






任何Spark程序的编写都是从SparkContext(或用Java编写时的JavaSparkContext)开始的。SparkContext的初始化需要一个SparkConf对象,后者包含了Spark集群配置的各种参数(比如主节点的URL)。
初始化后,我们便可用SparkContext对象所包含的各种方法来创建和操作分布式数据集和共享变量。Spark shell(在Scala和Python下可以,但不支持Java)能自动完成上述初始化。若要用Scala代码来实现的话,可参照下面的代码:
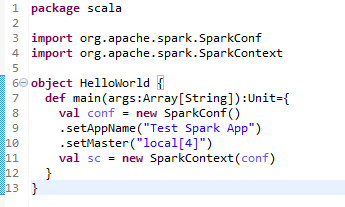
这段代码会创建一个4线程的SparkContext对象,并将其相应的任务命名为Test Spark APP。我们也可通过如下方式调用SparkContext的简单构造函数,以默认的参数值来创建相应的对象。其效果和上述的完全相同:
![]()
注:SparkConf和SparkContext这两个类,在spark2.0以后的版本中,包含在spark-core_2.11-2.0.2.jar包中。















 2245
2245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









