






一、概念
- 分布式消息传递
- 网站活跃数据跟踪
- 日志聚合
- 流式数据处理
- 数据存储
- 事件
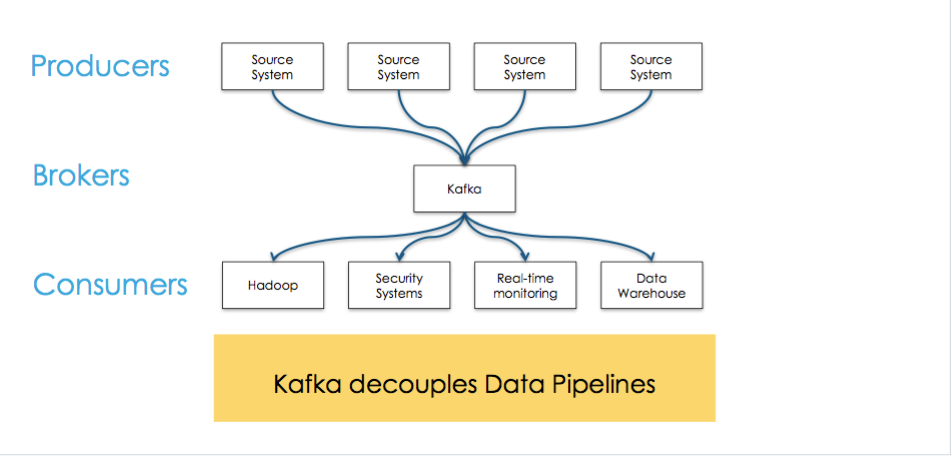
二、术语
Topics
消息都归属于一个类别成为topic,在物理上不同topic的消息分开存储,逻辑上一个Topic的消磁对使用者透明
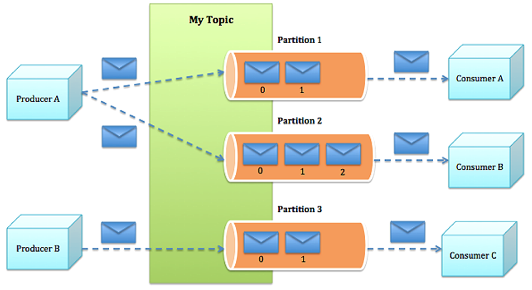
partions
每个Topics划分一个或者多个Partion,并且Partion中的每条消息都被标记了一个sequential id,也就是offset,并且存储的数据是可以配置存储空间的
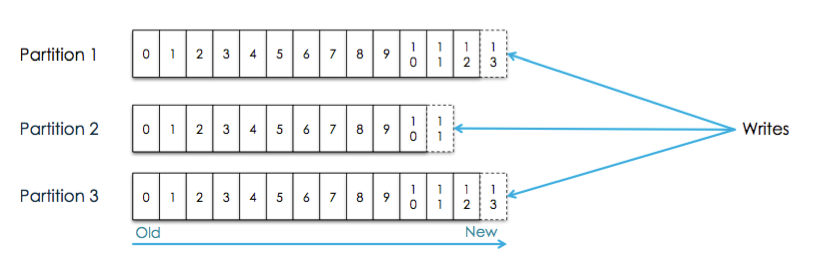
Message Ordering
消息只能保证在同一个Partion中有序,如果要保证从Topic中拿到数据有序,则需要做到:
Group messages in a partition by key(producer)
按键(生产者)分组分区中的消息
Configure exactly one consumer instance per partition within a consumer group
在一个使用者组中,每个分区精确地配置一个使用者实例
Log
Partion对应逻辑上的Log
Replication 副本
Topics can (and should) be replicated
The unit of replication is the partition
Each partition in a topic has 1 leader and 0 or more replicas
A replica is deemed to be “in-sync” if
The replica can communicate with Zookeeper
The replica is not “too far” behind the leader(configurable)
The group of in-sync replicas for a partition is called the ISR(In-Sync-Replicas)
The Replication factor cannot be lowered
kafaka durability 可靠性
Durability can be configured with the producer configuration request.required.acks
0 : The producer never waits for an ack
1 : The producer gets an ack after the leader replica has received the data
-1 : The producer gets an ack after all ISRs receive the data

Broker
Kafka is run as a cluster comparised of one or more servers each of which is called broker 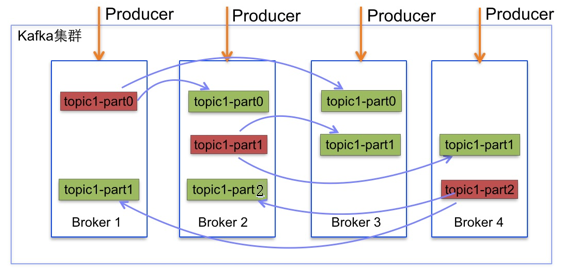
Producer
ISR(in-sync-replicas)同步副本,一般指的是集群
Producers publish to a topic of their choosing(push)
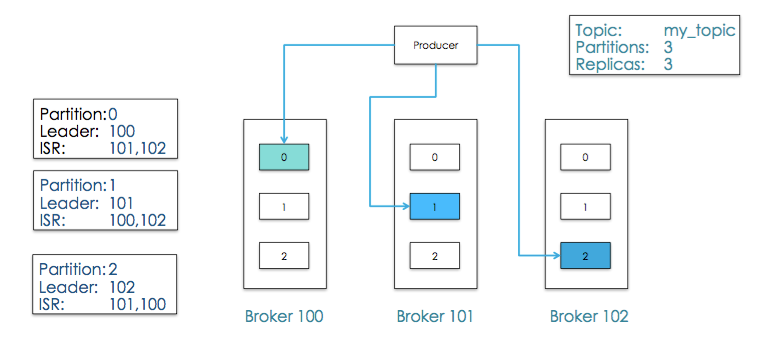
数据载入kafka可以是分布式的,通常是通过”Round-Robin”(循环)算法策略,也可以根据message中的key来进行语义分割”semantic partitioning”来分布式载入,Brokers 通过分区来均衡载入
kafka支持异步发送async,异步发送消息是less durable的,但是是高吞吐的
Producer的载入平衡和ISRs
Consumer
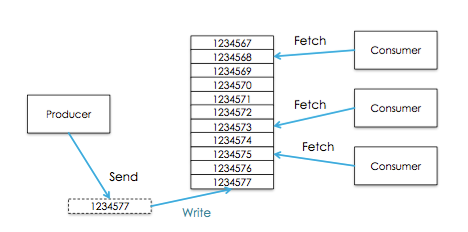
Multiple Consumer can read from the same topic
多个消费者可以从同一个topic读取消息
Each Consumer is responsible for managing it’s own offset
每个消费者负责管理自己的offset
Message stay on kafka… they are not removed after they consumed
kafka上的消息,他们再消费后不会被移除
Consumer可以从任一地方开始消费,然后又回到最大偏移量处,Consumers又可以被划分为Consumer Group
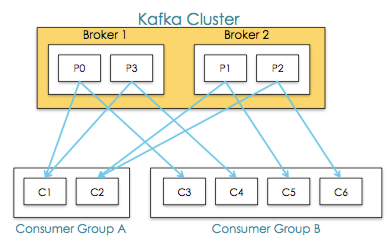
Consumner Group
Consumer Group 是显示分布式,多个Consumer构成组结构,Message只能传输给某个Group中的某一个Consumer
常用Consumer Group模式:
All consumer instances in one group
Acts like a traditional queue with load balancing
所有的消费者在同一个组,这其实是传统的队列模式
All consumer instances in different groups
All messages are broadcast to all consumer instances
所有消费者在不同组中,所有消息发送给所有的消费者实例
“Logical Subscriber” - Many consumer instances in a group
Consumers are added for scalability and fault tolerance,Each consumer instance reads from one or more partitions for a topic ,There cannot be more consumer instances than partitions
传统的订阅发布模式,很多消费者在一个组里,消费者为了提高可伸缩性和容错性,每个消费者实例从一个topic中一个或者多个分区中读取消息,每个组消费者不能比分区多,否则有的消费者得不到消息
Consumer Groups 提供了topics和partitions的隔离 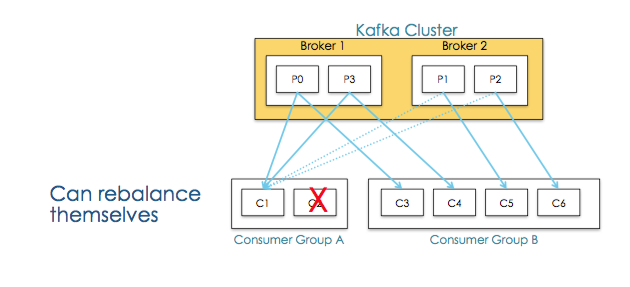
并且当某个Consumer挂掉后能够重新平衡
Consumer Group的应用场景
点对点
将所有消费者放到一个Consumer Group
广播
将每个消费者单独放到一个Consumer Group
水平扩展
向Consumer Group中添加消费者并进行Rebalance
故障转移
当某个Consumer发生故障时,Consumer Group重新分配分区
三、Kafka核心原理
Kafka设计思想
可持久化Message
持久化本地文件系统,设置有效期
支持高流量处理
面向特定的使用场景而不是通用功能
消费状态保存在消费端而不是服务端
减轻服务器负担和交互
支持分布式
生产者/消费者透明异步
依赖磁盘文件系统做消息缓存
不消耗内存
高效的磁盘存取
复杂度为O(1)
强调减少数据的序列化和拷贝开销
批量存储和发送、zero-copy
支持数据并行加载到Hadoop
集成Hadoop
kafka原理分析
partition
topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1 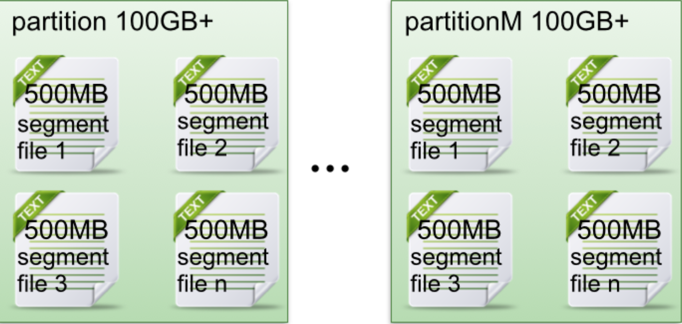
每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
segment file
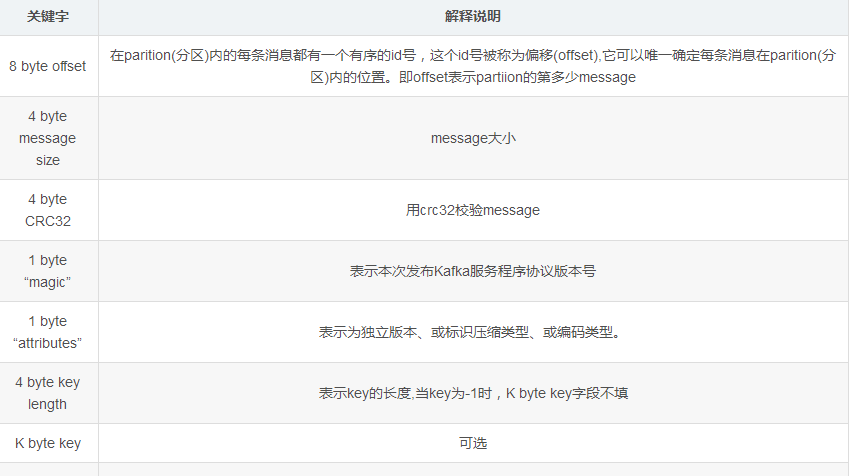
segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀”.index”和“.log”分别表示为segment索引文件、数据文件.
segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充

其中.index索引文件存储大量元数据,.log数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。他们两个是一一对应的,对应关系如下

Message
segment data file由许多message组成,message物理结构如下


Consumer
High Level Consumer
消费者保存消费状态:将从某个Partition读取的最后一条消息的offset存于ZooKeeper中
Low Level Consumer
更好的控制数据的消费
同一条消息读多次
只读取某个Topic的部分Partition
管理事务,从而确保每条消息被处理一次,且仅被处理一次
大量额外工作
必须在应用程序中跟踪offset,从而确定下一条应该消费哪条消息
应用程序需要通过程序获知每个Partition的Leader是谁
必须处理Leader的变化
消息传递语义Delivery Semantics
At least once
kafka的默认设置
Messages are never lost but maybe redelivered
At most once
Messages are lost but never redelivered
Exactly once
比较难实现
Messages are delivered once and only once
高可用性
同一个Partition可能会有多个Replica,需要保证同一个Partition的多个Replica之间的数据一致性
而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据
副本与高可用性:副本Leader Election算法
Zookeeper中的选举算法回顾
少数服从多数:确保集群中一半以上的机器得到同步
适合共享集群配置的系统中,而并不适合需要存储大量数据的系统,因为需要大量副本集。f个Replica失败情况下需要2f+1个副本
Kafka的做法
ISR(in-sync replicas),这个ISR里的所有副本都跟上了Leader,只有ISR里的成员才有被选为Leader的可能
在这种模式下,对于f+1个副本,一个Partition能在保证不丢失已经commit的消息的前提下容忍f个副本的失败
ISR需要的总的副本的个数几乎是“少数服从多数”的一半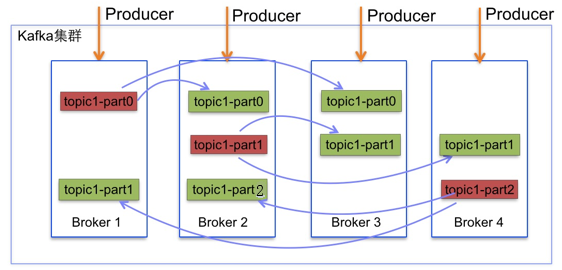
应用场景(Use Case)
Real-Time Stream Processing(combined with Spark Streaming)
实时流处理
General purpose Message Bus
通用信息总线
Collecting User Activity Data
收集用户动作数据
Collecting Operational Metrics from applications,servers or devices
从应用程序、服务器或者设备收集器操作指标
Log Aggregation
日志聚合
Change Data Capture
数据捕获
Commit Log for distributed systems
分布式系统提交日志
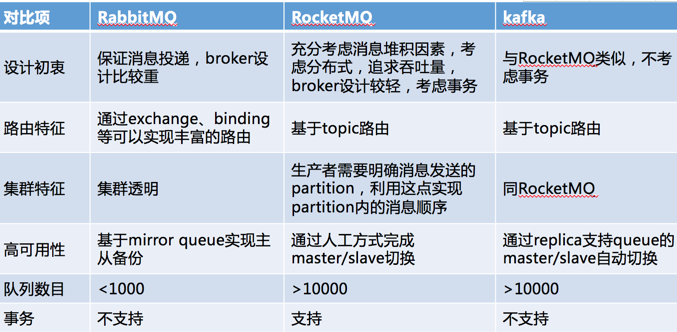
同类产品对比















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









