







链表中的数据元素的地址是任意的。
连表示一组数据元素的集合,期中每个数据元素都是一个结点,结点的数据部分称为结点的数据域。为了能对整个链表惊醒遍历或访问,链表的每个节点至少还应该包含一个指向它的直接后继元素在物理内存中的位置信息(通常称为指针域)。一个结点也包含一个指向他的直接前趋元素在物理内存中的位置信息。一个链表的最后一个结点的指针域可以为空,整个链表的结束。
仅有前驱指针或后继指针的结点构成的链表称为单向链表,同时有前驱指针和后继指针的链表称为双向链表。在实际应用中,通常为整个链表增加一个头节点。此结点可以作为访问整个链表的入口,也可以作为遍历整个链表的结束标记。
1.单向链表及其运算
class Node
{
public :
int data
Node *next;
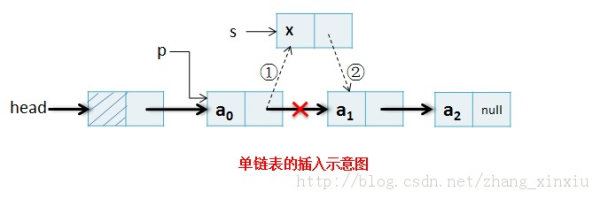
}node(1)插入操作
在第i个位置后插入一个新结点x的操作过程为首先产生新节点,然后修改相邻结点指针域的位置。
s.next=p.next;
p.next=s;//图片来源见水印
(2)删除操作
删除第i个结点的过程是首先确定要删除结点的位置,然后修改有关结点的指针域中的值。
p.next=s.next;//图片略(●’◡’●)
(3)查找操作
在链表中查找值为newElement的结点,如果找到则返回它在链表中的位置,否则返回为空。
Node * get(Node *plink,int i)
{
if(Null==plink)
return NULL;
int count=0;
Node * pNext=plink;
while (count<i && pNext !=NULL)
{
count++;
pNext=pNext->next;
}
return pNext;














 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









