






一、新旧API的区别
老版本(0.8及以前)Consumer会在zookeeper上记录和管理group信息,一旦consumer挂了,其他所有consumer都会接收到信息,会重新进行rebenlance
新版本(0.9及以上)kafka,每个broker都会有一个groupCoordinator,每个consumer都会有一个consumerCoordinator,并且引入了topic:__consumer_offsets来存储group信息,减轻zookeeper压力。
注意:__consumer_offsets topic不是broker集群启动就创建的,而是第一次消费时才会创建。service.properties中关于此topic的配置:partitions=50,offsets.topic.replication.factor=1
此时zookeeper上/consumers下没有group相关的信息了

二、分区分配算法
多个consumer同时消费一个topic,partition怎么分配? ==> 不管新版本还是旧版本,都提供了两种分区分配算法,都能确保一个partition只能给一个consumer线程消费,多余的consumer线程无法拿到数据。
-
1、kafka.consumer.RangeAssignor.java (这个是默认的,代码就不贴出来了,太多,自己用ide来看)
针对每一个topic进行计算,topic之间没有关联,算法逻辑如下:
1、先得到topic的有效分区数n,获取订阅了这个topic的所有消费者线程数m。 2、n / m 得到每个线程得到的分区数,剩下的余数分别给前面几个线程,一个线程多一个。举例子:
现在有topic T0,有分区[P0, P1, P2, P3, P4, P5, P6] topic T1,有分区[P0, P1, P2, P3, P4, P5, P6] 3个消费者线程(comsumer0, consumer1, consumer2)来消费,流程图如下:l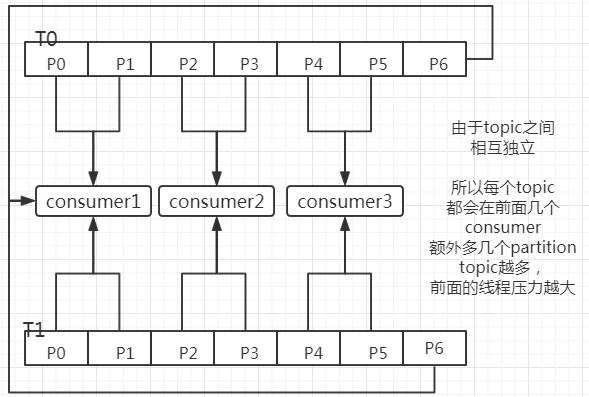
-
2、kafka.consumer.RoundRobinAssignor.java (代码就不贴出来了,太多,自己用ide来看)
也是针对每一个topic的所有分区进行处理,但是并不像上一个那样,每个topic都第一个consumer开始进行分配,而是循环遍历consumer,到哪个就是那个
1、获取groupID下订阅所有topic的有效分区,并且按照topic以及partitions进行排序,topicParMap 2、获取groupID下所有consumer,以及每个consumer订阅的topic,consumerTopicMap 3、循环遍历topicParMap,里面在循环遍历consumerTopicMap,如果consumer订阅了本topic,就把此partition给它,否则继续下一个consumer举例子
现同样有上述的条件,流程图如下(重点是T0的P6分配给consumer1后,T1的P0分配给了consumer2,从而T1的P6就会分配给了consumer2)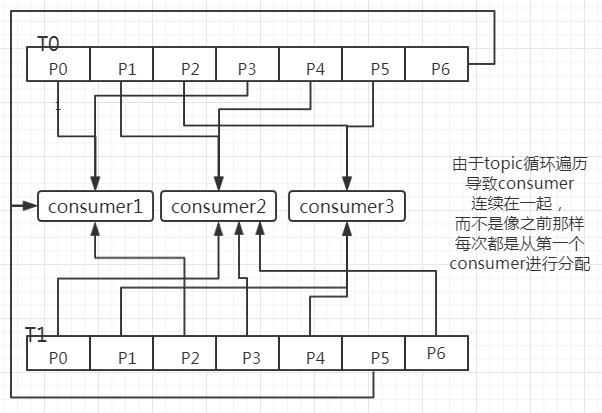
-
3、自定义分配类(一般用不上)
最简单的方式就是直接继承RangeAssignor或者RoundRobinAssignor,然后重写assign方法即可,或者和这两个类一样,直接实现PartitionAssignor也可以
最后在kafka consumer代码的参数配置那里配置上即可
public static ConsumerConfig initConf(){ Properties param = new Properties(); param.setProperty("zookeeper.connect", "192.168.0.186:2181,192.168.0.187:2181,192.168.0.189:2181,192.168.0.190:2181/kafka"); param.setProperty("group.id", "testGroup"); param.setProperty("auto.offset.reset", "largest"); // 设置自定义分区分配器 param.setProperty("partition.assignment.strategy", "com.study.kafka.MyAssignor"); return new ConsumerConfig(param); }
三、关于协调器coordinate
1、两个协调器,以及工作流程
每一个broker都有一个groupCoordinator,每一个consumer都有一个consumerCoordinator。
consumerCoordinator发送findCoordinator给任何一个broker
broker接收到后计算groupID.hash % 50 ==> __consumer_offsets对应分区,此分区所在broker就是此groupID对应的groupCoordinator
consumerCoordinator向groupCoordinator发送joinGroup请求加入group
consumerCoordinator向groupCoordinator发送sync请求获取自己分配到的partition
每间隔3S和groupCoordinator保持心跳
定时commit offset 给groupCoordinator,由它写入到__consumer_offsets
2、相关参数
-
heartbeat.interval.ms
心跳间隔。心跳是在 consumer 与 coordinator 之间进行的。心跳是确定 consumer 存活,加入或者退出 group 的有效手段。这个值必须设置的小于 session.timeout.ms,因为当 consumer 由于某种原因不能发 heartbeat 到 coordinator 时,并且时间超过 session.timeout.ms 时,就会认为该 consumer 已退出,它所订阅的 partition 会分配到同一 group 内的其它的 consumer 上。
默认值:3000 (3s),通常设置的值要低于session.timeout.ms的1/3。
-
session.timeout.ms
consumer session 过期时间。如果超时时间范围内,没有收到消费者的心跳,broker 会把这个消费者置为失效,并触发消费者负载均衡。因为只有在调用 poll 方法时才会发送心跳,更大的 session 超时时间允许消费者在 poll 循环周期内处理消息内容,尽管这会有花费更长时间检测失效的代价。如果想控制消费者处理消息的时间,
默认值:10000 (10s),这个值必须设置在 broker configuration 中的 group.min.session.timeout.ms 与 group.max.session.timeout.ms 之间。
-
max.poll.interval.ms
参数设置大一点可以增加两次 poll 之间处理消息的时间。
当 consumer 一切正常(也就是保持着 heartbeat ),且参数的值小于消息处理的时长,会导致 consumer leave group 然后又 rejoin group,触发无谓的 group balance,出现 consumer livelock 现象。
但如果设置的太大,会延迟 group rebalance,因为消费者只会在调用 poll 时加入rebalance。
-
max.poll.records
max.poll.interval.ms=5min max.poll.records=500即平均 600ms 要处理完一条消息,如果消息的消费时间高于 600ms,则一定要调整 max.poll.records 或 max.poll.interval.ms。
-
fetch.min.bytes=1
consumer去获取数据,如果不够1M了,则broker会延迟等待
四、相关问题
-
1、一个kafkaConsumer对象 不能给多线程并发访问,会报错
KafkaConsumer is not safe for multi-threaded access而producer就可以
实现原理:不是使用锁,而是使用前先判断是不是有人正在使用,如果是则报错
-
2、本机器hosts文件必须配置broker的ip映射,否则拿不到数据,也不会报错
-
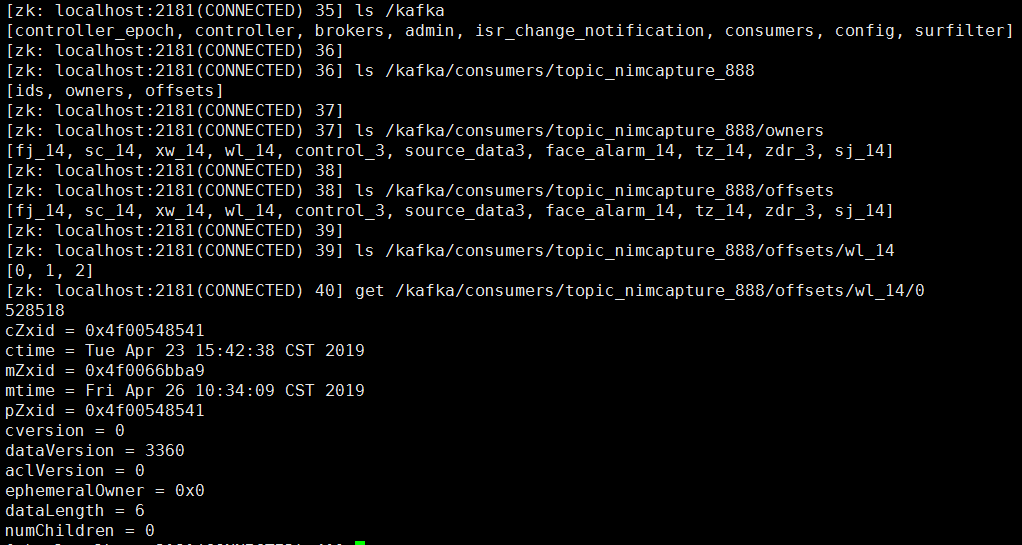
3、旧版本kafka consumer offset在zk上的位置
/kafka/consumers/zoo-consumer-group/offsets/my-topic/0















 7121
7121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









