






1. 什么是VBA?
具体含义大家可以看百度百科,我就直接上图了,每个单元格都是调用了VBA的宏计算语言函数,我就简称这个Excel含有macro计算逻辑吧。
2.问题是什么?
大家都知道要比较一个API的准确性,我们需要自己根据方法论去把所有原始数据都推演计算一遍,得到结果。然后在跟开发做的API response做下对比,如果两个结果相同,则表示这个API计算正确。
现在我们PO不让我重写一遍开发的计算逻辑了,规定所有计算相关的逻辑都在Excel里面做好计算模板sheet,然后我将所有原始数据都放到计算模板同一个文件夹下。在含有Marco计算逻辑的那个excel(计算模板sheet)里面完成数据的引用和计算。
然后将API返回的Response也写入到同目录下的一个Excel中(样式跟计算模板计算出来的结果相同),模板里面将比较API response和Excel中的计算结果,然后输出一个如上图一样的一个sheet页(二维矩阵,单元格里的内容是TRUE或者FALSE)。
我要做的就是:将原始数据放到规定名字和格式的Excel中,将最终API的response也放到Excel中,然后打开这个含有macro函数的excel,查看sheet页中是否含有FALSE,如果有,告诉对应的行和列名称并输出。若是没有FALSE,这说明比对通过,API pass。
难点是:
我用Python写函数,现在Python用pandas打开这个含有Macro函数的Excel后,读出的数据永远都是Nan,因为它不能识别那些macro函数。。。所以我无法判断该API是否pass。
3. 手动操作Excel的时候要怎样看到是TRUE或FALSE呢?
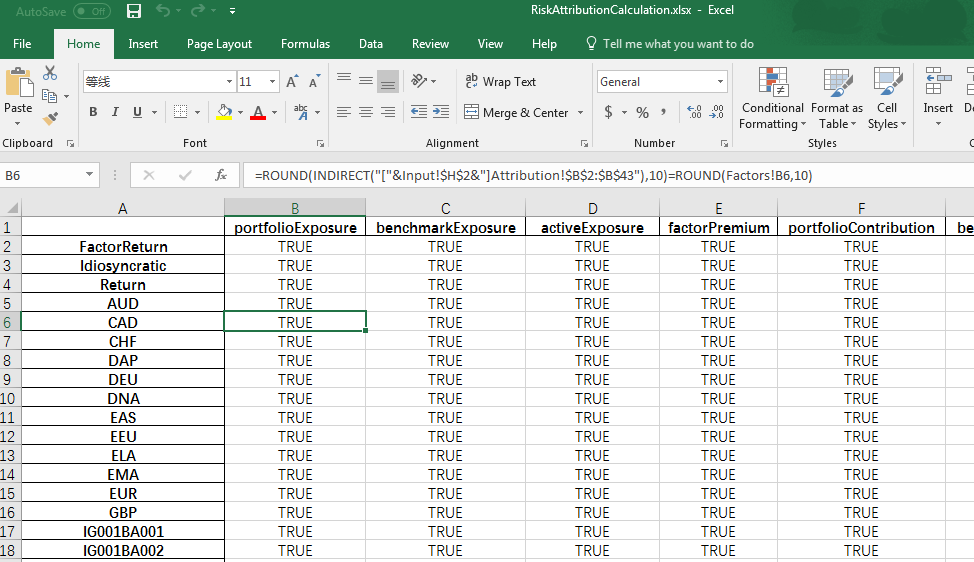
在打开这个有macro函数的Excel之前,我们需要打开所有它引用的其他Excel。然后回到这个Excel的时候,这些宏会自动引用其他excel相应的数据,并得出计算结果。
4. 用Python要怎样实现这一手动逻辑呢?
在Python中调用VBA去控制这些Excel即可。
5. 具体要怎样实现呢?
a. 下载Python扩展包: pywin32 (这个有32和64位之分)
可以直接去下载zip文件,然后安装;
但我建议直接用命令: pip install pywin32
b. 在自己python文件中引用: from win32com import client
from win32com import client
c. 在python中写VBA:
#打开Excel应用,并且依次打开该计算模板Excel依赖的所有excel文件,然后打开最终计算模板excel
xlApp = client.Dispatch('Excel.Application')
# xlApp.visible默认是0,就是不显示所有Excel文件窗口哦
xlApp.visible = 1
# Open original excels in the given absolute path one by one
suite_name = suite_path.split(".")[-1]
file_names = filter(lambda x: x.find("File") > -1, input_params.keys())
for file_name in file_names:
# excel = pd.ExcelFile("OutputExcel/%s/%s" % (suite_name, input_params[file_name]))
xlApp.Workbooks.Open(r"%s\APG_API_RobotFramework\OutputExcel\%s\%s" % (workspace_path, suite_name, input_params[file_name]))
# Open the result excel and check data
xlBook = xlApp.Workbooks.Open("%s\APG_API_RobotFramework\OutputExcel\%s\%s" % (workspace_path, suite_name, RESULT_EXCEL))
xlsheet = xlBook.Worksheets("Result")
# 操作Excel可能会出错,所以需要用到try, finally结构块
try:
# Store calculation result into result_list
rows = xlsheet.UsedRange.Rows.Count
columns = xlsheet.UsedRange.Columns.Count
# 读取做好的比较数据模板sheet页中的数据并放入二维数组中
result_list = []
for row in range(1, rows):
temp_list = []
for column in range(1, columns):
temp_list.append(str(xlsheet.Cells(row, column)))
result_list.insert(row-1, temp_list)
# print result_list
# Get row and column title, then remove titles' values and put left values into new_list
row_title = [x[0] for x in result_list][1:]
column_title = [y for y in result_list[0]][1:]
# print("row title : ", row_title)
# print("column title :", column_title)
new_list = []
for x in result_list[1:]:
new_list.append(x[1:])
# print new_list
# 因为最终要提示用户FALSE单元格对应的行和列名称,所以我用pandas来构造DataFrame,这样效率很高
# Put data into DataFrame then select values which are "FALSE"
df = pd.DataFrame(data=new_list, index=row_title, columns=column_title)
fail_list = []
for index, row in df.iterrows():
if row[0] == "False":
fail_list.extend([index, row[0]])
# 若找到FALSE单元格,则提示具体错误信息,否则打印比较成功的提示
assert fail_list.__len__() == 0, "Failed cells are : "+str(fail_list)
print "Compare successfully !"
finally:
# Don't let the save dialog pop up when close (Since the result excel shouldn't be saved)
xlApp.DisplayAlerts = 0
# xlBook.Save()
xlBook.Close()
xlApp.Workbooks.Close()
# xlApp.visible = 0
xlApp.Quit()
finally中的语句非常关键,相当于open一个文件之后进行读写,最终一定要关闭对应的io流一样!
那个计算模板是不允许改动的,所以在关闭那个xlBook的时候总是提示是否需要保存,在Jenkins上配置这个Project之后,所有相关操作肯定是无法手动干预的。所以我就采取了最直接的方式:
xlApp.DisplayAlerts = 0
就是不弹出所有提示框。
先关闭计算模板Excel,然后关闭该Excel依赖的所有其他Excel。
最后退出Excel应用程序。
(若是最后退出程序以后发现还有一个空白的Excel窗口,这时候可以用 xlApp.visible=0 来隐藏)
所有这些都执行完了以后,这些被操作过的文件就不会被锁住了。(若是被锁住,以后用python读取的时候都会提示IOException哦~~)
因为项目太忙了,所以写的都是流水账,如果大家有什么更好的建议或者疑问,可以给我留言哦,谢谢阅读~~















 4241
4241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









