






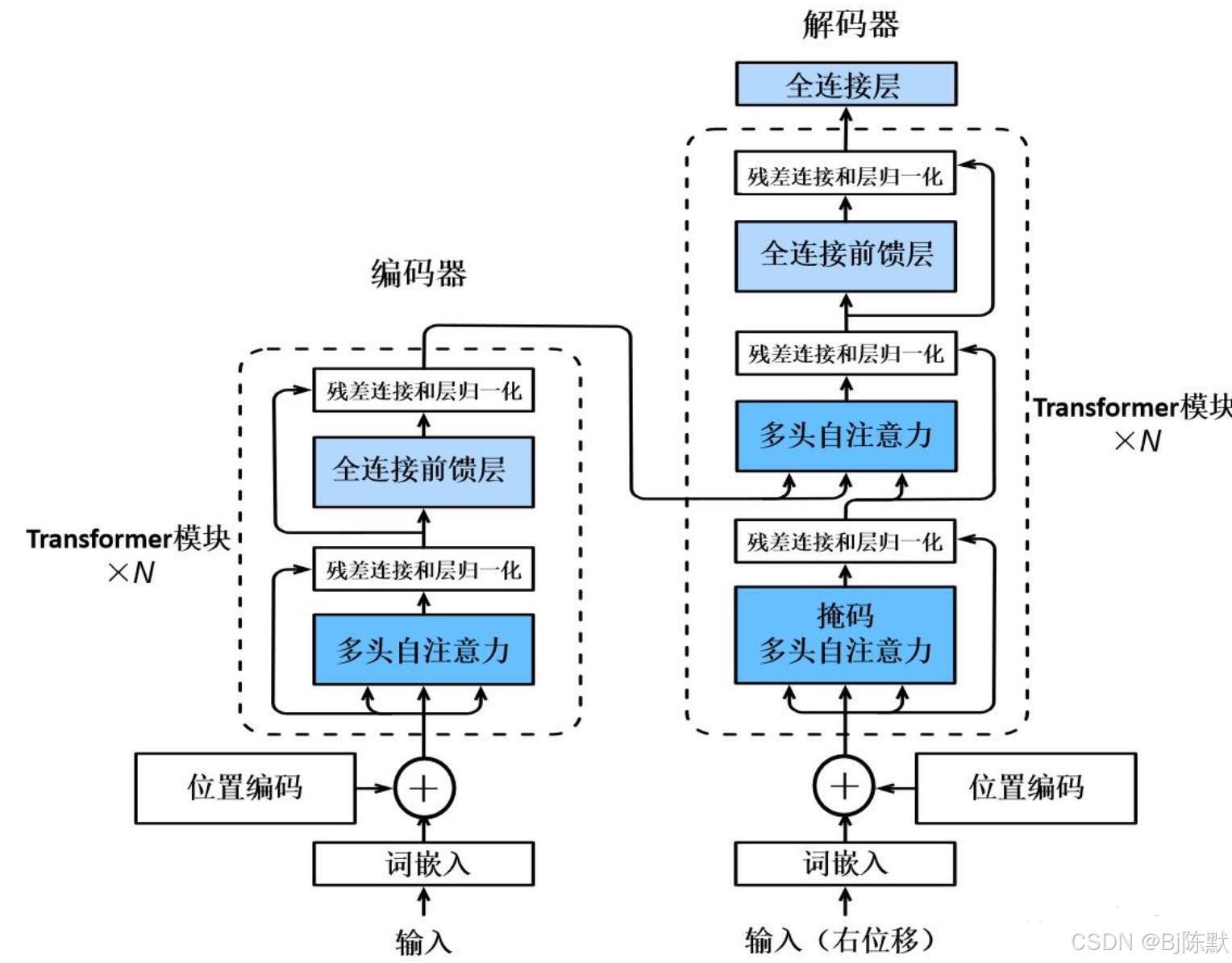
基于Transformer的大模型在开发中处于主导地位,主要原因如下:
1. 技术优势
强大的长程依赖捕捉能力:核心的自注意力机制允许模型在处理每个输入时,关注输入序列的不同部分,计算查询向量与键向量之间的相似度,确定每个输入位置对其他位置的重要性,据此生成值向量的加权和作为输出,能直接关联任意长度距离的信息片段。比如在处理长篇小说、复杂技术文档等长文本时,能很好地理解上下文语义关联,这是传统的循环神经网络(RNN)和卷积神经网络(CNN)难以做到的。RNN会随着序列长度增加而逐渐忘记较旧的信息,CNN只能使用靠近每个令牌的信息。
并行计算能力:可以在输入序列中的所有令牌上并行执行,与RNN顺序处理令牌不同,大大提高了训练和部署速度,能够更快地为用户提供响应,显著提升了相对于RNNs的效率,充分利用现代GPU等并行计算设备的性能,减少训练和推理时间。
良好的可扩展性:研究人员可以不断增加Transformer的规模和用于训练的数据量,模型越大,其理解和生成的文本就越复杂和细致。而且,扩大Transformer的规模,比如从10亿参数扩大到100亿参数,并不会显著增加所需的时间,使得开发人员可以根据任务需求和资源情况,灵活地调整模型规模以获得更好的性能。
2. 性能表现
在各种任务中表现卓越:在自然语言处理的众多任务上,如机器翻译、文本摘要、文本生成、问答系统等,基于Transformer的大模型都取得了显著的成果和突破性的性能提升。在机器翻译中,能够学习到不同语言之间更准确的映射关系,实现高质量的翻译;在文本生成中,能生成更符合语义和逻辑、更具连贯性的文本。
泛化能力强:通过在大规模语料上进行预训练,然后在特定任务上进行微调,基于Transformer的大模型能够很好地适应各种不同领域和类型的任务,具有较强的泛化能力,减少了针对每个具体任务单独设计复杂模型的需求。
3. 架构灵活性:不同的应用场景可以通过调整特定组件来适应需求,比如添加更多的层数、改变头的数量或是修改激活函数等细节设置,还可以方便地与其他技术和模型结构进行融合和结合,进一步拓展其应用范围和功能。
4. 社区支持与工具链完善:自2017年被提出以来,Transformer及其衍生物迅速获得了广泛的社区兴趣和支持。如今有许多成熟的框架和库可供开发者使用,如Hugging Face提供的Transformers库,包含了大量预先训练好的模型供人们下载和定制,简化了实验和部署的过程,降低了开发门槛,加速了基于Transformer的大模型的开发和应用速度。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











