







1.ROWID定义
ROWID:数据库中行的全局唯一地址
对于数据中的每一行,rowid伪列返回行的地址。rowid值主要包含以下信息:
- 对象的数据对象编号
- 该行所在的数据文件中的数据块
- 该行中数据块的位置(第一行是0)
- 数据行所在的数据文件(第一个文件是1)。该文件编号是相对于表空间。
通常来说,一个rowid值唯一标识数据中的一行。然而,存储在同一聚簇中不同的表可以有相同的rowid。
2.扩展ROWID
从Oracle 8i开始使用扩展rowid标识行物理地址
扩展rowid使用base64编码行的物理地址,编码字符包含 A-Z, a-z, 0-9, +, 和 /。
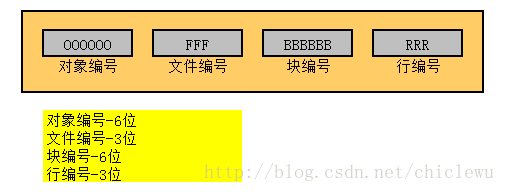
扩展rowid由四部分组成:OOOOOOOFFFBBBBBBRRR:
其中:
- OOOOOO:数据对象编号(6位显示)
- FFF:相关数据文件编号(3位显示)
- BBBBBB:数据块编号(6位显示)
- RRR:数据块中行编号(3位显示)
3.受限ROWID
为了兼容Oracle8i以前的应用使用受限rowid标识行物理地址
受限rowid使用二进制标识行的物理地址,当使用SQL*Plus查询时,二进制被转换为VARCHAR2/十六进制显示。
受限rowid有三部分组成:BBBBBB.RRRR.FFFF(block.row.file):
- BBBBBB:数据库块编号(6位显示)
- RRRR:数据块找中行编号(4位显示)
- FFFF:数据文件编号(4位显示)

4.ROWID内部存储
对于内部ROWID存储结构,扩展ROWID在大多数平台上采用10个字节存储,受限ROWID6个字节存储。具体规则如下:
- 数据对象编号-----32bit
- 数据文件编号------10bit
- 数据块编号--------22bit
- 数据块中行编号----16bit
Oracle 8i以前,rowid占用6个字节空间,分别是22bit的block#,16bit的row#,10bit的file#。
从Oracle 8i开始,rowid占用10个字节空间,分别是32bit的object#,10bit的rfile#,22bit的block#,16bit的row#。新增了32bit的object#。受限rowid的file#t基于整个数据库,扩展rowid的rfile#基于表空间。
5.base 64编码
| 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 |
| 0 | A | 17 | R | 34 | i | 51 | z |
| 1 | B | 18 | S | 35 | l | 52 | 0 |
| 2 | C | 19 | T | 36 | k | 53 | 1 |
| 3 | D | 20 | U | 37 | l | 54 | 2 |
| 4 | E | 21 | V | 38 | m | 55 | 3 |
| 5 | F | 22 | W | 39 | n | 56 | 4 |
| 6 | G | 23 | X | 40 | o | 57 | 5 |
| 7 | H | 24 | Y | 41 | p | 58 | 6 |
| 8 | I | 25 | Z | 42 | q | 59 | 7 |
| 9 | J | 26 | a | 43 | r | 60 | 8 |
| 10 | K | 27 | b | 44 | s | 61 | 9 |
| 11 | L | 28 | c | 45 | t | 62 | + |
| 12 | M | 29 | d | 46 | u | 63 | / |
| 13 | N | 30 | e | 47 | v |
|
|
| 14 | O | 31 | f | 48 | w |
|
|
| 15 | P | 32 | g | 49 | x |
|
|
| 16 | Q | 33 | h | 50 | y |
|
|
6.Example
创建my_rowid表,通过对my_rowid表的操作来解读rowid。
SQL> create table my_rowid(id number,name varchar2(50));
Table created
--插入两行数据
SQL> insert into my_rowid values(1,'whz');
1 row inserted
SQL> insert into my_rowid values(2,'chiclewu');
1 row inserted
6.1查看my_rowid表中行的ROWID
SQL> select rowid,id,name from my_rowid;
ROWID ID NAME
------------------ ---------- --------------------------------------------------
AAATLnAAFAAAAD9AAA 1 whz
AAATLnAAFAAAAD9AAB 2 chiclewu
6.2 ROWID组成格式
SQL> select rowid,
2 substr(rowid, 1, 6) "#objct",
3 substr(rowid, 7, 3) "#file",
4 substr(rowid, 10, 6) "#block",
5 substr(rowid, 16, 3) "#row"
6 from my_rowid;
ROWID #objct #file #block #row
------------------ ------------ ------ ------------ ------
AAATLnAAFAAAAD9AAA AAATLn AAF AAAAD9 AAA
AAATLnAAFAAAAD9AAB AAATLn AAF AAAAD9 AAB
将base64编码转换为十进制:
#object:AAATLn -----> 0 0 0 19 11 39(显示字符对应的索引) ----->0*64^5+0*64^4+0*64^3+ 19*64^2+11*64^1+39*64^1 =78567
以此类推,得出:
#file:AAF----------> 5
#block:AAAAD9------> 253
#row:AAA-----------> 0
使用dbms_rowid包获取my_rowid表的信息:
SQL> select rowid,
2 dbms_rowid.rowid_object(rowid) "#objct",
3 dbms_rowid.rowid_relative_fno(rowid) "#file",
4 dbms_rowid.rowid_block_number(rowid) "#block",
5 dbms_rowid.rowid_row_number(rowid) "#row"
6 from my_rowid;
ROWID #objct #file #block #row
------------------ ---------- ---------- ---------- ----------
AAATLnAAFAAAAD9AAA 78567 5 253 0
AAATLnAAFAAAAD9AAB 78567 5 253 1
结论:与base64直接转换的一样,说明#block显示6为,#rfile显示3位,#block显示6位,#row显示3位是对的。
6.3 DUMP函数转换ROWID
为了验证rowid的存储空间为10字节,其中32bit的object#,10bit的rfile#,22bit的block#,16bit的row#。我们需要使用dump函数。
SQL> select rowid,dump(rowid,16) from my_rowid;
ROWID DUMP(ROWID,16)
------------------ --------------------------------------------------------------------------------
AAATLnAAFAAAAD9AAA Typ=69 Len=10: 0,1,32,e7,1,40,0,fd,0,0
AAATLnAAFAAAAD9AAB Typ=69 Len=10: 0,1,32,e7,1,40,0,fd,0,1
其中,len=10表示是个字节。
AAATLnAAFAAAAD9AAA-->0,1,32,e7,1,40,0,fd,0,0
将十六进制转换为二进制:
0----->00000000
1----->00000001
32---->00110010
e7---->11100111
1----->00000001
40--->01000000
0---->00000000
df--->11011111
0---->0000000
0---->0000000
组合为80bit的rowid:
rowid=00000000000000010011001011100111 0000000101 0000000000000011111101 00000000000000=78567 925 253 0
结论:dump函数转换rowid后,按照32bit的object#,10bit的rfile#,22bit的block#,16bit的row#划分后结果与dbms_rowid包和base64编码的值相等,说明我测试的平台上rowid是按照10个字节存储的,并且每个内部划分也是正确的。















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









