






随着大模型的新起,vectorstore这1、2年也非常的火。从以前只能用chroma到现在几十种向量数据库,选都选不过来。
以我接触过的很多公司来说,他们去选择向量数据库的时候,很多都和迷茫,不知道应该选择哪个向量数据库,甚至也不知道市面上有哪些向量数据库,甚至很多公司就随便选了一个差不多的,先用起来再说。
今天,我就抛砖引玉,以我对向量数据库的理解,来为向量数据库选型做一个对比和介绍,大家也可以聊聊你们现在用的是哪款向量数据库。
这里先不看云厂商的vectorstore,因为很多公司由于应用都在阿里云、腾讯云或者其他的云厂商,为了所谓的兼容或者减少运维成本,就直接选了dashvector或者其他的云向量数据库,我们仅来谈谈非云厂商的向量数据库。
同时我们再排除非专业做向量数据库的,比如redis,neo4j,cassandra,solr,clickhouse,elasticsearch,mongodb atlas。毕竟这些存储,不是用来专业做vectorstore的。
那么剩下来,在国内能耳熟能详的,我觉得有以下几个。
- pinecone
- pgvector
- qdrant
- milvus
- weaviate
- chroma
以上排名,不分先后,文章最后,我们根据我的项目经验,给大家稍微介绍一下优劣。
vectorstore选好了,接下来,就要看看从哪些维度来对比:
我们就从以下角度来吧:
1、base
1.1 oss : 是否开源,用户是否可以私有化部署
1.2 License: 采用什么license
1.3 DevLang:开发语言用的什么
1.4 VSS Lanuch: 第一个relase版本的发布时间
2、Search
2.1 Filters:过滤的意思是,在查询的时候,是否可以根据metadata进行过滤。比如大家都会的,在我们的rag高级实战课中介绍过的self-query,就是当用户的问题过来后,我们可以先通过filters过滤掉无用的document,从而达到很好的效果。特别是范围查询的时候,比如一个电影推荐的vectorstore,比如,用户如果问,香港的动作电影。这个时候,filters可以直接按照metadata按照地区和电影类型进行过滤。所以这个filters,一般的vectore,都应该支持。
2.2 Hybrid Search: hybrid search的意思是,我可以通过关键词keyword+向量搜索vector search一起进行搜索,这个在高级的rag中也经常使用,特别是使用RRF获取更多rag的相关结果。比如在电商中,可以先搜索关键词,搜索出来的结果后,再通过品牌,价格区间,评分进行细分,与lucene类似,如果大家以前对搜索有一定研究的话,就可以知道,这个相当于搜索结果再分组,类似与lucene、solr等搜索引擎。
2.3 facets: 与前面说的filters类似,facets也是用来过滤结果的。只是,filters是在查询前过滤,减少搜索范围。而facets用于查询结果出来以后,进一步细分或者分组。
2.4 Geo search :就是地理位置坐标的支持,从而可以快速的计算出多个位置之间的距离和联系。
2.5 Multi-vector:为了实现多视角查询、多模态查询、分层查询、混合语义查询,vectorstore需要支持multi-vector功能。
2.6 sparse: 有的时候,用户已经有特定需求或者已经有了现成的稀疏向量,而不需要依赖vectorstore或系统内置的算法来生成vector。.
2.7 BM25: 是否内置bm25
2.8 full-text : 是否内置全文检索,类似lucene、solr等
3、Models
3.1 Text Model: 是否内置或者插件支持类似sentence-transformers或者 huggingface等文本embedding模型。
3.2 Image Model: 是否支持图像embedding,比如CLIP.
3.3 Struct Model:是否支持struct model,比如user click,graph等。
4、Apis
4.1 langchain :是否支持langchain
4.3 llamaindex: 是否支持llamaindex
4.4 rag: 是否支持rag的全部高级功能
4.5 Recsys: 是否内置推荐系统等功能
5、ops
5.1 Managed: 是否提供云端管理
5.2 Pricing: 是否提供收费服务
5.3 in-process:应用程序级别的
5.4 Multi renant:是否支持多租户
5.5 disk index:是否支持硬盘存储index
5.6 ephemeral index: 在没有部署的情况下, 是否可用,比如Memory的支持。
5.7 sharding:是否支持sharding 负载均衡
5.8 document维度大小:最大支持的vector dims
5.9 int8 quantization:是否支持int8量化
5.10 binary quantization: 是否支持binary量化
5.11 index type: index的类型,比如:flat,flat-bq,hns,freshdiskann等。
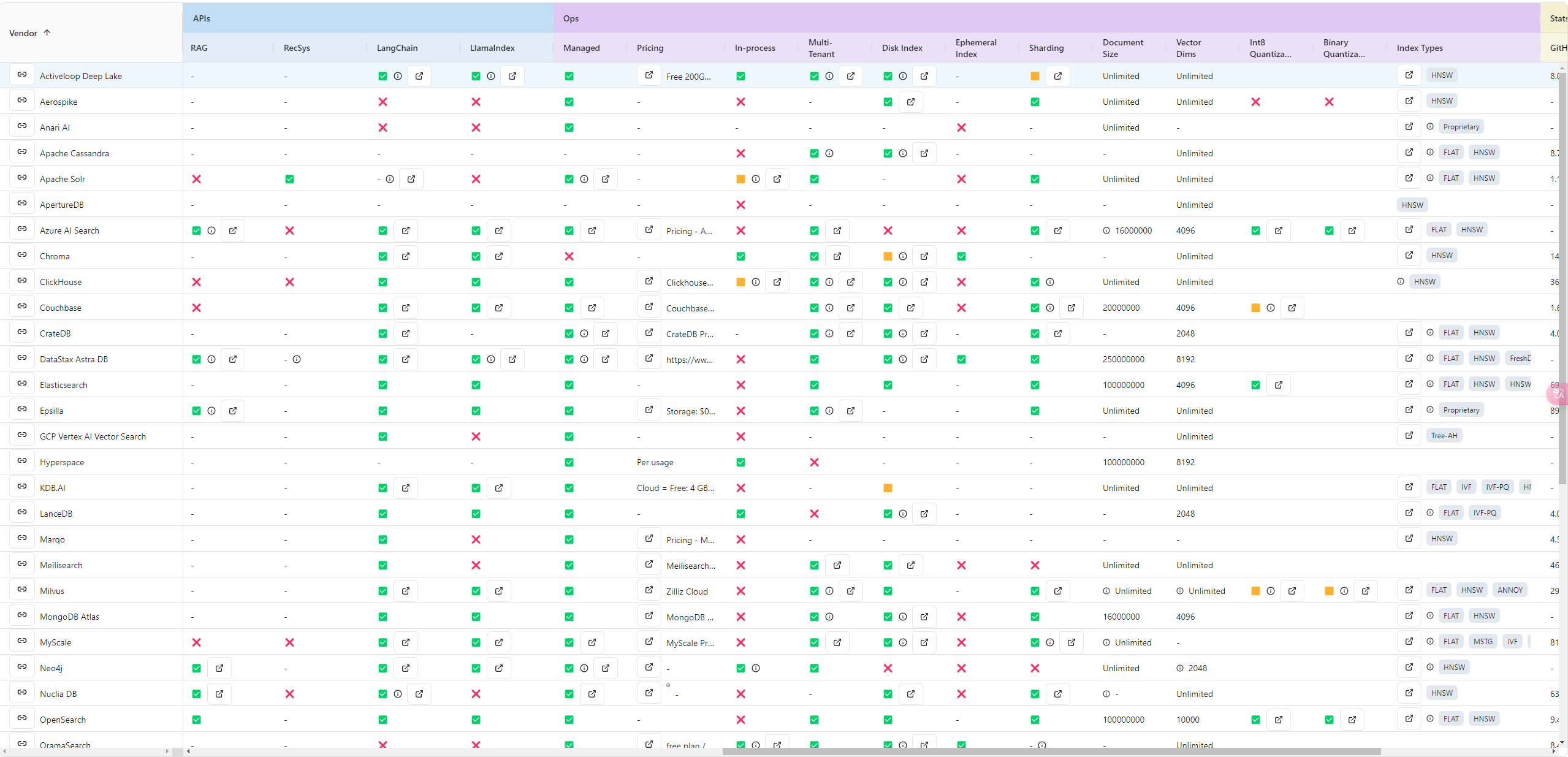
接下来,我们2个2个比较一下:






大家可以根据上面的截图,和我上面的指标介绍,按照自己的业务系统对vectorstore的功能和部署方式,来选择您觉得最适合你们的vectorstore。
大家在选择向量数据库的时候,还是需要按照自己的需求来。看看你们的业务是否需要vectorstor的一些高级功能,比如:filter,hybrid search,facets,multi-vector,sparse,bm25等等。
另外,也是特别关键的一点,就是你的数据是否有严格的合规和安全需求,是否允许存储在云上。虽然存储在云上的好处很多,但是如果你们团队对数据资产十分的看中,您也可以选择类似qdrant的vectorstore,自有存储,自有维护。
还是那句话,大家在做向量数据库选型的时候,一定要多对比几个产品,同时一定要清楚公司的业务,到底需要vector提供什么样的能力,在来进行对比。
整个所有向量数据库的对比表格,如果您需要的话,私聊我,我把地址发给您。
关注我,每天带你开发一个AI应用,每周二四六直播,欢迎多多交流。
















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









