





最近为了考试打算抓取网上的软考试题,在抓取中遇到一些问题,下面这篇文章主要介绍的是利用python爬取软考试题之ip自动代理的相关资料,文中介绍的非常详细,需要的朋友们下面来一起看看吧。
Python客栈送红包、纸质书
前言
最近有个软件专业等级考试,以下简称软考,为了更好的复习备考,我打算抓取www.rkpass.cn网上的软考试题。
首先讲述一下我爬取软考试题的故(keng)事(shi)。现在我已经能自动抓取某一个模块的所有题目了,如下图:
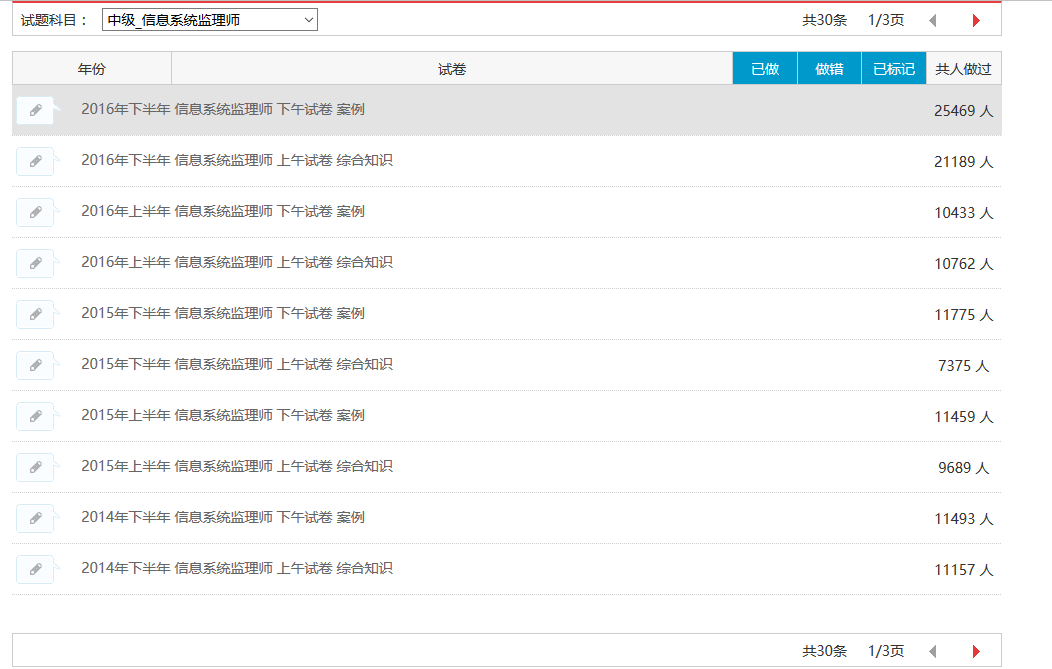
目前可以将信息系统监理师的30条试题记录全部抓取下来,结果如下图所示:
抓取下来的内容图片:

虽然可以将部分信息抓取下来,但是代码的质量并不高,以抓取信息系统监理师为例,因为目标明确,各项参数清晰,为了追求能在短时间内抓取到试卷信息,所以并没有做异常处理,昨天晚上填了很久的坑。
回到主题,今天写这篇博客,是因为又遇到新坑了。从文中标题我们可以猜出个大概,肯定是请求次数过多,所以ip被网站的反爬虫机制给封了。
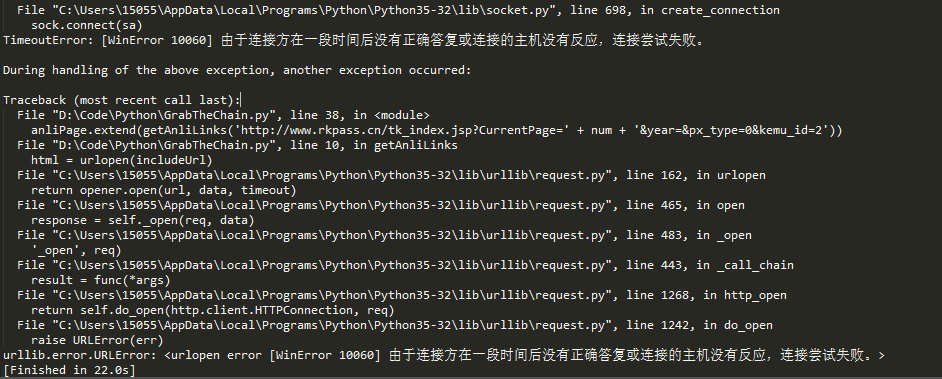
活人不能让尿憋死,革命先辈的事迹告诉我们,作为社会主义的接班人,我们不能屈服于困难,逢山开路,遇水搭桥,为了解决ip问题,ip代理这个思路就出来了。
在网络爬虫抓取信息的过程中,如果抓取频率高过了网站的设置阀值,将会被禁止访问。通常,网站的反爬虫机制都是依据IP来标识爬虫的。
于是在爬虫的开发者通常需要采取两种手段来解决这个问题:
1、放慢抓取速度,减小对于目标网站造成的压力。但是这样会减少单位时间类的抓取量。
2、第二种方法是通过设置代理IP等手段,突破反爬虫机制继续高频率抓取。但是这样需要多个稳定的代理IP。
话不多书,直接上代码:
运行结果截图:
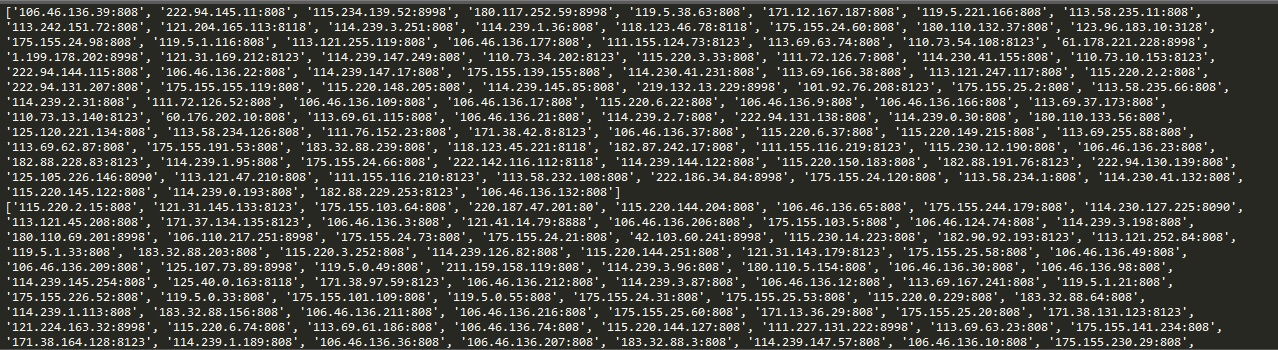
这样,在爬虫请求的时候,把请求ip设置为自动ip,就能有效的躲过反爬虫机制中简单的封锁固定ip这个手段。
为了网站的稳定,爬虫的速度大家还是控制下,毕竟站长也都不容易。本文测试只抓取了17页ip。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家学习或者使用python能带来一定的帮助,如果有疑问大家可以留言交流vb.net教程C#教程python教程SQL教程access 2010教程xin3721自学网















 2319
2319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









