







基本开发环境💨
Python 3.6
Pycharm
相关模块的使用💨
import requests
import os
安装Python并添加到环境变量,pip安装需要的相关模块即可。
一、💥明确需求
爬取某音乐网站的排行榜歌曲。
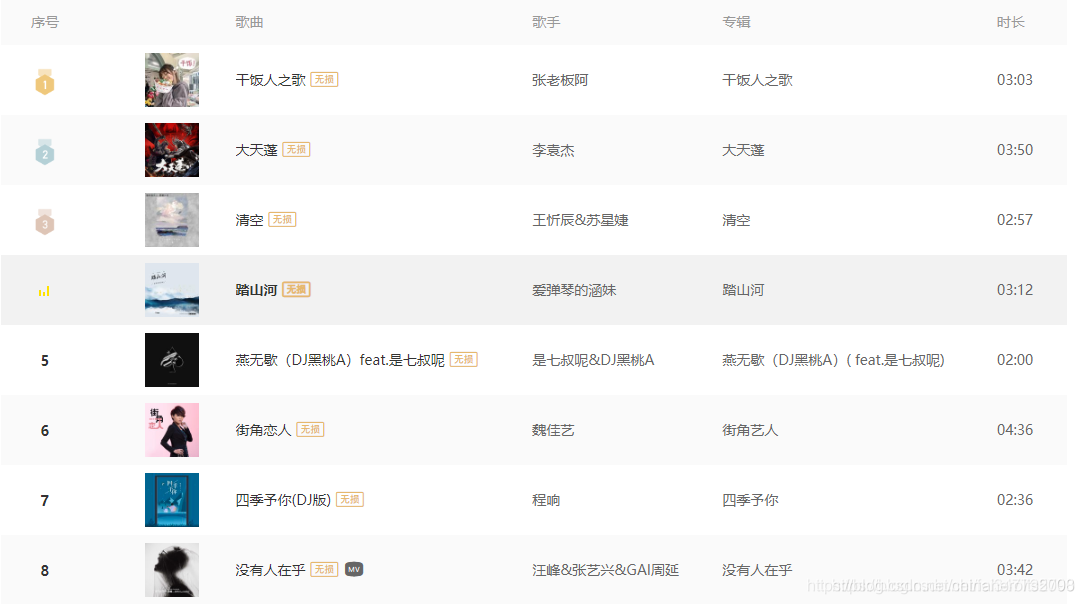
二、💥网页数据分析
1、F12或者鼠标右键点击检查打开开发者工具,点击播python基础教程放音乐,下面会加载出音乐数据。
# 干饭人之歌 音频数据地址:
https://gm-sycdn.kuwo.cn/82c2c756b7ebeacb907831ff0906199e/601a3aa9/resource/n2/88/78/3642423505.mp3
复制链接粘贴到浏览器中
2、根据音频链接中的参数,搜索查找来源
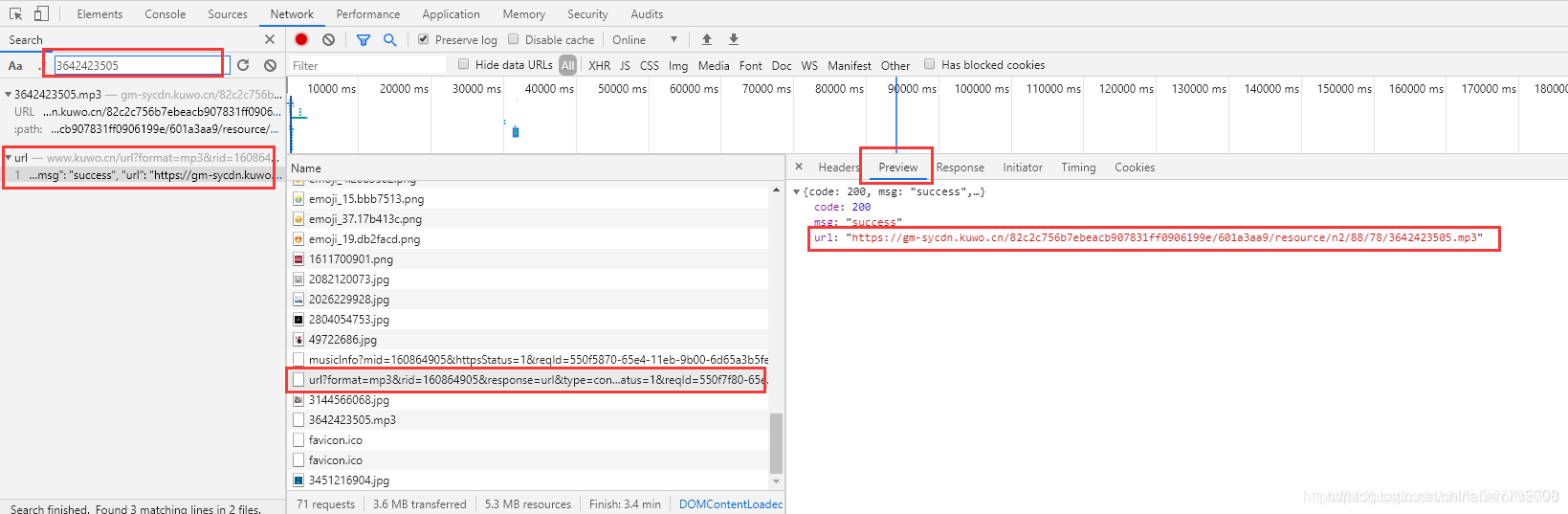
音频链接来源
https://www.kuwo.cn/url?format=mp3&rid=160864905&response=url&type=convert_url3&br=128kmp3&from=web&t=1612331691895&httpsStatus=1&reqId=550f7f80-65e4-11eb-9b00-6d65a3b5fef1
一首歌曲的来源地址是找不出规律的,所以要再对比一些另外一首歌曲的链接参数
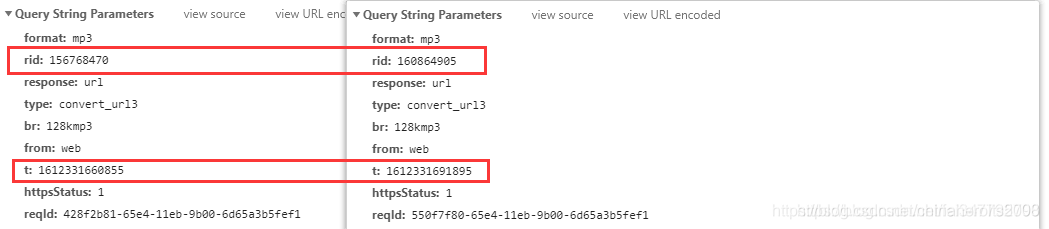
如图所示: rid 和 t 参数不一样,很明显 t 就是代表的时间戳,这个使用 time.time() 就有了,所以可以继续在开发者工具中搜索 rid 的值
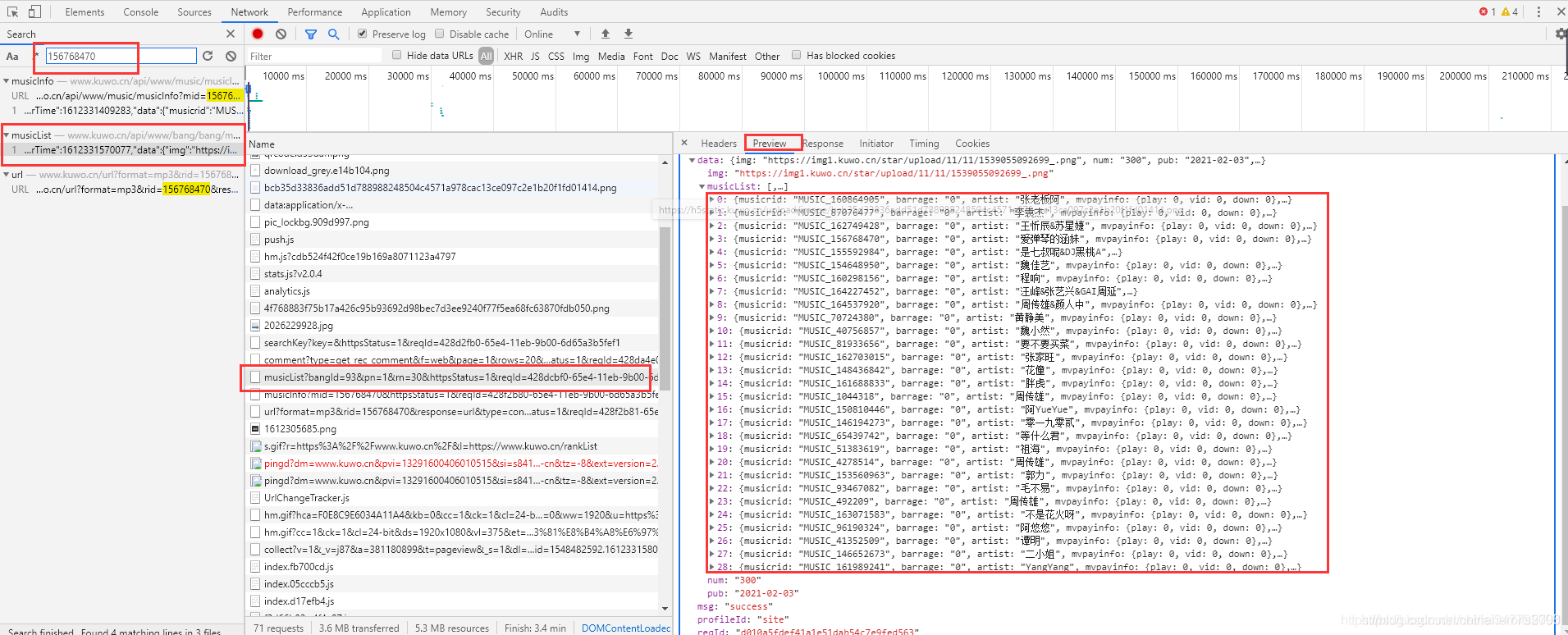
https://www.kuwo.cn/api/www/bang/bang/musicList?bangId=93&pn=1&rn=30&httpsStatus=1&reqId=428dcbf0-65e4-11eb-9b00-6d65a3b5fef1
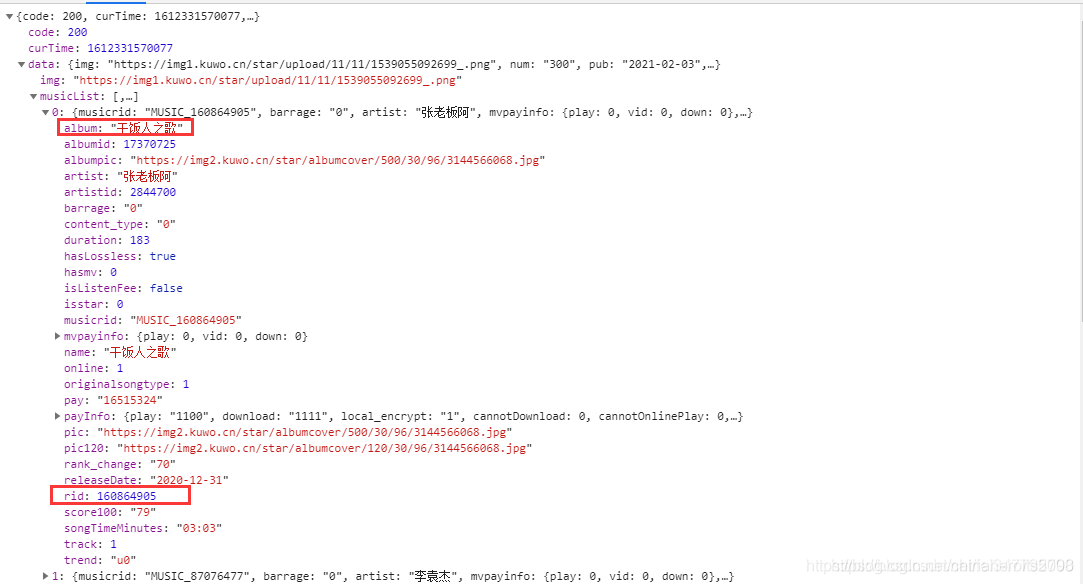
rid 以及 歌名 歌手名都有了。
三、💥代码实现
爬虫分析思路是从上到下开始分析,写代码则是从下往上写。
1、获取音乐的 rid 、歌名、歌手名
import pprint
import requests
def get_response(html_url):
headers = {
'Cookie': '你自己的cookie',
'csrf': 'D2YF7NMH81N',
'Host': 'www.kuwo.cn',
'Referer': 'https://www.kuwo.cn/rankList',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=html_url, headers=headers)
return response
def get_music_info(html_url):
json_data = get_response(html_url).json()
pprint.pprint(json_data)
music_list = json_data['data']['musicList']
for index in music_list:
music_name = index['album']
singer = index['artist']
music_rid = index['rid']
if __name__ == '__main__':
url = 'https://www.kuwo.cn/api/www/bang/bang/musicList?bangId=93&pn=1&rn=30&httpsStatus=1&reqId=428dcbf0-65e4-11eb-9b00-6d65a3b5fef1'
get_music_info(url)
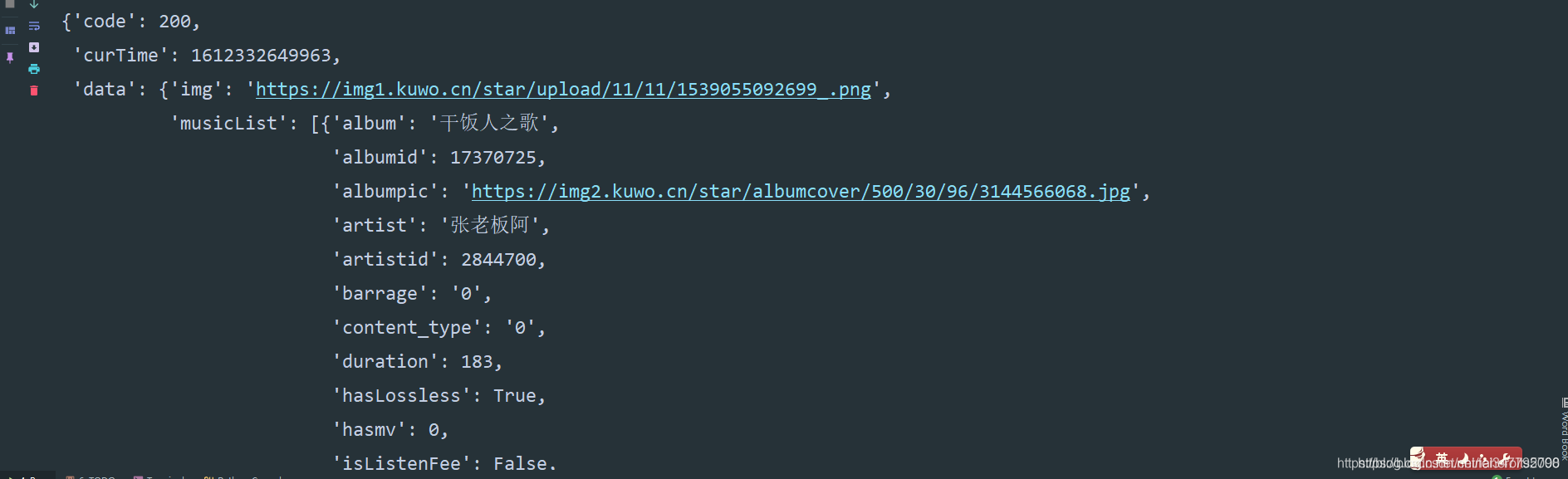
返回的是一个json数据,一个一个去取值就可以了,主要的注意点就是headers参数的问题,如果参数不给全,爬取不到数据。
2、获取音频URL地址
def get_music_url(music_rid):
page_url = f'https://www.kuwo.cn/url?format=mp3&rid={music_rid}&response=url&type=convert_url3&br=128kmp3&from=web&t=1612331691895&httpsStatus=1&reqId=550f7f80-65e4-11eb-9b00-6d65a3b5fef1'
json_data = get_response(page_url).json()
music_url = json_data['url']
return music_url
3、保存音频数据
def save(music_name, music_url):
path = 'music\\'
if not os.path.exists(path):
os.makedirs(path)
filename = path + music_name + '.mp3'
headers = {
'if-range': '8eba7fc5d5b2f4d223d54612aa3f4773',
'range': 'bytes=524288-524288',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400',
}
music_content = requests.get(url=music_url, headers=headers).content
with open(filename, mode='wb') as f:
f.write(music_content)
print('正在保存:', music_name)
请求音乐下载的地址的 headers 需要更换一下。不然爬取不了音乐。


















 7517
7517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









