









1 Storm概览
如果只用一句话来描述storm的话,可能会是这样:分布式实时计算系统。按照storm作者的说法,storm对于实时计算的意义类似于hadoop对于批处理的意义。我们都知道,根据google mapreduce来实现的hadoop为我们提供了map, reduce原语,使我们的批处理程序变得非常地简单和优美。同样,storm也为实时计算提供了一些简单优美的原语。
2 Storm架构
2.1 Storm的基本概念
首先我们通过一个 storm 和hadoop的对比来了解storm中的基本概念。
| Hadoop | Storm | |
| 系统角色 | JobTracker | Nimbus |
| TaskTracker | Supervisor | |
| Child | Worker | |
| 应用名称 | Job | Topology |
| 组件接口 | Mapper/Reducer | Spout/Bolt |
表3-1
接下来我们再来具体看一下这些概念。
- Nimbus:负责资源分配和任务调度。
- Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。
- Worker:运行具体处理组件逻辑的进程。
- Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,同一个spout/bolt的task可能会共享一个物理线程,该线程称为executor。
下面这个图描述了以上几个角色之间的关系。
- Topology:storm中运行的一个实时应用程序,因为各个组件间的消息流动形成逻辑上的一个拓扑结构。
- Spout:在一个topology中产生源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源 数据。Spout是一个主动的角色,其接口中有个nextTuple()函数,storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
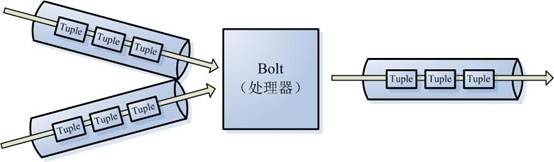
- Bolt:在一个topology中接受数据然后执行处理的组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被 动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作。
- Tuple:一次消息传递的基本单元。本来应该是一个key-value的map,但是由于各个组件间传递的tuple的字段名称已经事先定义好,所以tuple中只要按序填入各个value就行了,所以就是一个value list.
- Stream:源源不断传递的tuple就组成了stream。
10. stream grouping:即消息的partition方法。Storm中提供若干种实用的grouping方式,包括shuffle, fields hash, all, global, none, direct和localOrShuffle等
相比于s4, puma等其他实时计算系统,storm最大的亮点在于其记录级容错和能够保证消息精确处理的事务功能。下面就重点来看一下这两个亮点的实现原理。
2.2 storm的三大作用领域
1) 信息流处理(Stream Processing)
Storm可以用来实时处理新数据和更新数据库,兼具容错性和可扩展性。
2) 连续计算(Continuous Computation)
Storm可以进行连续查询并把结果即时反馈给客户,比如将Twitter上的热门话题发送到客户端。
3) 分布式远程过程调用(Distributed RPC)
Storm可以用来并行处理密集查询,Storm的拓扑结构(后文会介绍)是一个等待调用信息的分布函数,当它收到一条调用信息后,会对查
询进行计算,并返回查询结果。
2.3 Storm的设计思想
在Storm中也有对于流stream的抽象,流是一个不间断的无界的连续tuple,注意Storm在建模事件流时,把流中的事件抽象为tuple即元组,后面会解释storm中如何使用tuple。
Storm认为每个stream都有一个stream源,也就是原始元组的源头,所以它将这个源头抽象为spout,spout可能是连接twitterapi并不断发出tweets,也可能是从某个队列中不断读取队列元素并装配为tuple发射。
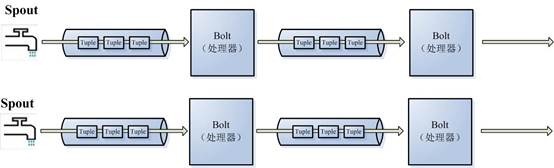
有了源头即spout也就是有了stream,那么该如何处理stream内的tuple呢,同样的思想twitter将流的中间状态转换抽象为Bolt,bolt可以消费任意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的 spout(管口)再将spout中流出的tuple导向特定的bolt,又bolt对导入的流做处理后再导向其他bolt或者目的地。
我们可以认为spout就是一个一个的水龙头,并且每个水龙头里流出的水是不同的,我们想拿到哪种水就拧开哪个水龙头,然后使用管道将水龙头的水导向到一个水处理器(bolt),水处理器处理后再使用管道导向另一个处理器或者存入容器中。
为了增大水处理效率,我们很自然就想到在同个水源处接上多个水龙头并使用多个水处理器,这样就可以提高效率。没错Storm就是这样设计的,看到下图我们就明白了。
对应上文的介绍,我们可以很容易的理解这幅图,这是一张有向无环图,Storm将这个图抽象为Topology即拓扑(的确,拓扑结构是有向无环的),拓 扑是storm中最高层次的一个抽象概念,它可以被提交到storm集群执行,一个拓扑就是一个流转换图,图中每个节点是一个spout或者bolt,图 中的边表示bolt订阅了哪些流,当spout或者bolt发送元组到流时,它就发送元组到每个订阅了该流的bolt(这就意味着不需要我们手工拉管道, 只要预先订阅,spout就会将流发到适当bolt上)。
插个位置说下storm的topology实现,为了做实时计算,我们需要设计一个拓扑图,并实现其中的Bolt处理细节,Storm中拓扑定义仅仅是一些Thrift结构体(请google一下Thrift),这样一来我们就可以使用其他语言来创建和提交拓扑。
上篇文章说过S4中PE间的事件传递是以一种(K,A)的元素传递,Storm则将流中元素抽象为tuple,一个tuple就是一个值列表value list,list中的每个value都有一个name,并且该value可以是基本类型,字符类型,字节数组等,当然也可以是其他可序列化的类型。
拓扑的每个节点都要说明它所发射出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
说到这里,Storm的核心实时处理思想就说完了,不过既然Storm要能发挥实时处理的能力就必须要由良好的架构设计和部署设计,接下来是Storm的集群部署设计,这里Storm的官方介绍得很清楚了,我就直接copy过来,再做一点分析。
Storm集群表面类似Hadoop集群。但在Hadoop上你运行的是”MapReduce jobs”,在Storm上你运行的是”topologies”。”Jobs”和”topologies”是大不同的,一个关键不同是一个 MapReduce的Job最终会结束,而一个topology永远处理消息(或直到你kill它)。
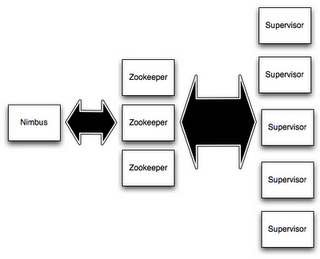
Storm集群有两种节点:控制(master)节点和工作者(worker)节点。
控制节点运行一个称之为”nimbus”的后台程序,它类似于Haddop的”JobTracker”。Nimbus负责在集群范围内分发代码、为worker分配任务和故障监测。
每个工作者节点运行一个称之”Supervisor”的后台程序。Supervisor监听分配给它所在机器的工作,基于Nimbus分配给它的事情来决 定启动或停止工作者进程。每个工作者进程执行一个topology的子集(也就是一个子拓扑结构);一个运行中的topology由许多跨多个机器的工作 者进程组成。
一个Zookeeper集群负责Nimbus和多个Supervisor之间的所有协调工作(一个完整的拓扑可能被分为多个子拓扑并由多个supervisor完成)。
此外,Nimbus后台程序和Supervisor后台程序都是快速失败(fail-fast)和无状态的;所有状态维持在Zookeeper 或本地磁盘。这意味着你可以kill -9杀掉nimbus进程和supervisor进程,然后重启,它们将恢复状态并继续工作,就像什么也没发生。这种设计使storm极其稳定。这种设计 中Master并没有直接和worker通信,而是借助一个中介Zookeeper,这样一来可以分离master和worker的依赖,将状态信息存放 在zookeeper集群内以快速回复任何失败的一方。
2.4 Storm记录级容错的基本原理
首先来看一下什么叫做记录级容错?storm允许用户在spout中发射一个新的源tuple时为其指定一个message id, 这个message id可以是任意的object对象。多个源tuple可以共用一个message id,表示这多个源 tuple对用户来说是同一个消息单元。storm中记录级容错的意思是说,storm会告知用户每一个消息单元是否在指定时间内被完全处理了。那什么叫 做完全处理呢,就是该message id绑定的源tuple及由该源tuple后续生成的tuple经过了topology中每一个应该到达的bolt的处理。举个例子。在图4-1中,在 spout由message 1绑定的tuple1和tuple2经过了bolt1和bolt2的处理生成两个新的tuple,并最终都流向了bolt3。当这个过程完成处理完时,称 message 1被完全处理了。
图4-1
在storm的topology中有一个系统级组件,叫做acker。这个acker的任务就是追踪从spout中流出来的每一个message id绑定的若干tuple的处理路径,如果在用户设置的最大超时时间内这些tuple没有被完全处理,那么acker就会告知spout该消息处理失败 了,相反则会告知spout该消息处理成功了。在刚才的描述中,我们提到了”记录tuple的处理路径”,如果曾经尝试过这么做的同学可以仔细地思考一下这件事的复杂程度。但是storm中却是使用了一种非常巧妙的方法做到了。在说明这个方法之前,我们来复习一个数学定理。
A xor A = 0.
A xor B…xor B xor A = 0,其中每一个操作数出现且仅出现两次。
storm中使用的巧妙方法就是基于这个定理。具体过程是这样的:在spout中系统会为用户指定的message id生成一个对应的64位整数,作为一个root id。root id会传递给acker及后续的bolt作为该消息单元的唯一标识。同时无论是spout还是bolt每次新生成一个tuple的时候,都会赋予该 tuple一个64位的整数的id。Spout发射完某个message id对应的源tuple之后,会告知acker自己发射的root id及生成的那些源tuple的id。而bolt呢,每次接受到一个输入tuple处理完之后,也会告知acker自己处理的输入tuple的id及新生成的那些tuple的id。Acker只需要对这些id做一个简单的异或运算,就能判断出该root id对应的消息单元是否处理完成了。下面通过一个图示来说明这个过程。
图4-1 spout中绑定message1生成了两个源tuple,id分别是0010和1011.
图4-2 bolt1处理tuple0010时生成了一个新的tuple,id为0110.
图4-3 bolt2处理tuple1011时生成了一个新的tuple,id为0111.
图4-4 bolt3中接收到tuple0110和tuple 0111,没有生成新的tuple.
容错过程存在一个可能出错的地方,那就是,如果生成的tuple id并不是完全各异的,acker可能会在消息单元完全处理完成之前就错误的计算为0。这个错误在理论上的确是存在的,但是在实际中其概率是极低极低的,完全可以忽略。
2.5 stream grouping分类
1. Shuffle Grouping: 随机分组, 随机派发stream里面的tuple, 保证每个bolt接收到的tuple数目相同.
2. Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts,而不同的userid则会被分配到不同的Bolts.
3. All Grouping:广播发送, 对于每一个tuple, 所有的Bolts都会收到.
4. Global Grouping: 全局分组,这个tuple被分配到storm中的一个bolt的其中一个task.再具体一点就是分配给id值最低的那个task.
5. Non Grouping: 不分组,意思是说stream不关心到底谁会收到它的tuple.目前他和Shuffle grouping是一样的效果,有点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程去执行.
6. Direct Grouping: 直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者举鼎由消息接收者的哪个task处理这个消息.只有被声明为Direct Stream的消息流可以声明这种分组方法.而且这种消息tuple必须使用emitDirect方法来发射.消息处理者可以通过 TopologyContext来或者处理它的消息的taskid (OutputCollector.emit方法也会返回taskid)
3 Storm安装
3.1安装zeromq
下载安装zeromq http://download.zeromq.org/zeromq-2.1.10.tar.gz
$ yum install gcc
$ yum install gcc-c++
$ yum install make
$ yum install uuid-devel
$ yum install libuuid-devel
$ yum install e2fsprogs-devel
$ cd zeromq-2.1.10
$ ./configure
$ make
$ make install
3.2安装JZMQ
下载jzmq.zip https://github.com/nathanmarz/jzmq
$ git clone https://github.com/zeromq/jzmq.git
$ cd bin
$ ./autogen.sh
$ ./configure
$ make
$ make install
3.3安装Storm
下载
https://github.com/downloads/nathanmarz/storm/storm-0.7.4.zip
$ unzip storm-0.7.4.zip4 Storm配置
配置说明:192.168.0.29:nimbus supervisor
192.168.0.30: supervisor
Storm集群需要zookeeper集群的支持所以应该先安装zookeeper集群。再配置storm集群,下面是storm集群的配置:
192.168.0.29上的配置
a) 下载storm-0.7.4.zip https://github.com/nathanmarz/storm/downloads
b) 解压后修改conf/storm.yaml文件,
storm.zookeeper.servers:
- "192.168.0.29"
配置好以后到bin目录下:
./storm nimbus 启动storm主节点服务
./storm supervisor
./storm ui 启动storm监控页面:监控地址:http://hostname:8080

192.168.0.30上的配置
1,修改storm.yaml 文件:
storm.zookeeper.servers:
- "192.168.0.29"
nimbus.host: "192.168.0.29"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
2,启动supervisor
./storm supervisor
5 Storm常见模式
列举出了stormtopology里面的一些常见模式:
1) 流聚合(stream join)
流聚合把两个或者多个数据流聚合成一个数据流 — 基于一些共同的tuple字段。流聚合和SQL里面table join很像,只是tablejoin有有限的输入,并且join的语义是非常明确的。而流聚合的语义是不明确的并且输入流是无限的。
流类型的聚合类型跟具体的应用就有关了。一些应用把两个流发出的所有的tuple都聚合起来 — 不管多长时间;而另外一些应用则只会聚合一些特定的tuple。而另外一些应用的聚合逻辑又可能完全不一样。而这些聚合类型里面最常见的类型是把所有的输入流进行一样的划分, 这个在storm里面用fields grouping在相同字段上进行grouping就可以了,比如:
builder.setBolt(5, new MyJoiner(), parallelism)
.fieldsGrouping(1, new Fields(“joinfield1″, “joinfield2″))
.fieldsGrouping(2, new Fields(“joinfield1″, “joinfield2″))
.fieldsGrouping(3, new Fields(“joinfield1″, “joinfield2″));
当然,不同的数据流的“相同”字段不需要有一样的名字。
2) 批处理(Batching)
有时候为了性能或者一些别的原因, 你可能想把一组tuple一起处理,而不是一个个单独处理。比如,你可能想批量更新数据库。
如果你想在你的数据处理具有可靠性,正确的方式是保存这些tuple对象的引用知道bolt批量处理这些tuple了。一旦你开始这个批量操作的时候, 你可以批量的ack这些tuple。
如果一个bolt发射tuple, 那么你可能想用multi-anchoring来保证可靠性。这一切都取决于具体的应用。关于storm的消息传递的工作原理可以看这篇:Twitter Storm如何保证消息不丢失。
3) BasicBolt
很多bolt有些类似的模式:
1) 读一个输入tuple
2) 根据这个输入tuple发射一个或者多个tuple
3) 在execute的方法的最后ack那个输入tuple
遵循这类模式的bolt一般是函数或者是过滤器, 这种模式太常见,storm为这类模式单独封装了一个接口: IBasicBolt。更多的信息请看: Twitter Storm如何保证消息不丢失。
4) 内存内缓存 + fields grouping 组合
在bolt的内存里面缓存一些东西非常常见。缓存在和fieldsgrouping结合起来之后就更有用了。比如,你有一个bolt把短链接变成长链接(bit.ly, t.co之类的)。你可以把短链接到长链接的对应关系利用LRU算法缓存在内存里面以避免重复计算。比如组件一发射短链接,组件二把短链接转化成长链接并 缓存在内存里面。看一下下面两段代码有什么不一样:
builder.setBolt(2, new ExpandUrl(), parallelism)
.shuffleGrouping(1);
builder.setBolt(2, new ExpandUrl(), parallelism)
.fieldsGrouping(1, new Fields(“url”));
第二种方式的缓存会比第一种方式的缓存的效率高很多,因为同样的短链接始终被发到同一个task。这会避免不同的机器上有同样的缓存 — 浪费内存, 同时也使得同样的短域名更可能在内存里面找到缓存。
5)计算top N
storm的一个常见的持续计算的模式叫做叫做: “streaming top N”。
比如你有一个bolt发射这样的tuple:["value", "count"]并且你想一个bolt基于这些信息算出top N的tuple。最简单的办法是有一个bolt可以做一个全局的grouping的动作并且在内存里面保持这top N的值。
这个方式对于大数据量的流显然是没有扩展性的, 因为所有的数据会被发到同一台机器。一个更好的方法是在多台机器上面并行的计算这个流每一部分的top N, 然后再有一个bolt合并这些机器上面所算出来的top N以算出最后的top N, 代码大概是这样的:
builder.setBolt(2, new RankObjects(), parallellism)
.fieldsGrouping(1, new Fields(“value”));
builder.setBolt(3, new MergeObjects())
.globalGrouping(2);
这个模式之所以可以成功是因为第一个bolt的fieldsgrouping使得这种并行算法在语义上是正确的。
6) 用TimeCacheMap来高效地保存一个最近被更新的对象的缓存
有时候你想在内存里面保存一些最近活跃的对象,以及那些不再活跃的对象。TimeCacheMap是一个非常高效的数据结构,它提供了一些callback函数使得我们在对象不再活跃的时候我们可以做一些事情。
7) 分布式RPC: CoordinatedBolt和KeyedFairBolt
用storm做分布式RPC应用的时候有两种比较常见的模式:它们被封装在 CoordinatedBolt和KeyedFairBolt里面。
CoordinatedBolt包装你的bolt,并且确定什么时候你的bolt已经接收到所有的tuple。它主要使用Direct Stream来做这个。
KeyedFairBolt同样包装你的bolt并且保证你的topology同时处理多个DRPC调用,而不是串行地一次只执行一个。
6 Storm集群模式测试
6.1代码
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new TestWordSpout2(), 1);
builder.setBolt("Bolt1", new ExclamationBoltTest(), 3)
.shuffleGrouping("words");
builder.setBolt("Bolt2", new ExclamationBoltTest(), 2)
.shuffleGrouping("Bolt1");
Config conf = new Config();
conf.setDebug(true);
conf.setNumWorkers(2);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
Utils.sleep(100);
_collector.emit(newValues(“word”)); 6.2集群环境运行
$storm jar testStorm2.jar test.ExclamationBoltTest StormWorld6.3 ui

6.4 Result
$cd /home/storm/storm-0.7.4/logs
$tail -f worker-6700.log
…
2012-12-25 17:39:49 task [INFO] Emitting: Bolt1 default [word!!!]
2012-12-25 17:39:49 task [INFO] Emitting: Bolt1 default [word!!!]
2012-12-25 17:39:49 task [INFO] Emitting: Bolt2 default [word!!!!!!]
2012-12-25 17:39:49 task [INFO] Emitting: Bolt2 default [word!!!!!!]
2012-12-25 17:39:49 task [INFO] Emitting: Bolt1 default [word!!!]
2012-12-25 17:39:49 task [INFO] Emitting: Bolt2 default [word!!!!!!]
2012-12-25 17:39:49 task [INFO] Emitting: Bolt1 default [word!!!]
2012-12-25 17:39:50 task [INFO] Emitting: Bolt1 default [word!!!]















 470
470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}