






 本文介绍了如何使用RAG技术改进GoogleCloudAI的CodeyAPI,通过结合外部数据增强模型,提高代码生成质量和代码完成的准确性。文章详细解释了RAG的工作原理,以及如何在实际应用中优化和使用,同时强调了负责任AI的实践和RAG的局限性。
本文介绍了如何使用RAG技术改进GoogleCloudAI的CodeyAPI,通过结合外部数据增强模型,提高代码生成质量和代码完成的准确性。文章详细解释了RAG的工作原理,以及如何在实际应用中优化和使用,同时强调了负责任AI的实践和RAG的局限性。
检索增强生成 (RAG) 是一种使用外部数据或信息来提高大型语言模型 (LLM) 准确性的方法。今天,我们将探讨如何使用 RAG 提高 Google Cloud AI 模型的输出质量,以便在 Vertex AI 上使用其 Codey API 完成和生成代码,这是一套代码生成模型,可以帮助软件开发人员更快地完成编码任务。有三个 Codey API 有助于提高开发人员的工作效率:
- 代码完成:根据您当前的上下文获取即时代码建议,使编码成为无缝且高效的体验。此 API 旨在集成到 IDE、编辑器和其他应用程序中,以便在编写代码时提供低延迟的代码自动完成建议。
- 代码生成:通过用自然语言描述所需的代码,在几秒钟内生成函数、类等的代码片段。当您需要快速编写大量代码或不确定如何开始时,此 API 会很有帮助。它可以集成到 IDE、编辑器和其他应用程序(包括 CI/CD 工作流)中。
- 代码聊天:在整个软件开发生命周期的编码之旅中获取帮助,从调试棘手的问题到通过有见地的建议和答案扩展您的知识。这个多轮次聊天 API 可以集成到 IDE 中,编辑器可以作为聊天助手集成。它还可用于批处理工作流。
这些模型还集成了负责任的 AI 功能,例如来源引用和毒性检查,这些功能会根据 Google 制定的负责任 AI 指南自动引用或阻止代码。
Codey API 提供的不仅仅是通用代码生成,它允许您根据组织的特定风格定制代码输出,并根据组织的准则安全地访问私有代码存储库。自定义这些模型的功能有助于生成符合既定编码标准和约定的代码,同时利用自定义终结点和专有代码库执行代码生成任务。
若要实现此级别的自定义,可以使用特定数据集(例如公司的代码库)优化模型。或者,您也可以利用 RAG 将外部知识源整合到代码生成过程中,我们现在将在下面详细讨论。
什么是RAG?
传统的大型语言模型受到其内部知识库的限制,这可能导致不相关或缺乏上下文的响应。RAG 通过将外部检索系统集成到 LLM 中来解决这个问题,使它们能够即时访问和利用相关信息。
这种技术允许 LLM 从权威的外部来源检索信息,使用相关上下文增强他们的输入,并生成更明智、更准确的响应。例如,代码生成模型可以使用 RAG 从现有代码存储库中获取相关信息,并使用它来创建准确的代码、文档,甚至修复代码错误。
RAG是如何工作的?
实施 RAG 需要一个强大的检索系统,该系统能够根据用户查询提供相关文档。
以下是 RAG 系统如何用于代码生成的快速概述:
- 检索机制从数据源获取相关信息。此信息可以采用代码、文本或其他类型的数据形式。
- 生成机制(即代码生成 LLM)使用检索到的信息来生成其输出。
- 生成的代码现在与输入查询或问题更相关。
虽然您可以采用各种方法,但最常见的 RAG 模式涉及为源信息块生成嵌入,并在向量数据库(如 Vertex AI Vector Search)中为它们编制索引。
下图显示了使用 Codey API 生成代码的高级 RAG 模式。
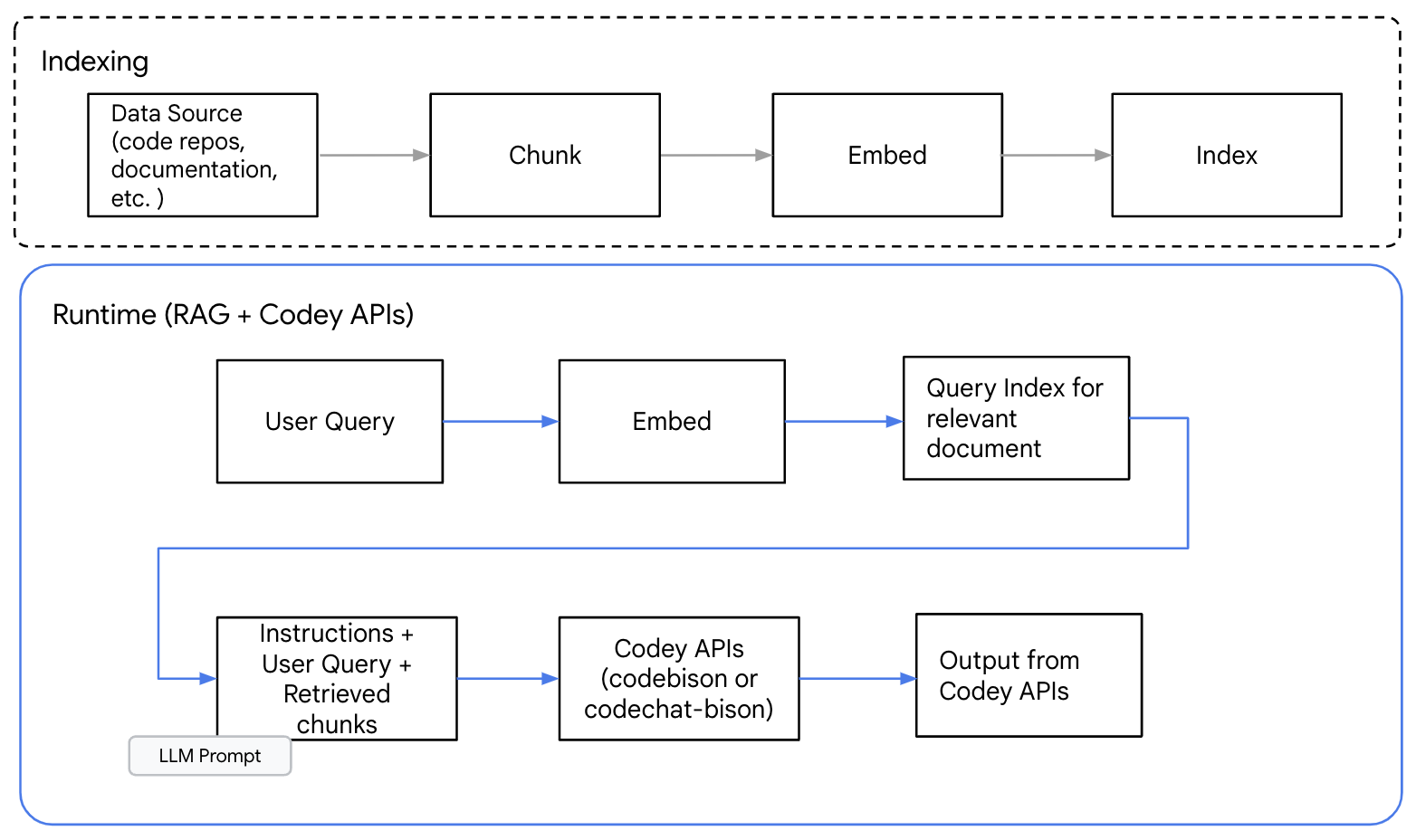
图 1:用于代码生成的 RAG 模式中的高级信息流
第一步是识别源信息。对于代码生成,这可以是 API 定义、代码存储库、文档或类似内容。接下来,您需要确定分块方案。分块信息允许您选择并仅提供解决查询所需的相关内容。
RAG 的最佳分块方法是保留文本生成所需的上下文信息的方法。对于代码,我们建议选择遵循自然代码边界(如函数、类或模块边界)的分块方法。随机拆分或句子中间/从句等技术可能会破坏上下文并降低您的输出。
从信息源创建信息块后,可以生成嵌入并在向量数据库中为它们编制索引。收到查询时,将为查询生成另一个嵌入,并用于帮助检索相关信息块。
从那里,提示、用户问题和相关信息块被发送到 Codey API 以生成响应。
将 RAG 与 Codey API 结合使用
现在我们了解了 RAG 是什么,让我们看看它是如何在 Vertex AI 中使用 Codey 模型生成代码的。
在本次演示中,我们使用了 Google Cloud 生成式 AI GitHub 存储库中的示例代码和 Jupyter 笔记本作为数据源。我们爬网了整个存储库,并列出了所有 Jupyter 笔记本。随后,我们分析了这些笔记本并提取了代码元素,然后在向量数据库中对其进行分块和索引。有关如何执行此操作的详细说明,可以按照以下笔记本中的步骤操作。
下面的示例显示了在不使用 RAG 添加外部上下文的情况下生成的对提示的响应。
提示:“创建 python 函数,该函数使用 langchain.llms 接口为 VertexAI 文本-野牛模型接受提示并进行预测”
不带 RAG 的输出:
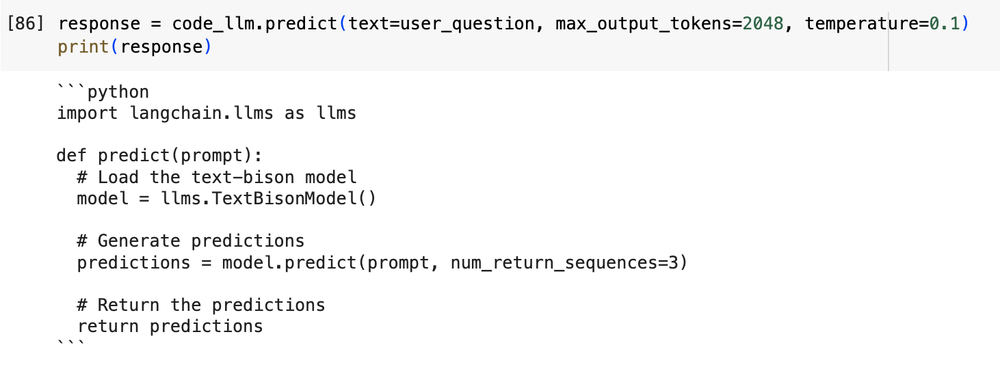
图 2:没有任何外部上下文的模型输出
在上面的例子中,LLM 没有 Langchain 库的预先知识。虽然响应可能看起来令人信服且连贯,但该模型实际上产生了幻觉并生成了代码,这些代码无法正确实例化文本野牛模型并调用 Predict 函数。
接下来,让我们尝试将 RAG 用于相同的提示。
RAG输出:
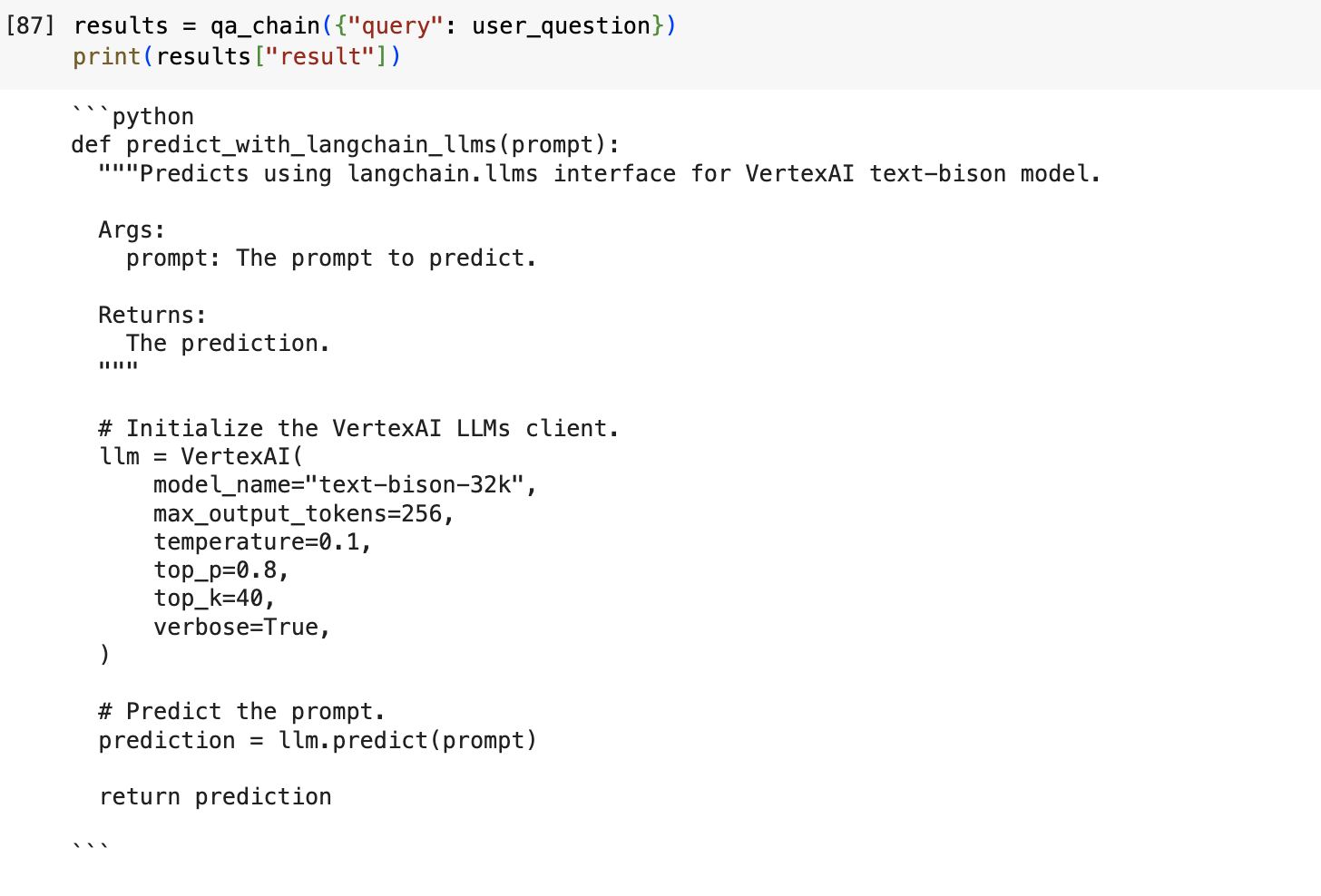
图 3:使用检索增强生成的输出
使用 RAG,Codey 能够从 Google Cloud Github 存储库动态注入代码,并提供使用正确语法的代码输出,这将允许 Vertex AI 文本野牛模型调用 Langchain API。
RAG 的常见用例和限制
虽然 RAG 可以成为提高 LLM 生成的代码和文本准确性的有用工具,但需要注意的是,RAG 并不是一个完美的解决方案。在某些情况下,RAG 可能会生成不准确或误导性的结果。这是因为 RAG 使用的知识库或其他外部来源可能不准确或不是最新的,或者 LLM 可能无法正确解释知识库中的信息。
考虑到这一点,我们建议在以下情况下将 RAG 与 Codey API 一起使用:
- 模型应该能够在受支持的语言中生成代码变体。例如,使用 RAG 探索不同的编码风格或使代码适应 SQL 的特定变体。
- 您需要用于生成代码的源的透明度和引用。
- 您的模型应该能够分析和学习最新的代码库,从而确保代码的新鲜度。
- 您需要一个对各种编码模式和细微差别有深刻理解的现有代码模型,以实现卓越的代码完成和有针对性的函数生成。
RAG 是微调的替代方案吗?
RAG 和监督优化是用于提高代码模型性能的两种不同技术。它们是具有独特优势和劣势的互补方法,可以一起使用。
例如,您可以首先使用监督调优在特定域或任务上调优 Codey 模型(例如 code-bison),然后使用 RAG 使用来自大型数据库的信息来增强模型的知识。若要了解有关微调模型的详细信息,请遵循此指南。
使用 RAG 的局限性
虽然 RAG 可以成为提高 LLM 生成的代码和文本的准确性和信息性的有用工具,但需要注意的是,RAG 并不是一个完美的解决方案。
在某些情况下,RAG 可能会生成不准确或误导性的结果。这是因为 RAG 使用的知识库或其他外部来源可能不准确或不是最新的,或者 LLM 可能无法正确解释知识库中的信息。
开始
要开始使用 Codey,您可以注册 Vertex AI 免费试用。拥有 Vertex AI 帐户后,您可以创建 Codey 实例并开始使用代码模型 API。
如果您需要矢量数据库,矢量搜索具有出色的性能、价格和行业领先的功能。如果您不使用代码片段并且更喜欢非结构化或结构化(表格)文档 RAG 搜索,Vertex AI Search 可以使整个过程变得简单。
参考:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









