理,不能转化为不可查异常,其它情况即可转化为不可查异常。
建议113:不要在finally中处理返回值
1、覆盖了try代码块中的return返回值
public static int doStuff() {
int a = 1;
try {
return a;
} catch (Exception e) {
} finally {
// 重新修改一下返回值
a = -1;
}
return 0;
}该方法的返回值永远是1,不会是-1或0(为什么不会执行到" return 0 " 呢?原因是finally执行完毕后该方法已经有返回值了,后续代码就不会再执行了)
public static Person doStuffw() {
Person person = new Person();
person.setName("张三");
try {
return person;
} catch (Exception e) {
} finally {
// 重新修改一下值
person.setName("李四");
}
person.setName("王五");
return person;
}此方法的返回值永远都是name为李四的Person对象,原因是Person是一个引用对象,在try代码块中的返回值是Person对象的地址,finally中再修改那当然会是李四了。
上面的两个例子可以好好的琢磨琢磨!
2、屏蔽异常
public static void doSomeThing(){
try{
//正常抛出异常
throw new RuntimeException();
}finally{
//告诉JVM:该方法正常返回
return;
}
}
public static void main(String[] args) {
try {
doSomeThing();
} catch (RuntimeException e) {
System.out.println("这里是永远不会到达的");
}
}上面finally代码块中的return已经告诉JVM:doSomething方法正常执行结束,没有异常,所以main方法就不可能获得任何异常信息了。
这样的代码会使可读性大大降低,读者很难理解作者的意图,增加了修改的难度。
与return语句相似,System.exit(0)或RunTime.getRunTime().exit(0)出现在异常代码块中也会产生非常多的错误假象,增加代码的复杂性,大家有兴趣可以自行研究一下。
建议114:不要在构造函数中抛出异常
1、构造函数中抛出错误是程序猿无法处理的
2、构造函数不应该抛出不可查异常
class Person {
public Person(int _age) {
// 不满18岁的用户对象不能建立
if (_age < 18) {
throw new RuntimeException("年龄必须大于18岁.");
}
}
public void doSomething() {
System.out.println("doSomething......");
}
}public static void main(String[] args) {
Person p = new Person(17);
p.doSomething();
/*其它的业务逻辑*/
}game over了!
3、构造函数中尽可能不要抛出可查异常
① 导致子类膨胀
② 违背了里氏替换原则:“里氏替换原则”是说父类能出现的地方子类就可以出现,而且将父类替换为子类也不会产生任何异常。
//父类
class Base {
// 父类抛出IOException
public Base() throws IOException {
throw new IOException();
}
}
//子类
class Sub extends Base {
// 子类抛出Exception异常
public Sub() throws Exception {
}
}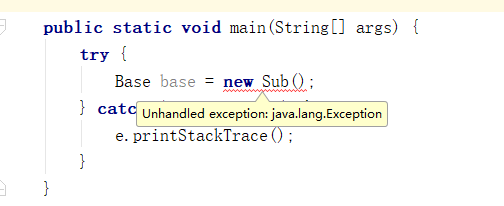
Sub的构造函数抛出了Exception异常,它比父类的构造函数抛出更多的异常范围要宽,必须增加新的catch块才能解决。
在构造函数中抛出受检异常会违背里氏替换原则原则,使我们的程序缺乏灵活性。
③ 子类构造函数扩展受限:子类存在的原因就是期望实现扩展父类的逻辑,但父类构造函数抛出异常却会让子类构造函数的灵活性大大降低,例如我们期望这样的构造函数。
package OSChina.Throwable;
import java.io.IOException;
public class Base {
// 父类抛出IOException
public Base() throws IOException {
throw new IOException();
}
}
这就尴尬了!
受检异常尽量不抛出,能用曲线的方式实现就用曲线方式实现!
建议115:使用Throwable获得栈信息
AOP编程可以很轻松的控制一个方法调用哪些类,也能够控制哪些方法允许被调用,一般来说切面编程,只能控制到方法级别,不能实现代码级别低的植入(Weave)。
使用Throwable获得栈信息,然后鉴别调用者并分别输出,代码如下:
package OSChina.Throwable;
public class Foo {
public static boolean method(){
// 取得当前栈信息
StackTraceElement[] ste = new Throwable().getStackTrace();
//检查是否是methodA方法调用
for(StackTraceElement st:ste){
if(st.getMethodName().equals("methodA")){
return true;
}
}
return false;
}
}
package OSChina.Throwable;
public class Invoker {
//该方法打印出true
public static void methodA(){
System.out.println("methodA(),"+Foo.method());
}
//该方法打印出false
public static void methodB(){
System.out.println("methodB(),"+Foo.method());
}
public static void main(String[] args) {
methodA();
methodB();
}
}
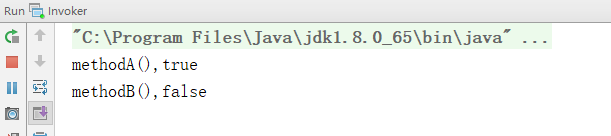
注意看Invoker类,两个方法methodA和methodB都调用了Foo的method方法,都是无参调用,返回值却不同,这是我们的Throwable类发挥效能了。JVM在创建一本Throwable类及其子类时会把当前线程的栈信息记录下来,以便在输出异常时准确定位异常原因,我们来看Throwable源代码。
public class Throwable implements Serializable {
private static final StackTraceElement[] UNASSIGNED_STACK = new StackTraceElement[0];
//出现异常记录的栈帧
private StackTraceElement[] stackTrace = UNASSIGNED_STACK;
//默认构造函数
public Throwable() {
//记录栈帧
fillInStackTrace();
}
//本地方法,抓取执行时的栈信息
private native Throwable fillInStackTrace(int dummy);
public synchronized Throwable fillInStackTrace() {
if (stackTrace != null || backtrace != null /* Out of protocol state */) {
fillInStackTrace(0);
stackTrace = UNASSIGNED_STACK;
}
return this;
}
}在出现异常时(或主动声明一个Throwable对象时),JVM会通过fillInStackTrace方法记录下栈帧信息,然后生成一个Throwable对象,这样我们就可以知道类间的调用顺序,方法名称及当前行号等了。
我们虽然可以根据调用者的不同产生不同的逻辑,但这仅局限在对此方法的广泛认知上,更多的时候我们使用method方法的变形体,代码如下:
class Foo {
public static boolean method() {
// 取得当前栈信息
StackTraceElement[] sts = new Throwable().getStackTrace();
// 检查是否是methodA方法调用
for (StackTraceElement st : sts) {
if (st.getMethodName().equals("methodA")) {
return true;
}
}
throw new RuntimeException("除了methodA方法外,该方法不允许其它方法调用");
}
}只是把“return false” 替换成了一个运行期异常,除了methodA方法外,其它方法调用都会产生异常,该方法常用作离线注册码校验,让破解者视图暴力破解时,由于执行者不是期望的值,因此会返回一个经过包装和混淆的异常信息,大大增加了破解难度。

建议116:异常只为异常服务
异常只为异常服务,这是何解?难道异常还能为其它服务不成?确实能,异常原本是正常逻辑的一个补充,但是有时候会被当做主逻辑使用,看如下代码:
//判断一个枚举是否包含String枚举项
public static <T extends Enum<T>> boolean Contain(Class<T> clz,String name){
boolean result = false;
try{
Enum.valueOf(clz, name);
result = true;
}catch(RuntimeException e){
//只要是抛出异常,则认为不包含
}
return result;
}判断一个枚举是否包含指定的枚举项,这里会根据valueOf方法是否抛出异常来进行判断,如果抛出异常(一般是IllegalArgumentException异常),则认为是不包含,若不抛出异常则可以认为包含该枚举项,看上去这段代码很正常,但是其中有是哪个错误:
1、异常判断降低了系统的性能
2、降低了代码的可读性,只有详细了解valueOf方法的人才能读懂这样的代码,因为valueOf会跑出一个不可查异常。
3、隐藏了运行期可能产生的错误,catch到异常,但没有做任何处理。
// 判断一个枚举是否包含String枚举项
public static <T extends Enum<T>> boolean Contain(Class<T> clz, String name) {
// 遍历枚举项
for (T t : clz.getEnumConstants()) {
// 枚举项名称是否相等
if (t.name().equals(name)) {
return true;
}
}
return false;
}常只能用在非正常的情况下,不能成为正常情况下的主逻辑,也就是说,异常是是主逻辑的辅助场景,不能喧宾夺主。而且,异常虽然是描述例外事件的,但能避免则避免之,除非是确实无法避免的异常,例如:
public static void main(String[] args) {
File file = new File("a.txt");
try {
FileInputStream fis = new FileInputStream(file);
// 其它业务处理
} catch (FileNotFoundException e) {
e.printStackTrace();
// 异常处理
}
}这样一段代码经常在我们的项目中出现,但经常写并不代表不可优化,这里的异常类FileNotFoundException完全可以在它诞生前就消除掉:先判断文件是否存在,然后再生成FileInputStream对象,这也是项目中常见的代码:
public static void main(String[] args) {
File file = new File("a.txt");
// 经常出现的异常,可以先做判断
if (file.exists() && !file.isDirectory()) {
try {
FileInputStream fis = new FileInputStream(file);
// 其它业务处理
} catch (FileNotFoundException e) {
e.printStackTrace();
// 异常处理
}
}
}虽然增加了if判断语句,增加了代码量,但是却减少了FileNotFoundException异常出现的几率,提高了程序的性能和稳定性。
建议117:多使用异常,把性能问题放一边
我们知道异常是主逻辑的例外逻辑,举个简单的例子来说,比如我在马路上走(这是主逻辑),突然开过一辆车,我要避让(这是受检异常,必须处理),继续走着,突然一架飞机从我头顶飞过(非受检异常),我们可以选在继续行走(不捕捉),也可以选择指责其噪音污染(捕捉,主逻辑的补充处理),再继续走着,突然一颗流星砸下来,这没有选择,属于错误,不能做任何处理。
使用异常还有很多优点,可以让正常代码和异常代码分离、能快速查找问题(栈信息快照)等,但是异常有一个缺点:性能比较慢。
Java的异常机制缺失比较慢,这个“比较慢”是相对于String、Integer等对象而言,单单从创建对象来说,new一个IOException会比String慢5倍,这从异常的处理机制上可以解释:
因为new异常要执行fillInStackTrace方法,要记录当前栈的快照,而String类则是直接申请一个内存创建对象,异常类慢半拍再说难免。
而且,异常类时不能缓存的。
难道异常的性能问题就没有任何可以提高的办法了?确实没有,但是我们不能因为性能问题而放弃使用异常,而且经过测试,在JDK1.6下,一个异常对象的创建时间只需1.4毫秒左右(注意是毫秒,通常一个交易是在100毫秒左右),难道我们的系统连如此微小的性能消耗都不予许吗?
注意:性能问题不是拒绝异常的借口。














 2103
2103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









