






(一)HDFS的读流程
读操作对于Client客户端来说是透明操作,感觉就是连续的数据流
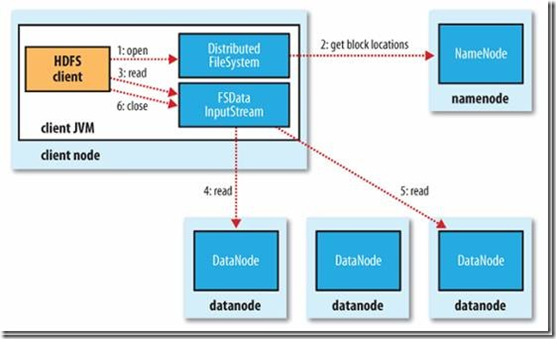
1、Client客戶端先通过FileSystem的open方法,向NameNode发起RPC远程过程调用请求,来得到NameNode上面的block块列表,同时NameNode也会返回包含block块的所有DataNode地址。相当于是NameNode向Client返回一个FSData.InputStream对象。
2、Client会选取离它最近的DataNode,通过调用FSData.InputStream对象的read方法去读取数据,如果DataNode在客户端上面,那就是在本地去直接获取数据。
3、当这一个block块的数据读取完毕之后,会关闭当前的DataNode的连接,然后重复第二步的操作,直到获取的所有的block块列表读取完毕。
4、当读完了block列表的时候,如果当前的NameNode读取还未结束,客户端会向NameNode再次获取block列表的信息。
5、每次Client向DataNode读取数据,都会进行check的检查操作,如果在向DataNode读取数据的过程中出现了错误,Client会将错误返回给NameNode,然后再从其他的DataNode上面读取自己需要的block。同时NameNode就会将这次的错误记录下来,下次就不会从这个DataNode去读取这个block块了。
(二)HDFS的写流程
写流程对于Client客户端来说也是透明操作,感觉就是连续的数据流
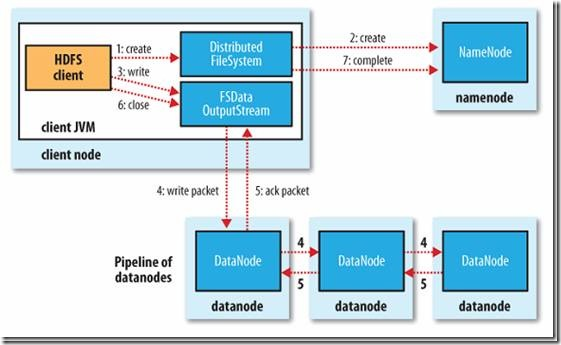
1、HDFS的Client客户端向DFS分布式文件系统调用一个create方法,通过RPC远程过程调用请求,向NameNoed去create一个文件,但是在create之前,NameNode会先去检查这个文件是否已经存在,以及用户是否有权限去创建这个文件,成功了才会创建,否则是会在客户端抛出异常的。
2、通过FSData的OutputStream对象,进行write操作,对DataNode的多个副本依次写过去。
3、当客户端开始写入文件的时候,Client客户端会将文件划分为多个packet(数据包),排成data queue(数据队列),然后DataStreamer会向NameNode去询问哪些DataNode最适合存储这几个新的blocks(如副本数是3,就找3个最适合的DataNode),
4、将这些分配的数据节点排成一个pipeline(管道),然后DataStreamer将packet按队列输出到pipeline管道里面的第一个DataNode,第一个DataNode将数据块再传给第二个DataNode,第二个再传给第三个,依次下去,直到pipeline里面的最后一个数据节点写入数据块完成,我们这里将副本数设置为3。
5、第三个(也就是最后一个节点)会返回一个ack packet确认包给第二个DataNode,表示我已经写入成功,第二个再传给第一个,第一个再返回给OutputStream,在Client客户端里面有一个ack queue队列,它从DataNode成功的接收到返回的packet包之后,ack queue会将相应的packet包移除。
6、最后调用close方法关闭,然后Client客户端再调用DFS的complete方法告诉NameNode,我已经写入成功了。
7、但是在写入的过程中,如果其中有DataNode发生错误,出现写入失败,它会被移除当前的pipeline管道,同时将已经写入的部分数据从这个错误的D其他的DataNode继续写入,然后NameNode会重新分配一台DataNode节点,以保证所需的副本数。















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









