






在flume1.7之前如果想要监控一个文件新增的内容,我们一般采用的source 为 exec tail ,但是这会有一个弊端,就是当你的服务器宕机重启后,此时数据读取还是从头开始,这显然不是我们想看到的! 在flume1.7没有出来之前我们一般的解决思路为:当读取一条记录后,就把当前的记录的行号记录到一个文件中,宕机重启时,我们可以先从文件中获取到最后一次读取文件的行数,然后继续监控读取下去。保证数据不丢失、不重复。
具体配置文件修改为:
a1.sources.r3.command = tail -n +$(tail -n1 /root/nnn) -F /root/data/web.log | awk 'ARGIND==1{i=$0;next}{i++;if($0~/^tail/){i=0};print $0;print i >> "/root/nnn";fflush("")}' /root/nnn -
其中/root/data/web.log 为监控的文件,/root/nnn为保存读取记录的文件。
而在flume1.7时新增了一个source 的类型为taildir,它可以监控一个目录下的多个文件,并且实现了实时读取记录保存的功能!功能更加强大! 先看看官网的介绍:
-Taildir Source
Note
This source is provided as a preview feature. It does not work on Windows.
Watch the specified files, and tail them in nearly real-time once detected new lines appended to the each files. If the new lines are being written, this source will retry reading them in wait for the completion of the write.
This source is reliable and will not miss data even when the tailing files rotate. It periodically writes the last read position of each files on the given position file in JSON format. If Flume is stopped or down for some reason, it can restart tailing from the position written on the existing position file.
In other use case, this source can also start tailing from the arbitrary position for each files using the given position file. When there is no position file on the specified path, it will start tailing from the first line of each files by default.
Files will be consumed in order of their modification time. File with the oldest modification time will be consumed first.
This source does not rename or delete or do any modifications to the file being tailed. Currently this source does not support tailing binary files. It reads text files line by line.
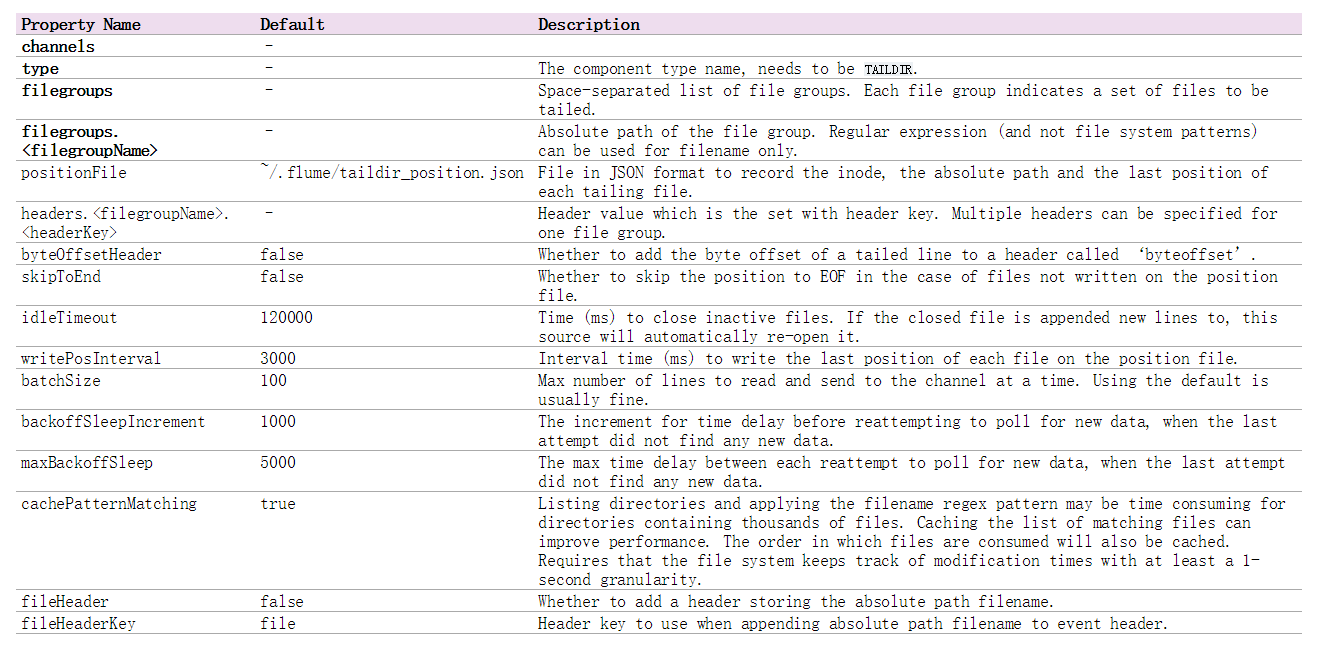
需求:实现flume监控一个目录下的多个文件内容,实时的收集存储到hadoop集群中。
配置案例:
a1.channels = ch1
a1.sources = s1
a1.sinks = hdfs-sink1
#channel
a1.channels.ch1.type = memory
a1.channels.ch1.capacity=100000
a1.channels.ch1.transactionCapacity=50000
#source
a1.sources.s1.channels = ch1
#监控一个目录下的多个文件新增的内容
a1.sources.s1.type = taildir
#通过 json 格式存下每个文件消费的偏移量,避免从头消费
a1.sources.s1.positionFile = /var/local/apache-flume-1.7.0-bin/taildir_position.json
a1.sources.s1.filegroups = f1 f2 f3
a1.sources.s1.filegroups.f1 = /root/data/access.log
a1.sources.s1.filegroups.f2 = /root/data/nginx.log
a1.sources.s1.filegroups.f3 = /root/data/web.log
a1.sources.s1.headers.f1.headerKey = access
a1.sources.s1.headers.f2.headerKey = nginx
a1.sources.s1.headers.f3.headerKey = web
a1.sources.s1.fileHeader = true
##sink
a1.sinks.hdfs-sink1.channel = ch1
a1.sinks.hdfs-sink1.type = hdfs
a1.sinks.hdfs-sink1.hdfs.path =hdfs://master:9000/demo/data
a1.sinks.hdfs-sink1.hdfs.filePrefix = event_data
a1.sinks.hdfs-sink1.hdfs.fileSuffix = .log
a1.sinks.hdfs-sink1.hdfs.rollSize = 10485760
a1.sinks.hdfs-sink1.hdfs.rollInterval =20
a1.sinks.hdfs-sink1.hdfs.rollCount = 0
a1.sinks.hdfs-sink1.hdfs.batchSize = 1500
a1.sinks.hdfs-sink1.hdfs.round = true
a1.sinks.hdfs-sink1.hdfs.roundUnit = minute
a1.sinks.hdfs-sink1.hdfs.threadsPoolSize = 25
a1.sinks.hdfs-sink1.hdfs.useLocalTimeStamp = true
a1.sinks.hdfs-sink1.hdfs.minBlockReplicas = 1
a1.sinks.hdfs-sink1.hdfs.fileType =DataStream
a1.sinks.hdfs-sink1.hdfs.writeFormat = Text
a1.sinks.hdfs-sink1.hdfs.callTimeout = 60000















 3184
3184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









