







 本文介绍了使用Webdriver自动化控制超级浏览器进行店铺环境管理和数据抓取的方法。首先,通过Socket通信与超级浏览器主进程交互,获取店铺列表并准备店铺环境。然后,利用Selenium API启动和控制浏览器内核,实现店铺的自动化操作。同时,文中详细阐述了Socket通信的注意事项,包括请求响应格式和异常处理。此外,还提供了几个关键接口如获取店铺列表、启动和关闭店铺的详细说明。
本文介绍了使用Webdriver自动化控制超级浏览器进行店铺环境管理和数据抓取的方法。首先,通过Socket通信与超级浏览器主进程交互,获取店铺列表并准备店铺环境。然后,利用Selenium API启动和控制浏览器内核,实现店铺的自动化操作。同时,文中详细阐述了Socket通信的注意事项,包括请求响应格式和异常处理。此外,还提供了几个关键接口如获取店铺列表、启动和关闭店铺的详细说明。
超级浏览器Webdriver自动化开发
一、概述
通过Webdriver实现对超级浏览器内的店铺进行,自动化控制以及数据抓取,主要流程分为以下两个部分
(一)与超级浏览器主进程通信。
这个部分是通过Socket实现与超级浏览器主进实现通讯的,主要工作是获取店铺列表以及准备店铺环境,一个店铺相当于一个独立浏览器。
import json
import subprocess
from socket import *
from selenium import webdriver
from db.db_redis import DBRedis
from common.utility import Utility
from common.mapping import Mapping
from common.global_logger import logger
from selenium.webdriver import ActionChains
from selenium.common.exceptions import NoSuchElementException
class SuperBrowser(object):
# 基础配置
utils = Utility()
config = utils.confg
# 初始化Redis服务
obj_redis = DBRedis()
# 获取业务类型
business_type = config.get('business_type')
logger.info("business_type: %s" % business_type)
# 指定使用英语
__LANGUAGE = config.get('language')
# ----------------------------------------->> Socket通信地址端口
host = config.get('socket_host')
port = int(config.get('socket_port'))
logger.info('socket > host: %s, port: %s' % (host, port))
# ----------------------------------------->> 请求紫鸟超级浏览器API方法
__GET_BROWSER_LIST = "getBrowserList" # 获取店铺列表
__START_BROWSER = "startBrowser" # 启动店铺(主程序)
__STOP_BROWSER = "stopBrowser" # 关闭店铺窗口
__GET_BROWSER_ENV_INFO = "getBrowserEnvInfo" # 启动店铺(webdriver)
__HEARTBEAT = "heartbeat" # 非必要接口,只是用于保活Socket连接
__EXIT = "exit" # 正常退出超级浏览器主进程,会自动关闭已启动店铺并保持店铺cookie等信息。
def __init__(self):
logger.info("初始化Socket连接...")
logger.info("启动紫鸟浏览器......")
self.buf_size = int(self.config.get('socket_buf_size'))
self.IS_HEADLESS = self.config.get('browser_is_headless') # 浏览器是否启用无头模式 false 否、true 是
# 获取紫鸟·超级浏览器安装路径
path_super_browser = self.config.get('path_super_browser')
cmd = "{} --run_type=web_driver --socket_port={}".format(path_super_browser, self.port)
subprocess.Popen(cmd)
try:
# ------------------------------创建套接字通道
self.address = (self.host, self.port)
self.tcpCliSock = socket(AF_INET, SOCK_STREAM) # 创建套接字
self.tcpCliSock.connect(self.address) # 主动初始化TCP服务器连接
except ConnectionRefusedError as e:
logger.error(e)
subprocess.Popen('taskkill /f /im superbrowser.exe')
except Exception as e:
logger.error(e)
def browser_api(self, action, args=None):
"""
紫鸟·超级浏览器API
:param action: 方法
:param args: 可选参数
:return:
"""
REQUEST_ID = "0123456789" # 全局唯一标识
user_info = json.dumps({ # 用户信息
"company": self.config.get('browser_company_name'),
"username": self.config.get('browser_username'),
"password": self.config.get('browser_password')
})
# 默认为获取店铺列表
common = {"userInfo": user_info, "action": self.__GET_BROWSER_LIST, "requestId": REQUEST_ID}
if action == self.__START_BROWSER or action == self.__GET_BROWSER_ENV_INFO or action == self.__STOP_BROWSER:
common['browserOauth'] = args['browserOauth']
common['isHeadless'] = args['isHeadless']
common['action'] = action
return common
def socket_communication(self, params):
"""
Socket通信
:param params: 参数对象
:return:
"""
try:
args = (str(params) + '\r\n').encode('utf-8')
# 将 string 中的数据发送到连接的套接字
self.tcpCliSock.send(args)
# 接收的最大数据量
res = self.tcpCliSock.recv(self.buf_size)
return json.loads(res)
except ConnectionResetError as e:
logger.warning("ConnectionResetError: %s" % e)
logger.info("socket 连接已关闭")
except Exception as e:
logger.error("socket_communication error: %s" % e)
pass
# 举个栗子🌰
def browser_list(self):
"""
获取店铺列表
这里采用Redis管理店铺,为了后期分布式部署准备。
:return:
"""
logger.info("")
logger.info("获取店铺列表.")
shop_list_params = self.browser_api(self.__GET_BROWSER_LIST)
shop_info = self.socket_communication(shop_list_params)
if shop_info['statusCode'] == 0:
browser_size = len(shop_info['browserList'])
logger.info("目前店铺总数: %s, 正在记录店铺信息...,请稍等." % browser_size)
current_time = Utility.curr_time()
for index, browser in enumerate(shop_info['browserList']):
index += 1
# site_id 对应的值
browser['site_name'] = Mapping.SiteIdExplain(browser['siteId'])
browserOauth = browser['browserOauth']
if browser['isExpired'] is False:
# 记录店铺的数据
key_completed = self.config.get('r_amz_shops_completed')
key_inProgress = self.config.get('r_amz_shops_inProgress')
params = json.dumps({
"type": self.business_type,
"browserOauth": browserOauth,
"browserName": browser['browserName'],
"browserIp": browser['browserIp'],
"siteId": browser['siteId'],
"site_name": browser['site_name'],
"isExpired": browser['isExpired']
})
# 检索该店铺数据是否已采集完成?
is_sismember = self.obj_redis.sismember(key_completed, params)
if is_sismember:
logger.info('%s, 已采集完成.' % browserOauth)
else:
self.obj_redis.sadd(key_inProgress, params)
pass
else:
# 代理IP过期告警...
title = "Amazon·货件状态" # 悬浮标题
iphone = self.config.get('ding_talk_iphone') # @的指定人
spider_name = self.config.get('sn_v_shipment_status') # 应用名称
browserName = browser['browserName'] # 店铺
site_name = browser['site_name'] # 所属平台
browserIp = browser['browserIp'] # 代理IP
cloud_server = self.config.get('cloud_server_name') # 云服务器名称
# 通知内容
inform_content = "##### @{} Amazon·货件状态*>应用名称: {}*>店铺: {}*>所属平台: {}*>代理IP: {}*>" \
"服务器: {}*>当前时间: {}*>店铺ID: {}*>是否过期:" \
" <font color=#FFOOOO size=3 face='隶书'>代理IP已过期</font>*>" \
.format(iphone, spider_name, browserName, site_name, browserIp,
cloud_server, current_time, browserOauth).replace('*', '\n\n')
self.utils.ding_talk_robot(1, title, inform_content, [iphone], False)
self.utils.sleep_message(5, "间歇....")
pass
pass
else:
logger.warning("statusCode:%s, err: %s" % (shop_info['statusCode'], shop_info['err']))
pass
(二)通过Selenium API 启动和控制超级浏览器内核
这个部分主要是由自动化程序开发者自行开发,需要自行了解Selenium API如何使用。启动Selenium时有些参数依赖与超级浏览器主进程通讯的结果
二、交互时序图
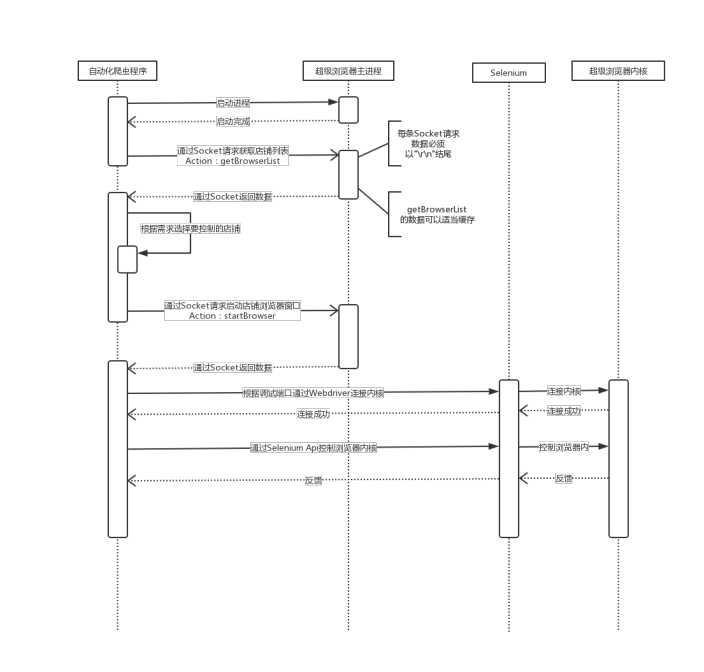
三、必要条件以及注意事项
(一)启动超级浏览器主进程必要配置启动参数
1、--run_type=web_driver
指定以Webdriver 模式运行主进程,本质是让超级浏览器以无界面状态运行。超级浏览器进程会自动保证进程唯一,所以多次启动会自动放弃后启动进程。但是手动点击启动的超级浏览器会Kill掉Webdriver 模式运行的进程
2、--socket_port=端口号
告诉超级浏览器双方socket通讯端口是什么,超级浏览器会以该端口在127.0.0.1启动一个socket服务端
# 获取紫鸟·超级浏览器安装路径
path_super_browser = self.config.get('path_super_browser')
cmd = "{} --run_type=web_driver --socket_port={}".format(path_super_browser, self.port)
subprocess.Popen(cmd)
(二)Socket通讯注意事项
1、每条Socket请求和响应数据必须以"\r\n"结尾
2、Socket请求内容和返回结果都是通过JSON结构组织,收发消息统一以UTF-8编码
3、Socket请求的相应都是异步返回的,可以并发执行,通过在请求参数里面添加一个全局唯一的requestId字段来标识请求,该字段会在响应内返回
def socket_communication(self, params):
"""
Socket通信
:param params: 参数对象
:return:
"""
try:
args = (str(params) + '\r\n').encode('utf-8')
# 将 string 中的数据发送到连接的套接字
self.tcpCliSock.send(args)
# 接收的最大数据量
res = self.tcpCliSock.recv(self.buf_size)
return json.loads(res)
except ConnectionResetError as e:
logger.warning("ConnectionResetError: %s" % e)
logger.info("socket 连接已关闭")
except Exception as e:
logger.error("socket_communication error: %s" % e)
pass
(三)其他注意事项
1、getBrowserEnvInfo返回数据不能复用,每次都要重新调用。
2、需要根据运行设备的配置,适当控制同时启动的店铺浏览器窗口总个数,店铺刚刚启动时非常消耗CPU可以考虑错开启动。这个部分需要开发者自行调优,没有明确的标准。
四、Socket接口说明
(一)Action : getBrowserList
1、说明:获取店铺列表
2、请求参数:
{
"userInfo": "{\"company\":\"公司\",\"username\":\"用户名\",\"password\":\"密码\"}",
"action": "getBrowserList",
"requestId": "全局唯一标识"
}
3、响应结果:
{
"statusCode": "状态码",
"err": "异常信息",
"action": "getBrowserList",
"requestId": "全局唯一标识",
"browserList": [{
"browserOauth": "店铺ID",
"browserName": "店铺名称",
"browserIp": "店铺IP",
"siteId": "店铺所属站点",
"isExpired": false //ip是否过期
}]
}
4、状态码:
(1)0 : 成功
(2)-10000 : 未知异常
(3)-10002 : Socket参数非法
(4)-10003 : 登录失败
(5)-10004 : 获取店铺列表时服务器返回异常
def browser_list(self):
logger.info("")
logger.info("获取店铺列表.")
shop_list_params = self.browser_api(self.__GET_BROWSER_LIST)
shop_info = self.socket_communication(shop_list_params)
if shop_info['statusCode'] == 0:
browser_size = len(shop_info['browserList'])
logger.info("目前店铺总数: %s, 正在记录店铺信息...,请稍等." % browser_size)
current_time = Utility.curr_time()
for index, browser in enumerate(shop_info['browserList']):
index += 1
# site_id 对应的值
browser['site_name'] = Mapping.SiteIdExplain(browser['siteId'])
browserOauth = browser['browserOauth']
if browser['isExpired'] is False:
# 記錄店鋪的數據
key_completed = self.config.get('r_amz_shops_completed')
key_inProgress = self.config.get('r_amz_shops_inProgress')
params = json.dumps({
"type": self.business_type,
"browserOauth": browserOauth,
"browserName": browser['browserName'],
"browserIp": browser['browserIp'],
"siteId": browser['siteId'],
"site_name": browser['site_name'],
"isExpired": browser['isExpired']
})
# 檢索該店鋪數據是否已采集完成?
is_sismember = self.obj_redis.sismember(key_completed, params)
if is_sismember:
logger.info('%s, 已采集完成.' % browserOauth)
else:
self.obj_redis.sadd(key_inProgress, params)
pass
else:
# 代理IP过期告警...
title = "Amazon·货件状态" # 悬浮标题
iphone = self.config.get('ding_talk_iphone') # @的指定人
spider_name = self.config.get('sn_v_shipment_status') # 应用名称
browserName = browser['browserName'] # 店铺
site_name = browser['site_name'] # 所属平台
browserIp = browser['browserIp'] # 代理IP
cloud_server = self.config.get('cloud_server_name') # 云服务器名称
# 通知内容
inform_content = "##### @{} Amazon·货件状态*>应用名称: {}*>店铺: {}*>所属平台: {}*>代理IP: {}*>" \
"服务器: {}*>当前时间: {}*>店铺ID: {}*>是否过期:" \
" <font color=#FFOOOO size=3 face='隶书'>代理IP已过期</font>*>" \
.format(iphone, spider_name, browserName, site_name, browserIp,
cloud_server, current_time, browserOauth).replace('*', '\n\n')
self.utils.ding_talk_robot(1, title, inform_content, [iphone], False)
self.utils.sleep_message(5, "间歇....")
pass
pass
else:
logger.warning("statusCode:%s, err: %s" % (shop_info['statusCode'], shop_info['err']))
pass
(二)Action : startBrowser
1、说明:启动店铺,关闭店铺需要调用stopBrowser,连续两次调用startBrowser会视为重启
2、请求参数:
{
"userInfo": "{\"company\":\"公司\",\"username\":\"用户名\",\"password\":\"密码\"}",
"action": "startBrowser",
"browserOauth": "店铺ID",
"isHeadless": true, //是否启用无头模式
"requestId": "全局唯一标识"
}
3、响应结果:
{
"statusCode": "状态码",
"err": "异常信息",
"action": "startBrowser",
"browserOauth": "店铺ID",
"requestId": "全局唯一标识",
"launcherPage": "店铺所属平台的默认启动页面",
"debuggingPort": "调试端口"
}
4、启动Selenium 必要参数
//根据startBrowser返回结果启动Selenium
ChromeOptions options = new ChromeOptions();
//调试端口
options.setExperimentalOption("debuggerAddress", "127.0.0.1:" + debuggingPort);
//删除其他不需要参数
def driver_browser(self, shop_obj):
"""
Selenium驱动浏览器(Chrome)
:param shop_obj: 店铺信息
:return:
"""
# 启动Selenium
self.utils.sleep_message(3, "启动Selenium.")
launcher_page, debugging_port = shop_obj['launcherPage'], shop_obj['debuggingPort']
logger.info("启动Selenium必要参数: debugging_port: %s, launcher_page: %s" % (debugging_port, launcher_page))
self.utils.sleep_message(2.5, "浏览器配置")
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", "127.0.0.1:" + str(debugging_port))
driver = webdriver.Chrome(executable_path='./files/driver/windows/80.0.3987.163/chromedriver', options=options)
self.utils.sleep_message(3, "进入店铺...")
driver.get(launcher_page)
return driver
5、状态码:
(1)0 : 成功
(2)-10000 : 未知异常
(3)-10001 : 内核窗口创建失败
(4)-10002 : Socket参数非法
(5)-10003 : 登录失败
(6)-10004 : browserOauth缺失
(7)-10005 : 该店铺上次请求的startBrowser还未执行结束
(8)大于零的状态码:
1 : 初始化数据失败
2 : 检测到当前IP无法正常使用,请联系客服
4 : 初始化时区失败
5 : 初始化代理失败
6 : 初始化黑白名单
7 : 启动内核失败
8 : 初始化浏览器个人目录
9 : 初始化Cookies失败
11 : 初始化浏览器设置文件
13 : 初始化代理信息配置
def start_browser(self, shop_id):
"""
启动店铺
:param shop_id: 店铺ID
:return:
"""
# 启动店铺(两种方式) startBrowser / getBrowserEnvInfo
start_params = self.browser_api(self.__START_BROWSER, {"browserOauth": shop_id, "isHeadless": self.IS_HEADLESS})
shop_obj = self.socket_communication(start_params)
logger.info("启动店铺信息: %s" % shop_obj)
return shop_obj
(三)Action : stopBrowser
1、说明:关闭店铺窗口
2、请求参数:
{
"userInfo": "{\"company\":\"公司\",\"username\":\"用户名\",\"password\":\"密码\"}",
"action": "stopBrowser",
"requestId": "全局唯一标识"
}
3、响应结果:
{
"statusCode": "状态码",
"err": "异常信息",
"action": "stopBrowser",
"requestId": "全局唯一标识"
}
4、状态码:
(1) 0 : 成功
(2)-10000 : 未知异常
(3)-10002 : Socket参数非法
(4)-10003 : 登录失败
def stop_browser(self, shop_id):
"""
关闭店铺
:param shop_id: 店铺ID
:return:
"""
logger.info("关闭店铺")
stop_params = self.browser_api(
self.__STOP_BROWSER, {
"browserOauth": shop_id,
"isHeadless": self.IS_HEADLESS
}
)
stop_obj = self.socket_communication(stop_params)
logger.info("关闭店铺信息: %s" % stop_obj)
(四)Action : getBrowserEnvInfo
1、说明:和startBrowser类似,区别就是内核窗口startBrowser由主程序启动,getBrowserEnvInfo由Webdriver启动
2、请求参数
{
"userInfo": "{\"company\":\"公司\",\"username\":\"用户名\",\"password\":\"密码\"}",
"action": "getBrowserEnvInfo",
"browserOauth": "店铺ID",
"isHeadless": true, //是否启用无头模式
"requestId": "全局唯一标识"
}
3、响应结果:
{
"statusCode": "状态码",
"err": "异常信息",
"action": "getBrowserEnvInfo",
"browserOauth": "店铺ID",
"requestId": "全局唯一标识",
"browserPath": "内核exe所在位置",
"launcherPage": "店铺所属平台的默认启动页面",
"browserArguments": "启动必要参数",
"debuggingPort": "调试端口"
}
4、启动Selenium 必要参数
//根据getBrowserEnvInfo 返回结果启动Selenium
ChromeOptions options = new ChromeOptions();
//内核exe所在位置
options.addArguments(browserArguments);
//启动必要参数
options.setBinary(browserPath);
//调试端口
options.addArguments("--remote-debugging-port=" + debuggingPort);
5、状态码:参考Action : startBrowser
(五)Action : heartbeat
1、说明:非必要接口,只是用于保活Socket连接
2、请求参数
{
"userInfo": "{\"company\":\"公司\",\"username\":\"用户名\",\"password\":\"密码\"}",
"action": "heartbeat",
"requestId": "全局唯一标识"
}
3、响应结果:
{
"statusCode": "状态码",
"err": "异常信息",
"action": "heartbeat",
"requestId": "全局唯一标识"
}
4、状态码:
(1) 0 : 成功
(2)-10000 : 未知异常
(3)-10002 : Socket参数非法
(4)-10003 : 登录失败
def heartbeat(self):
"""维持心跳"""
self.utils.sleep_message(10, "维持心跳")
heartbeat_params = self.browser_api(self.__HEARTBEAT)
heartbeat_obj = self.socket_communication(heartbeat_params)
logger.info("心跳信息: %s" % heartbeat_obj)
(六)Action : exit
1、说明:正常退出超级浏览器主进程,会自动关闭已启动python教程店铺并保持店铺cookie等信息。
2、请求参数:
{
"userInfo": "{\"company\":\"公司\",\"username\":\"用户名\",\"password\":\"密码\"}",
"action": "exit",
"requestId": "全局唯一标识"
}
3、响应码:
4、状态码:
(1) 0 : 成功
(2)-10000 : 未知异常
(3)-10002 : Socket参数非法
(4)-10003 : 登陆失败
def exit_browser(self):
self.utils.sleep_message(10, "退出浏览器 .....")
# 退出浏览器
exit_params = self.browser_api(self.__EXIT)
logger.info("退出浏览器: %s" % exit_params)
self.socket_communication(exit_params)
# 杀死浏览器进程
# self.kill_browser()
# ------------------------>> 钉钉通知公共参数 start
title = "紫鸟·超级浏览器·退出" # 悬浮标题
iphone = self.config.get('ding_talk_iphone') # @的指定人
spider_name = self.config.get('sn_v_shipment_status') # 应用名称
curr_time = Utility.curr_time() # 当前时间
cloud_server = self.config.get('cloud_server_name') # 云服务器名称
# ------------------------>> 钉钉通知公共参数 end
inform_content = "##### 紫鸟·超级浏览器·退出*>应用名称: {}*> 服务器: {}*>当前时间: {}*>" \
"<font color=#00DD00 size=3 face='隶书'>采集任务已完成,浏览器正常退出.</font>*>" \
.format(spider_name, cloud_server, curr_time).replace('*', '\n\n')
Utility.ding_talk_robot(1, title, inform_content, [iphone], False)
五、getBrowserList中的SiteId说明
| index | id | name |
|---|---|---|
| 1 | 1 | 🇺🇸 美国亚马逊 |
| 2 | 2 | 🇨🇦 加拿大亚马逊 |
| 3 | 3 | 🇯🇵 日本亚马逊 |
| 4 | 4 | 🇬🇧 英国亚马逊 |
| 5 | 5 | 🇫🇷 法国亚马逊 |
| 6 | 7 | 🇮🇹 意大利亚马逊 |
| 7 | 10 | 🇩🇪 德国亚马逊 |
| 8 | 11 | 🇪🇸 西班牙亚马逊 |
写得有问题的地方还望各位大佬指出错误,谢谢。

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









