






携手创作,共同成长!这是我参与「掘金日新计划 · 8 月更文挑战」的第4天,点击查看活动详情
对于数组遍历,基本上每个开发者都写过,遍历本身没什么好说的,但是当我们在遍历的过程中,有一些复杂的业务逻辑时,将会发现代码的层级会逐渐加深
如一个简单的case,将一个二维数组中的偶数找出来,保存到一个列表中
二维数组遍历,每个元素判断下是否为偶数,很容易就可以写出来,如
public void getEven() {
int[][] cells = new int[][]{{1, 2, 3, 4}, {11, 12, 13, 14}, {21, 22, 23, 24}};
List<Integer> ans = new ArrayList<>();
for (int i = 0; i < cells.length; i ++) {
for (int j = 0; j < cells[0].length; j++) {
if ((cells[i][j] & 1) == 0) {
ans.add(cells[i][j]);
}
}
}
System.out.println(ans);
}
复制代码上面这个实现没啥问题,但是这个代码的深度很容易就有三层了;当上面这个if中如果再有其他的判定条件,那么这个代码层级很容易增加了;二维数组还好,如果是三维数组,一个遍历就是三层;再加点逻辑,四层、五层不也是分分钟的事情么
那么问题来了,代码层级变多之后会有什么问题呢?
只要代码能跑,又能有什么问题呢?!
1. 函数方法消减代码层级
由于多维数组的遍历层级天然就很深,那么有办法进行消减么?
要解决这个问题,关键是要抓住重点,遍历的重点是什么?获取每个元素的坐标!那么我们可以怎么办?
定义一个函数方法,输入的就是函数坐标,在这个函数体中执行我们的遍历逻辑即可
基于上面这个思路,相信我们可以很容易写一个二维的数组遍历通用方法
public static void scan(int maxX, int maxY, BiConsumer<Integer, Integer> consumer) {
for (int i = 0; i < maxX; i++) {
for (int j = 0; j < maxY; j++) {
consumer.accept(i, j);
}
}
}
复制代码主要上面的实现,函数方法直接使用了JDK默认提供的BiConsumer,两个传参,都是int 数组下表;无返回值
那么上面这个怎么用呢?
同样是上面的例子,改一下之后,如
public void getEven() {
int[][] cells = new int[][]{{1, 2, 3, 4}, {11, 12, 13, 14}, {21, 22, 23, 24}};
List<Integer> ans = new ArrayList<>();
scan(cells.length, cells[0].length, (i, j) -> {
if ((cells[i][j] & 1) == 0) {
ans.add(cells[i][j]);
}
});
System.out.println(ans);
}
复制代码相比于前面的,貌似也就少了一层而已,好像也没什么了不起的
但是,当数组变为三维、四维、无维时,这个改动的写法层级都不会变哦
2. 遍历中return支持
前面的实现对于正常的遍历没啥问题;但是当我们在遍历过程中,遇到某个条件直接返回,能支持么?
如一个遍历二维数组,我们希望判断其中是否有偶数,那么可以怎么整?
仔细琢磨一下我们的scan方法,希望可以支持return,主要的问题点就是这个函数方法执行之后,我该怎么知道是继续循环还是直接return呢?
很容易想到的就是执行逻辑中,添加一个额外的返回值,用于标记是否中断循环直接返回
基于此思路,我们可以实现一个简单的demo版本
定义一个函数方法,接受循环的下标 + 返回值
@FunctionalInterface
public interface ScanProcess<T> {
ImmutablePair<Boolean, T> accept(int i, int j);
}
复制代码循环通用方法就可以相应的改成
public static <T> T scanReturn(int x, int y, ScanProcess<T> func) {
for (int i = 0; i < x; i++) {
for (int j = 0; j < y; j++) {
ImmutablePair<Boolean, T> ans = func.accept(i, j);
if (ans != null && ans.left) {
return ans.right;
}
}
}
return null;
}
复制代码基于上面这种思路,我们的实际使用姿势如下
@Test
public void getEven() {
int[][] cells = new int[][]{{1, 2, 3, 4}, {11, 12, 13, 14}, {21, 22, 23, 24}};
List<Integer> ans = new ArrayList<>();
scanReturn(cells.length, cells[0].length, (i, j) -> {
if ((cells[i][j] & 1) == 0) {
return ImmutablePair.of(true, i + "_" + j);
}
return ImmutablePair.of(false, null);
});
System.out.println(ans);
}
复制代码上面这个实现可满足我们的需求,唯一有个别扭的地方就是返回,总有点不太优雅;那么除了这种方式之外,还有其他的方式么?
既然考虑了返回值,那么再考虑一下传参呢?通过一个定义的参数来装在是否中断以及返回结果,是否可行呢?
基于这个思路,我们可以先定义一个参数包装类
public static class Ans<T> {
private T ans;
private boolean tag = false;
public Ans<T> setAns(T ans) {
tag = true;
this.ans = ans;
return this;
}
public T getAns() {
return ans;
}
}
public interface ScanFunc<T> {
void accept(int i, int j, Ans<T> ans)
}
复制代码我们希望通过Ans这个类来记录循环结果,其中tag=true,则表示不用继续循环了,直接返回ans结果吧
与之对应的方法改造及实例如下
public static <T> T scanReturn(int x, int y, ScanFunc<T> func) {
Ans<T> ans = new Ans<>();
for (int i = 0; i < x; i++) {
for (int j = 0; j < y; j++) {
func.accept(i, j, ans);
if (ans.tag) {
return ans.ans;
}
}
}
return null;
}
public void getEven() {
int[][] cells = new int[][]{{1, 2, 3, 4}, {11, 12, 13, 14}, {21, 22, 23, 24}};
String ans = scanReturn(cells.length, cells[0].length, (i, j, a) -> {
if ((cells[i][j] & 1) == 0) {
a.setAns(i + "_" + j);
}
});
System.out.println(ans);
}
复制代码这样看起来就比前面的要好一点了
实际跑一下,看下输出是否和我们预期的一致;
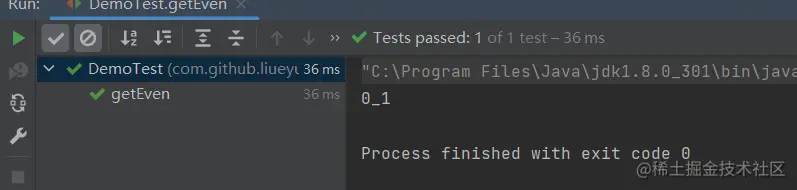
3.小结
到此一个小的技巧就分享完毕了,各位感兴趣的小伙伴可以关注我的公众号“一灰灰blog”
最近正在整理的 * 分布式设计模式综述 | 一灰灰Learning 欢迎各位大佬点评














 974
974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









