







本文转载自http://blog.csdn.net/ljianhui/article/details/21666327 谢谢原文作者的辛勤付出。
我们在写程序时,既有程序的逻辑代码,也有在程序中定义的变量等数据,那么当我们的程序进行时,我们的代码和数据究竟是存放在哪里的呢?下面就来总结一下。
其实在程序运行时,由于内存的管理方式是以页为单位的,而且程序使用的地址都是虚拟地址,当程序要使用内存时,操作系统再把虚拟地址映射到真实的物理内存的地址上。所以在程序中,以虚拟地址来看,数据或代码是一块块地存在于内存中的,通常我们称其为一个段。而且代码和数据是分开存放的,即不储存于同于一个段中,而且各种数据也是分开存放在不同的段中的。
下面以一个简单的程序来看一下在Linux下的程序运行空间情况,代码文件名为space.c
#include <unistd.h>
#include <stdio.h>
int main()
{
printf("%d\n", getpid());
while(1);
return 0;
}
这个程序非常简单,输出当前进程的进程号,然后进入一个死循环,这个死循环的目的只是让程序不退出。而在Linux下有一个目录/proc/$(pid),这个目录保存了进程号为pid的进程运行时的所有信息,其中有一个文件maps,它记录了程序执行过程中的内存空间的情况。编译运行上面的代码,其运行结果如图1所示:
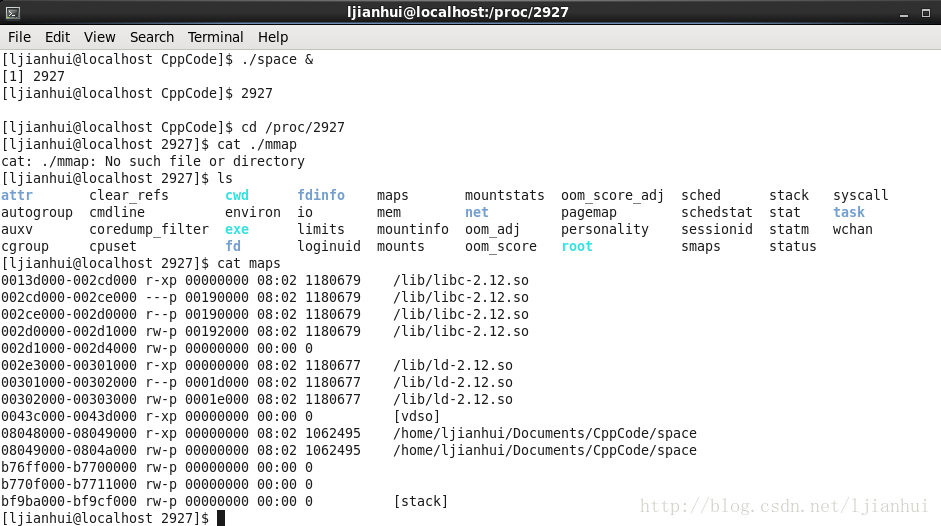
在linux 64位操作系统中
从上面的图中,我们可以看到这样一个简单的程序,在执行时,需要哪些库和哪些空间。上面的图的各列的意思,不一一详述,只对重要的进行说明。
第一列的是一个段的起始地址和结束地址,第二列这个段的权限,第三列段的段内相对偏移量,第六列是这个段所存放的内容所对应的文件。从上图可以看到我们的程序进行首先要加载系统的两个共享库,然后再加载我们写的程序的代码(在linux 64位操作系统中尝试是先加载我们写的程序代码后加载两个共享库,最后是栈)。
对于第二列的权限,r:表示可读,w:表示可写,x:表示可执行,p:表示受保护(即只对本进程有效,不共享),与之相对的是s,意是就是共享。
从上图我们可以非常形象地看到一个程序进行时的内存分布情况。下面我们将会结合上图,进行更加深入的对内存中的数据段的解说。
二、程序运行时内存的各种数据段
1.bss段
该段用来存放没有被初始化或初始化为0的全局变量,因为是全局变量,所以在程序运行的整个生命周期内都存在于内存中。有趣的是这个段中的变量只占用程序运行时的内存空间,而不占用程序文件的储存空间。可以用以下程序来说明这点(通过符号表可以看到未初始化的全局变量没有被存放在任何段,只是一个未定义的“COMMON符号”,这其实是跟不同的语言与不同的编译器实现有关,有些编译器会将全局未初始化变量存放在.bss段,有些则不放,只是预留一个未定义的全局变量符号,等到最终连接成可执行文件的时候再在.bss段分配空间。)
文件名为bss.c


文件名为bss.c
#include <stdio.h>
int bss_data[1024 * 1024];
int main()
{
return 0;
}
这个程序非常简单,定义一个4M的全局变量,然后返回。编译成可执行文件bss,并查看可执行文件的文件属性如图2所示:
从可执行文件的大小4774B可以看出,bss数据段(4M)并不占用程序文件的储存空间,在下面的data段中,我们可以看到data段的数据是占用可执行文件的储存空间的。
在图1中,有文件名且属性为rw-p的内存区间,就是bss段。
2.data段
初始化过的全局变量数据段,该段用来保存初始化了的非0的全局变量,如果全局变量初始化为0,则编译有时会出于优化的考虑,将其放在bss段中。因为也是全局变量,所以在程序运行的整个生命周期内都存在于内存中。与bss段不同的是,data段中的变量既占程序运行时的内存空间,也占程序文件的储存空间。可以用下面的程序来说明,文件名为data.c:
#include <stdio.h>
int data_data[1024 * 1024] = {1};
int main()
{
return 0;
}
这个程序与上面的bss唯一的不同就是全局变量int型数组data_data,其中第0个元素的值初始化为1,其他元素的值初始化成默认的0,而因为数组的地址是连续的,所以只要有一个元素在data段中,则其他的元素也必然在data段中。编
译连接成可执行文件data,并查看可执行文件的文件属性如图3所示:
从可执行文件的大小来看,data段数据(data_data数组的大小,4M)占用程序文件的储存空间。
在图1中,有文件名且属性为rw-p的内存区间,就是data段,它与bss段在内存中是共用一段内存的,不同的是,bss段数据不占用文件,而data段数据占用文件储存空间。
3.rodata段
该段是常量数据段,用于存放常量数据,ro就是Read Only之意。但是注意并不是所有的常量都是放在常量数据段的,其特殊情况如下:
1)有些立即数与指令编译在一起直接放在代码段(text段,下面会讲到)中。
2)对于字符串常量,编译器会去掉重复的常量,让程序的每个字符串常量只有一份。
3)有些系统中rodata段是多个进程共享的,目的是为了提高空间的利用率。
在图1中,有文件名的属性为r--p的内存区间就是rodata段。可见他是受保护的,只能被读取,从而提高程序的稳定性。
4.text段
text段就是代码段,用来存放程序的代码(如函数)和部分整数常量。它与rodata段的主要不同是,text段是可以执行的,而且不被不同的进程共享。
在图1中,有文件名且属性为r-xp的内存区间就是text段。就如我们所知道的那样,代码段是不能被写的。
5.stack段
该段就是栈段,用来保存临时变量和函数参数。程序中的函数调用就是以栈的方式来实现的,通常栈是向下(即向低地址)增长的,当向栈中push一个元素,栈顶指针就会向低地址移动,当从栈中pop一个元素,栈顶指针就会向高地址移动。栈中的数据只在当前函数或下一层函数中有效,当函数返回时,这些数据自动被释放,如果继续对这些数据进行访问,将发生未知的错误。通常我们在程序中定义的不是用malloc系统函数或new出来的变量,都是存放在栈中的。例如,如下函数:
void func()
{
int a = 0;
int *n_ptr = malloc(sizeof(int));
char *c_ptr = new char;
}
整型变量a,整型指针变量n_ptr和char型指针变量c_ptr,都存放在栈段中,而n_ptr和c_ptr指向的变量,由于是malloc或new出来的,所以存放在堆中。当函数func返回时,a、n_ptr、c_ptr都会被释放,但是n_ptr和c_ptr指向的内存却不会释放。因为它们是存在于堆中的数据。
在图1中,文件名为stack的内存区间即为栈段。
6.heap段
heap(堆)是最自由的一种内存,它完全由程序来负责内存的管理,包括什么时候申请,什么时候释放,而且对它的使用也没有什么大小的限制。在C/C++中,用alloc系统函数和new申请的内存都存在于heap段中。
以上面的程序为例,它向堆申请了一个int和一个char的内存,因为没有调用free或delete,所以当函数返回时,堆中的int和char变量并没有释放,造成了内存泄漏。
由于在图1所对应的代码中没有使用alloc系统函数或new来申请内存,所以heap段并没有在图1中显示出来,所以以下面的程序来说明heap段的位置,代码文件为heap.c,代码如下:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main()
{
int *n_ptr = malloc(sizeof(int));
printf("%d\n", getpid());
while(1);
free(n_ptr);
return 0;
}
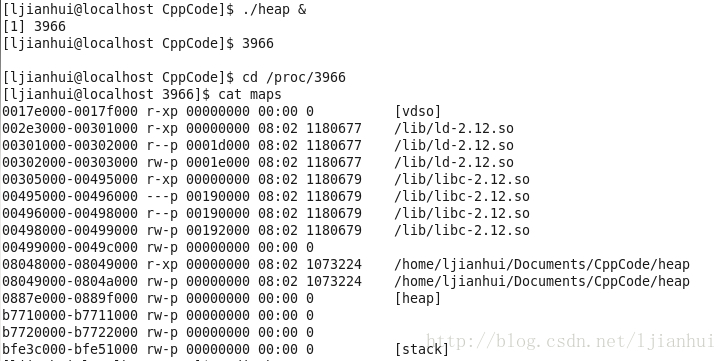
查看其运行时内存空间分布如下:
可以看到文件名为heap的内存区间就是heap段。从上图,也可以看出,虽然我们只申请4个字节(sizeof(int))的空间,但是在操作系统中,内存是以页的方式进行管理的,所以在分配heap内存时,还是一次分配就为我们分配了一个页的内存。注:无论是图1,还是上图,都有一些没有文件名的内存区间,其实没用文件名的内存区间表示使用mmap映射的匿名空间。















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









