






往昔
最初团队里使用Angularjs进行开发,刚开始还好,到了项目后期越发感觉Angularjs太重了,以至于后来重构项目时,毅然放弃Angularjs,投入了Vue的怀抱。除了组建团队时,是我搭建了基于Angularjs的前端开发框架,之后都是由前端小组开发。前段时间,由于公司层面的原因,整个团队解散,不得已我又要写前端程序了。
虽然前期Angularjs的开发框架是我搭建的,但对前端来说我也是半路出家了。那个时候也不知道模块开发,更分不清commonJS、AMD、CMD,知道有个requirejs,就研究requirejs,研究了几天突然冒出一个叫grunt的构建工具,于是又研究grunt,同样研究了几天又窜出来个叫gulp的东西,丢了grunt又研究起gulp来,这真有点像小时候听的猴子摘桃的故事,看见好的就丢掉了之前的,最后什么都没得到。gulp搞的差不多了,不知又从哪里看到了一个叫webpack的东西,我的天哪,当时的感觉就是前端的东西太多东西了,那个时候是2015年下。
当下
再一次写前端程序已经到了2017年了,除了维护之前Angularjs的代码,还有新的项目,我选择了Vue 2.0。
学习一门新的技术是需要花费不少代价的,时间不说,动力也是不可或缺的。时间我有,动力也足,那就是半个月做完一个小的管理后台,API已经在上个周加班加点搞定了。半个月要学一门新的技术,还要把功能做完,自我感觉应该是没问题的,毕竟Vue真的是一个非常简单的框架。
我简单列了一个简单的学习计划,不用太详细,因为计划总是赶不上变化,事实也确实如此,最重要的还是动手、实践、执行。
-
第1天看完Vue的官方文档,大致了解一下Vue都有哪些功能,做到心中有数;
-
第2天看完vue-router和vuex,了解路由和状态管理,借助Shopping Cart的例子快速理解,state、getters、actions、mutations、commit、dispatch、mapGetters、mapActions;
-
第3天花了一点时间看axios,因为官方在Vue2.0中推荐axios;然后开始搭建项目结构,选择基于webpack的构建模板(不要问我怎么知道的,那么多优秀的开源demo);
-
第4天做了登录的功能,将vue付诸实践。刚开始写代码比较生疏,只好一边查文档一边写;
-
第5天做登录后的整体布局,结合metronic;写最简单功能的列表时,没找到合适的table插件,决定自己写一个;
-
第6天开始写自己的table插件,起了名字cxlt-vue2-table,放在了github上,前后花了4天,现在还不完善。写table插件的过程比较深入的了解了vue,谷歌了无数次,也无数次了文档;
-
...
-
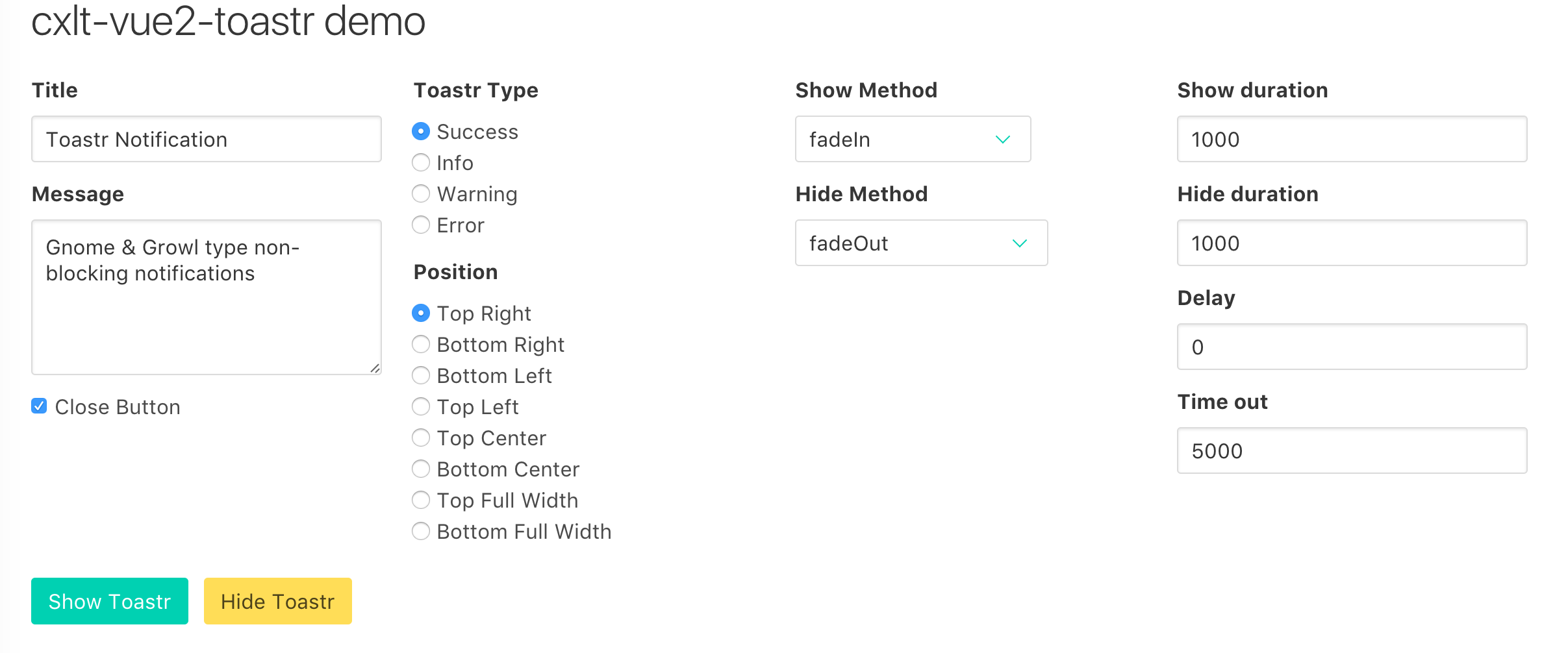
还写了一个自动完成的插件cxlt-vue2-autocomplete和弹出提示cxlt-vue2-toastr的插件
最后按时完成了这个小项目,一只脚也算踏进了vue的大门,争取早日将另一只脚也踏进来。
未来
当下即未来,未来在当下
东西
上文提到的插件我都放在了github上,table和autocomplete还不是太完善,文档也没有写,周日的时候我把toastr的doc和example写了一下,感兴趣的可以前往看一下
项目地址: https://github.com/chengxulvt...
Demo地址: https://chengxulvtu.github.io...
Demo截图















 1365
1365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









