






参考
https://blog.csdn.net/stanwuc/article/details/81509083
https://www.cnblogs.com/javabg/p/7258550.html
https://blog.csdn.net/yinbingqiu/article/details/60965080
https://www.imooc.com/article/71730?block_id=tuijian_wz //源码解析
https://blog.csdn.net/xuefeng0707/article/details/40797085 //扩容死锁
Java集合家族图解
https://img-blog.csdn.net/20160124221843905
整体特征
| 接口 | 子接口 | 是否有序 | 是否允许元素重复 |
|---|---|---|---|
| Set 无序不可重复 | AbstractSet | 否 | 否 |
| HashSet(基于HashMap) | 否 | 否 | |
| TreeSet | 是(用二叉排序树) | 否 | |
| List 无序可重复 | ArrayList | 有 | 是 |
| LinkedList | 有 | 是 | |
| Vector | 有 | 是 | |
| Map | AbstractMap | 否 | 使用key-value来映射和存储数据,key必须唯一,value可以重复 |
| HashMap | 否 | ||
| TreeMap | 是(用二叉排序树) | 使用key-value来映射和存储数据,key必须唯一,value可以重复 |
最常用集合
常用集合特征
| 底层实现 | 优缺点 | 应用场景 | |
|---|---|---|---|
| Vector | Object[]数组结构 | 增删改查效率都低,线程安全 | 多线程环境。几乎不用了 |
| ArrayList | Object[]数组结构,通过拷贝扩容 | 查询效率高,增删效率低,线程不安全 | 单线程环境,查询多,修改少。在单线程环境几乎替代了vector |
| LinkedList | 双链表结构 | 查询效率低,增删效率高,线程不安全 | 单线程环境,修改多,查询少 |
| Hashtable | hash数组+链表 | 不允许key或value为null,效率低,线程安全 几乎所有方法上都加了synchronized,导致性能低 | 多线程环境。但JDK5已经用ConcurrentHashMap替代它了 |
| HashMap | hash数组+链表+红黑树(链表长度>8时) | 允许key或value为null,效率高,线程不安全 | 多用于单线程。多线程下也可以用Collections.synchronizeMap(hashMap), 采用的是对象锁机制,但效率不及 ConcurrentHashMap |
| HashSet | 基于HashMap实现。以下为扩容代码 可见默认负载因子0.75 | 查找及增删速度都快,元素无序,不可重复,线程不安全 | 要求能快速增删改查元素,要求元素不可重复,且不要求元素有序,并对线程安全无要求时使用 |
关于HashMap面试问题
1. HashMap的内部结构
首先是HashMap的内部结构,借用一张图(https://blog.csdn.net/stanwuc/article/details/81509083)
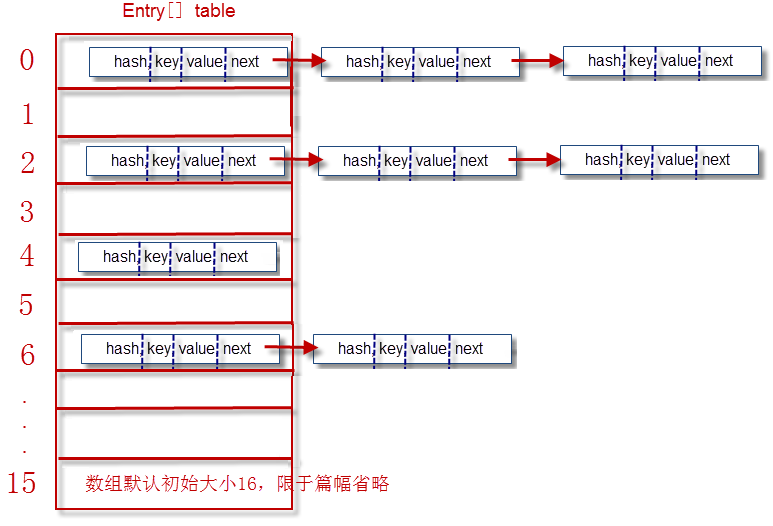
这张图有点老,JDK8中的成员变量table的类型叫Node,但本质上依然是实现了Map.Entity接口
图中的Entity(即Node)类型结构如下,注意其中的成员key是的类型时一个泛型,这个设计很有用,后面说。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next);
public final K getKey() ;
public final V getValue();
public final String toString();
public final int hashCode();
public final V setValue(V newValue);
public final boolean equals(Object o);
}
因此一句话概括HashMap的结构就是,HashMap底层是由链表节点组成的数组构成的。
2.工作过程
存数据
当调用put(K key, V value)时,HashMap做了以下工作
- 调用Object的hashCode()方法获取key的hash值
- 若 table[ f(hash) ] 不存在,把当前元素存入这个位置,其中是以 f(hash) 作为数组下标,并生成一个 Entity 节点 (即 new Node(hash,key,value,next))对象)作为元素值。
- 若 table[ f(hash) ] 已经存在(即hash冲突),冲突元素用单链表存储,用hash+key(key为对象时用equals(key)比较)判断元素是否已存在单链表中,由配置决定是否替换重复元素。不重复则添加到链表尾部。
- 对于 hash冲突,如果单链表长度超过8时,将切换为红黑树存储新元素,这是JDK8中关于hashmap的优化
取数据
当调用get(Object key)时,HashMap做了以下工作
- 调用Object的hashCode()方法获取key的hash值
- 若table[ f(hash) ] 不存在,则返回null
- 若table[ f(hash) ] 存在,则看比较第一个节点,用hash+key(key为对象时用equals(key)比较),相等,则返回第一个节点
- 若第3点钟的第一个节点不是要查找的节点,则遍历链表进行查找,依然是用hash+key作为查找条件,若查找不到则返回null
扩容
相关配置参数
DEFAULT_INITIAL_CAPACITY = 16 //hashmap的容量缺省配置,必须为2的幂次
DEFAULT_LOAD_FACTOR = 0.75 // 默认负载因子,当hashmap中元素个数超过 DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR 时就要扩容
TREEIFY_THRESHOLD = 8 //hash冲突时,默认链表最大长度,超过此长度,jdk8中会用红黑树重新存储链表,优化性能
MIN_TREEIFY_CAPACITY = 64 //DJK8中规定在解决hash冲突时,若已达到链表长度超过8的条件,在转红黑树之前,会先判断table的size是否小于64,是就扩容。
扩容时机
研究JDK8源码发现HashMap至少有四种情况会发生扩容,或者叫初始化,总之都是调用了resize()方法
第一,对于空table,在put第一个元素时,将会初始化(扩容)table的大小
第二,table非空时,每插入一个元素,都统计size是否超过阈值(hash冲突时size可能不变),超过则扩容。(阈值= threshold * loadFactor)
第三,发生hash冲突时,新元素将超如hash冲突所在的链表末尾,插入后若链表长度已经超过8,JDK8中要将链表转为红黑树,转之前会先看table的size()是不是小于64,小于64就扩一次容。
扩容死锁
多线程环境下的竞性条件,导致死锁
JDK1.7才会导致死锁,主要原因是在扩容时hash冲突的节点链表形成环,从而get的是死锁
比较复杂,参考 https://blog.csdn.net/xuefeng0707/article/details/40797085
“当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小,如果条件竞争发生了,那么就死循环了”。不过这个问题在JDK8中已经不会出现了。
HashMap内部hashCode(), equals() 的功能
put一个元素进hashmap时,首先会调用key.hashCode()计算key的hash值,并有可能用这个hash值作为数组下标将元素保存起来。
而equals()则是在查找hash冲突时建立的链表中的元素时使用,需要用 hash(key)+equals(key)去批量链表中的元素
为什么重写了类的equals()方法,往往要同时重写hashCode()方法?
这个问题主要是针对当使用对象做为hashmap的key的时候,
首先要了解hashmap的get()机制,首先计算key.hashCode(),从而找到table数组下标(有可能是哈希冲突链表头结点),
并用key.equals(k)来对比key是否相等,相等才返回,否则返回null。
而在Java中,equals()和hashCode()默认都是用变量/对象的地址来计算的,
意味着同一个对象可能序列化一下结果hashCode()就变了,这在hashMap机制中就会出问题,原来存入的元素,可能就get不出来了,
因此需要重写equals()和hashCode()方法,使得逻辑上相等的对象,equals()为true,并且每次hashCode()都相同。
比如下面这个例子:
Student s1 = new Student("young",20);
Student s2 = new Student("young",20);
HashMap<Student,Student> map = new HashMap<>();
map.put(s1,s1);
System.out.println(map.get(s2));若不重写Student类的equals()和hashCode()方法,则get返回null。故要重写一下,像下面这样:
@Override
public boolean equals(Object obj)
{
if(obj instanceof Student) {
return ((Student) obj).age == this.age
&& ((Student) obj).name == this.name;
}
return false;
}
@Override
public int hashCode() {
return this.age + this.name.hashCode();
}至于怎样重写,由业务决定,原则是让逻辑上本应该相等的对象,equals()要返回true,hashCode()要次次返回相同的值,以保证hashMap还认得这个对象是之前存储过的对象。
基于以上原因,推荐用不可变类对象(例如String,因为有finnal修饰)作为key,简单,安全















 1776
1776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









