
sql
 关注
关注
 分享
分享
chimchim66
火火要努力变强啊。。。
展开
专栏收录文章
- 默认排序
- 最新发布
- 最早发布
- 最多阅读
- 最少阅读
-
pg统计磁盘占用大小
pg查看内存大小原创 2023-03-28 11:41:18 · 2801 阅读 · 0 评论 -
Postgre SQL ERROR:there is no unique or exclusion constraint matching the ON CONFLICT specification
pg constraint报错原创 2023-02-24 15:51:11 · 4480 阅读 · 0 评论 -
hive只复制表结构不复制表数据
hive原创 2023-02-23 15:58:01 · 1238 阅读 · 0 评论 -
PostgreSQL update/delete/upsert关联更新字段数据
PostgreSQL update/delete/upsert关联更新字段数据原创 2023-02-07 10:36:19 · 6142 阅读 · 0 评论 -
正则表达式之量词
正则表达式之量词原创 2023-02-06 07:51:18 · 538 阅读 · 0 评论 -
Postgresql简单操作
Postgresql简单操作原创 2022-12-19 18:05:42 · 4162 阅读 · 1 评论 -
hive补全连续或非连续空值数据sql
hive补全连续或非连续空值数据sql原创 2022-12-01 18:40:38 · 2019 阅读 · 0 评论 -
hive判断重复数据连续并分组
连续重复数据合并原创 2022-11-15 13:57:48 · 966 阅读 · 0 评论 -
sql判断是否连续并生成连续分组id
sql判断是否连续并生成连续分组id原创 2022-11-10 11:37:11 · 785 阅读 · 0 评论 -
hive-行转列按顺序合并
行转列按顺序合并原创 2022-11-07 14:14:44 · 1689 阅读 · 0 评论 -
Postgre时间戳与日期格式转换
Postgre时间戳与日期格式转换原创 2022-10-11 11:38:25 · 3330 阅读 · 0 评论 -
flink sql实战案例
flink sql实战案例原创 2022-09-15 21:14:20 · 2356 阅读 · 0 评论 -
SQL之mysql到hive批量生成建表语句
SQL之mysql到hive批量生成建表语句原创 2022-08-17 11:28:51 · 1101 阅读 · 0 评论 -
hive创建唯一标识列(自增id)
hive创建唯一标识列(自增id)原创 2022-08-15 16:53:09 · 4489 阅读 · 0 评论 -
hive索引
hive索引学习原创 2022-08-11 15:46:44 · 1414 阅读 · 0 评论 -
波峰波谷sql
波峰浪谷sql原创 2022-06-21 10:54:25 · 547 阅读 · 0 评论 -
hive行转列/列转行
准备建表语句:create table syc_ads.test_transform ( name string comment '姓名', constellation string comment '星座', blood string comment '血型', hobby string comment '爱好');准备测试数据:insert into table syc_ads.test_transform va原创 2022-05-20 15:20:56 · 429 阅读 · 0 评论 -
浅谈并对比不同数据库sql执行顺序
大致执行顺序:先执行from关键字后面的语句,明确数据的来源,它是从哪张表取来的。再进行on的过滤。之后join, 这样就避免了两个大表产生全部数据的笛卡尔积的庞大数据。接着执行where关键字后面的语句,对数据进行筛选。再接着执行group by后面的语句,对数据进行分组分类。然后执行select后面的语句,也就是对处理好的数据,具体要取哪一部分。最后执行order by后面的语句,对最终的结果进行排序。最后limit限制数据条数。from-where-groupby-having-se原创 2022-05-19 14:26:35 · 1147 阅读 · 2 评论 -
表结构变更解决方案
背景:业务库表结构发生变更(新增或删除字段)处理步骤:1.把表移至tmp库:altertableods.table_namerenametotmp.table_name;2.表移除之后,检查对应Hadoop目录是否已移除:hadoopfs-du-h/user/hive/warehouse/ods.db|greptable_name3.设置gzip压缩的参数,再把数据插入回原来的表:sethive.exec.dynamic.p...原创 2022-05-10 14:31:07 · 760 阅读 · 0 评论 -
hive日期格式转换
固定日期转换成时间戳select unix_timestamp('2022-05-09','yyyy-MM-dd');select unix_timestamp('20220509','yyyyMMdd');select unix_timestamp('2022-05-09T10:02:41Z', "yyyy-MM-dd'T'HH:mm:ss'Z'");16/Mar/2022:12:25:01 +0800转成正常格式(yyyy-MM-dd hh:mm:ss)select ...原创 2022-05-10 14:31:30 · 1851 阅读 · 0 评论 -
mysql获取当天,昨天,本周,本月,上周,上月的起始时间函数
– 今天SELECT DATE_FORMAT(NOW(),'%Y-%m-%d 00:00:00') AS '今天开始';SELECT DATE_FORMAT(NOW(),'%Y-%m-%d 23:59:59') AS '今天结束';– 昨天SELECT DATE_FORMAT( DATE_SUB(CURDATE(), INTERVAL 1 DAY), '%Y-%m-%d 00:00:00') AS '昨天开始';SELECT DATE_FORMAT( DATE_SUB(CURDATE(),原创 2022-05-07 16:13:37 · 403 阅读 · 0 评论 -
hive/maxcomputer查看单个表存储大小
desc 表名;查询出size大小select concat(7827978157/1024/1024,'MB')其他单位自己转换哈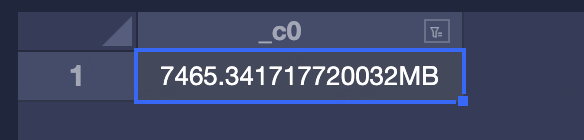原创 2022-04-20 15:45:19 · 1965 阅读 · 3 评论 -
查询统计mysql占用磁盘空间大小
1.统计某个库的各个表的数据和索引的占用空间大小selectTABLE_NAME,concat(truncate(data_length/1024/1024,2),’ MB’) as data_size,concat(truncate(index_length/1024/1024,2),’ MB’) as index_sizefrom information_schema.tableswhere TABLE_SCHEMA = ‘tab’order by data_length desc;2.原创 2022-04-20 10:31:11 · 1632 阅读 · 0 评论 -
查看mysql数据库存储大小
要想知道每个数据库的大小的话,步骤如下:1、进入information_schema 数据库(存放了其他的数据库的信息)use information_schema;2、查询所有数据的大小:select concat(round(sum(data_length/1024/1024),2),‘MB’) as data from tables;3、查看指定数据库的大小:比如查看数据库home的大小select concat(round(sum(data_length/1024/1024),2),‘原创 2022-04-20 10:21:55 · 4928 阅读 · 0 评论 -
hive修改表备注,字段备注
修改表备注:ALTER TABLE 数据库名.表名 SET TBLPROPERTIES('comment' = '新的表备注');修改字段信息:ALTER TABLE 数据库名.表名 CHANGE COLUMN 字段名 新的字段名(如果不变就保持原字段) 字段类型(若不变就采用原来的字段) COMMENT '新的字段备注'; ...原创 2022-02-21 18:04:32 · 1508 阅读 · 0 评论 -
GROUP_CONCAT函数切换实例
函数原创 2022-02-10 15:48:55 · 1058 阅读 · 0 评论 -
hive、maxcompute计算当月累计、当年累计值示例
select etl_date ,sum(order_cnt) over(partition by etl_month order by etl_date asc) as order_cnt_1m --当月累计订单量 ,sum(order_cnt) over(partition by etl_year order by etl_date asc) as order_cnt_1y --当年累计订单量from ( select原创 2022-01-13 16:00:27 · 2599 阅读 · 0 评论 -
拉链表起始时间转成多行日期
dataphin拉链表起始时间转成多行日期:(ps:dataphin split()怎么都识别不出空格,自闭了。。。替换成字符解决了)select a.*,b.*,dateadd(start_time,pos,'dd')from (select'2021-10-01 00:00:00' as start_time,'2021-10-03 00:00:00' as end_time) alateral view posexplode(split(replace(space(datediff(e原创 2021-10-28 16:40:47 · 962 阅读 · 0 评论 -
hive批量删除多个分区数据
举个栗子????:批量删除2019-01-01到2020-09-03号范围内的分区alter table drop partition (ds<‘2020-09-03’,ds>‘2019-01-01’);原创 2020-09-03 17:14:55 · 5865 阅读 · 0 评论 -
hive 计算连续7天登录的用户
整体实现思路:1.用户每天可能不止登陆一次,将登录日期去重,取出当日登陆成功的日期,row_number()函数分组排序并计数2.日期减去计数得到值3.根据每个用户count(值)判断连续登陆天数4.最后取连续登陆天数大于等于7天的用户示例:CREATE TABLE db_test.user_log_test(datestr string comment ‘日期’,uid string comment ‘用户id’,status int comment ‘登陆状态 1:成功 0:失败’)原创 2020-08-30 17:11:56 · 3265 阅读 · 0 评论 -
剔除 HIVE中select除了某些字段之外的剩余所有字段
只需要设置参数set hive.support.quoted.identifiers=None;指定要剔除哪个字段select (剔除的字段)?+.+ from table示例:选择tableName表中除了name、id、pwd之外的所有字段:set hive.support.quoted.identifiers=None;select (name|id|pwd)?+.+ from tableName;选择tableName表中除了ds之外的所有字段:set hive.support.q原创 2020-08-30 14:30:45 · 2901 阅读 · 2 评论