







一、URL-俗称“网址”

HTTP 使用 URL(Uniform Resource Locator,统一资源定位符)来定位资源,它是 URI(Uniform Resource Identifier,统一资源标识符)的子集,URL 在 URI 的基础上增加了定位能力
URI 除了包含 URL,还包含 URN(Uniform Resource Name,统一资源名称),它只是用来定义一个资源的名称,并不具备定位该资源的能力
urlencode、urldecode
像 : / ? 等这样的字符, 已经被 url 当做特殊含义理解了,因此这些字符不能随意出现,否则需要对其进行转义
例如,‘+’ 经过 urlencode 被转义成了 “%2B”

而 urldecode 就是 urlencode 的逆过程
二、HTTP 报文
1、请求报文

- 第一行是请求行,包含用于请求的方法、URL 和 HTTP 版本

- 接下来的多行都是首部(Header),包含请求首部、通用首部、实体首部以及 HTTP 的 RFC 中未定义的其他首部(Cookie 等)
- 一个空行用来分隔首部和主体(Body),Body 允许为空字符串,如果 Body 存在, 则 Header 中会有一个 Content-Length 属性用于标识 Body 长度
2、响应报文

- 第一行是状态行,包含HTTP 版本、表明响应结果的状态码和状态码描述
- 接下来的多行都是首部(Header),包含响应首部、通用首部、实体首部以及 HTTP 的 RFC 中未定义的其他首部(Cookie 等)
- 一个空行用来分隔首部和主体(Body),Body 允许为空字符串,如果 Body 存在, 则 Header 中会有一个 Content-Length 属性用于标识 Body 长度
此时可能会有疑问,示例 Header 中也没有 Content-Length 属性啊,但请注意,服务器返回了一个 html 页面,而且 Header 中的 Transfer-Encoding(HTTP/1.1) 属性值是 chunked
三、HTTP 请求方法
| 方法 | 说明 | 支持的 HTTP 版本 | 注意 |
|---|---|---|---|
| GET | 获取资源 | 1.0、1.1 | 常用方法 |
| POST | 传输主体 | 1.0、1.1 | 常用方法 |
| PUT | 传输文件 | 1.0、1.1 | 鉴于 HTTP/1.1 的 PUT 方法自身不带验证机制,任何人都可以上传文件,存在安全问题,因此一般的 Web 网站不使用该方法 |
| HEAD | 获得报文首部 | 1.0、1.1 | |
| DELETE | 删除文件 | 1.0、1.1 | 鉴于 HTTP/1.1 的 DELETE 方法自身也不带验证机制,所以一般的 Web 网站也不使用该方法 |
| OPTIONS | 访问支持的方法 | 1.1 | |
| TRACE | 追踪路径 | 1.1 | 首先,TRACE 方法不怎么常用,其次,还容易受到 XST(Cross-Site Tracing,跨站追踪)攻击 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 | 主要使用 SSL(Secure Sockets Layer,安全套接层)和 TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输 |
| LINK | 建立和资源之间的联系 | 1.0 | |
| UNLIKE | 断开连接关系 | 1.0 |
四、HTTP 状态码
| 类别 | 原因短语 | |
|---|---|---|
| 1xx | Informational(信息性状态码) | 接收的请求正在处理 |
| 2xx | Success(成功状态码) | 请求正常处理完毕 |
| 3xx | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4xx | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5xx | Server Error(服务器错误状态码) | 服务器处理请求出错 |
五、HTTP 首部
1、首部
常见的首部见下:
- Content-Type:数据类型(text/html 等)
- Content-Length:Body 长度
- Host:客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上
- User-Agent:声明用户的操作系统和浏览器版本信息
- referer:当前页面是从哪个页面跳转过来的
- location:搭配 3xx 状态码使用, 告诉客户端接下来要去哪里访问
- Cookie:用于在客户端存储少量信息. 通常用于实现会话(session)功能
1.1、HTTP/1.1 首部
通用首部
| 首部名 | 说明 |
|---|---|
| Cache-Control | 控制缓存的行为 |
| Connection | 逐跳首部、连接的管理 |
| Date | 创建报文的日期时间 |
| Pragma | 报文指令 |
| Trailer | 报文末端的首部一览 |
| Transfer-Encoding | 指定报文主体的传输编码方式 |
| Upgrade | 升级为其他协议 |
| Via | 代理服务器的相关信息 |
| Warning | 错误通知 |
请求首部
| 首部名 | 说明 |
|---|---|
| Accept | 用户代理可处理的媒体类型 |
| Accept-Charset | 优先的字符集 |
| Accept-Encoding | 优先的内容编码 |
| Accept-Language | 优先的语言(自然语言) |
| Authorization | Web 认证信息 |
| Expect | 期待服务器的特定行为 |
| From | 用户的电子邮箱地址 |
| Host | 请求资源所在服务器 |
| If-Match | 比较实体标记(ETag) |
| If-Modified-Since | 比较资源的更新时间 |
| If-None-Match | 比较实体标记(与 If-Match 相反) |
| If-Range | 资源未更新时发送实体 Byte 的范围请求 |
| If-Unmodified-Since | 比较资源的更新时间(与 If-Modified-Since 相反) |
| Max-Forwards | 最大传输逐跳数 |
| Proxy-Authorization | 代理服务器要求客户端的认证信息 |
| Range | 实体的字节范围请求 |
| Referer | 对请求中 URL 的原始获取方 |
| TE | 传输编码的优先级 |
| User-Agent | HTTP 客户端程序的信息 |
响应首部
| 首部名 | 说明 |
|---|---|
| Accept-Ranges | 是否接受字节范围请求 |
| Age | 推送资源创建经过时间 |
| ETag | 资源的匹配信息 |
| Location | 令客户端重定向至指定 URL |
| Proxy-Authenticate | 代理服务器对客户端的认证信息 |
| Retry-After | 对再次发起请求的时机要求 |
| Server | HTTP 服务器的安装信息 |
| Vary | 代理服务器缓存的管理信息 |
| WWW-Authenticate | 服务器对客户端的认证信息 |
实体首部
| 首部名 | 说明 |
|---|---|
| Allow | 资源可支持的 HTTP 方法 |
| Content-Encoding | 主体适用的编码方式 |
| Content-Language | 主体的自然语言 |
| Content-Length | 主体的大小(单位:字节) |
| Content-Location | 替代对应资源的 URL |
| Content-MD5 | 主体的报文摘要 |
| Content-Range | 主体的位置范围 |
| Content-Type | 主体的媒体类型 |
| Expires | 主体过期的日期时间 |
| Last-Modified | 资源的最后修改日期时间 |
1.2、非 HTTP/1.1 的其他首部
在 HTTP/1.1 协议通信交互中使用到的首部,不限于 RFC2616 中定义的上述 47 种,还有一些非正式的首部,如 Cookie、Set-Cookie 和 Content-Dispostion 等都定义在 RFC4229 HTTP Header Field Registrations,它们的使用频率也很高
1.3、内容编码
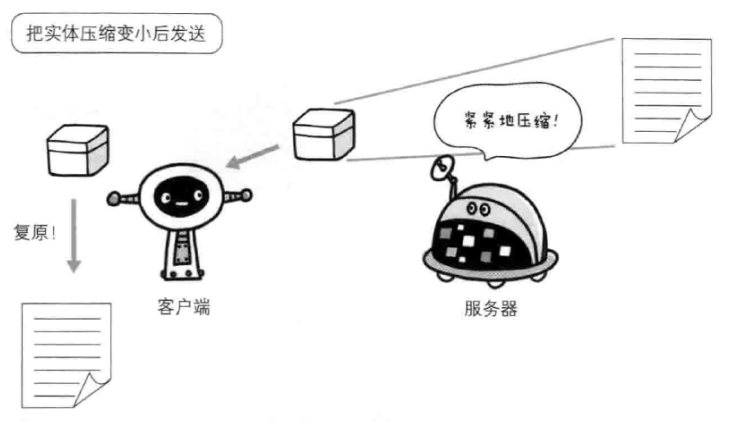
内容编码指将主体压缩,客户端负责解码,其中,常用的内容编码如下:
- gzip:GNU zip
- compress:UNIX 系统的标准压缩
- default:zlib
- identity:不进行压缩
1.4、分块传输编码(Chunked Transfer Encoding)
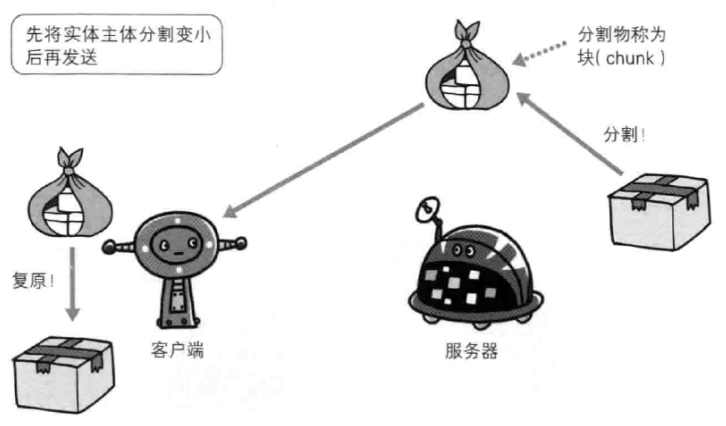
分块传输编码指将主体分块,每一块都会用十六进制来标记块的大小,而最后一块会使用 0(CR+LF) 来标记,客户端接收后进行解码,让浏览器逐步显示页面
1.5、多部分对象集合(Multipart)
报文内可含有多类型主体,另,多部分对象集合可以嵌套使用,而且,多部分对象集合的每个部分类型中,都可以含有首部
多部分对象集合包含的对象如下:
- multipart/from-data
在 Web 表单文件上传时使用

- multipart/byteranges
状态码 206 响应报文包含了多个范围的内容时使用

1.6、范围请求(Range Request)
如果在网络发生中断前,服务器只发送了部分数据,范围请求可以使客户端只请求服务器未发送的那部分数据,避免服务器重新发送全部数据




针对范围请求,响应会返回状态码为 206 的响应报文,另外,对于多重范围的范围请求,响应会在首部 Content-Type 标明 multipart/byteranges 后返回响应报文;如果服务器端无法响应范围请求,则会返回状态码 200 和完整的主体内容
1.7、内容协商(Content Negotiation)
内容协商机制是指客户端和服务器端就响应的资源内容进行交涉,然后提供给客户端最为适合的资源,例如,同一个 Web 网站有可能存在着多份相同内容的页面,比如英语版和中文版的 Web 页面,它们内容上虽相同,但使用的语言却不同,当浏览器的默认语言为英语或中文,访问相同 URL 的 Web 页面时,则会显示对应的英语版或中文版的 Web 页面
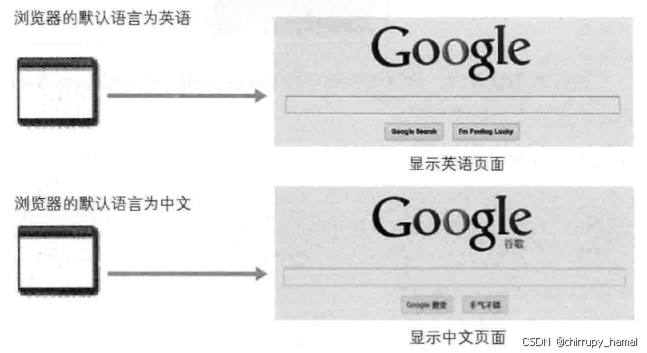
内容协商技术有以下 3 种:
- 服务器驱动协商(Server-driven Negotiation)
由服务器进行内容协商,以请求的首部(如下)为参考,在服务器端自动处理,但对用户来说,以浏览器发送的信息作为判断的依据,并不一定能筛选出最优内容- Accept
- Accept-Charset
- Accept-Encoding
- Accept-Language
- Content-Language
- 客户端驱动协商(Agent-driven Negotiation)
由客户端进行内容协商的方式,用户从浏览器显示的可选项列表中手动选择,还可以利用 JavaScript 脚本在 Web 也买你上自动进行上述选择,比如按 OS 的类型或浏览器类型,自行切换成 PC 版页面或手机版页面 - 透明协商(Transparent Negotiation)
是服务器驱动和客户端驱动的结合体,是由服务器端和客户端各自进行内容协商的一种方法
2、长短连接
HTTP 协议的初始版本中,每进行一次 HTTP 通信就要断开一次 TCP 连接

以当年的通信情况来说,因为都是些容量很小的文本传输,所以即使这样也没有多大问题,可随着 HTTP 的普及,文档中包含大量图片的情况多了起来,比如,使用浏览器浏览一个包含多张图片的 HTML 页面时,在发送请求访问 HTML 页面资源的同时,也会请求该 HTML 页面里包含的其他资源,因此,每次的请求都会造成无谓的 TCP 连接建立和断开,增加通信量的开销

为了解决上述 TCP 连接的问题,想出了持久连接(HTTP Persistent Connections,也称为 HTTP keep-alive 或 HTTP connection reuse)的方法,持久连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态

持久连接的好处在于减少了 TCP 连接的重复创建和断开所造成的额外开销,减轻了服务器端的负载,另外,减少开销的那部分时间,使 HTTP 请求和响应能够更早地结束,这样 Web 页面的显示速度也就相应提高了
HTTP/1.1,默认长连接,如果想断开连接,需要由客户端或服务器端任意一端使用 Connection: close 明确提出断开连接
HTTP/1.1 以前,默认短连接,如果想用长连接,需要指定 Connection: Keep-Alive
3.1、管线化(Pipelining)
持久连接使得多数请求以管线化方式发送成为可能,从前发送请求后需等待并收到响应,才能发送下一个请求,管线化技术出现后,不用等待响应亦可直接发送下一个请求,这样就能够做到同时并行发送多个请求,而不需要一个接一个地等待响应了
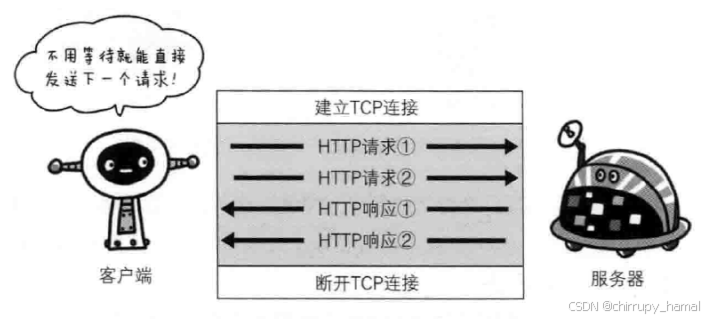
比如,当请求一个包含 10 张图片的 HTML Web 页面,与挨个连接相比,用持久连接可以让请求更快结束,而管线化技术则比持久连接还要快,请求数越多,时间差就越明显
管线化限制(RFC2616 §8.1.2.2)
- 服务器必须按照接收请求的相同顺序发送对应的响应
- 幂等请求(不会对服务器资源产生影响的请求有个专业名词叫做幂等请求)
因为管线化本身存在 HTTP 队头阻塞问题,以及幂等请求,实际上该技术的应用非常有限
3.2、并发长连接
RFC2616 明确限制浏览器对同一个域名可以建立两个长连接,但是一般浏览器会增加到 6 ~ 8 个,其中,谷歌浏览器是 6 个,也就是页面(不论标签页数量多少)中如果对同一个域名有多个 http 请求,谷歌浏览器会对这个域名建立 6 个 tcp 长连接,在每个长连接里面再去处理 http 请求,但是这种方案对服务器的挑战非常大,甚至有些 Web 优化方案还会突破 6 ~ 8 的限制,那就是域名切片,因为长连接针对的是同一个域名,如果开发人员将资源分布在不同的域名上,那么长连接的数量是可以被突破的
4、Cookie
HTTP 是一种不保存状态,即无状态(stateless)协议,HTTP 协议自身不对请求和响应之间的通信状态进行保存,也就是说在 HTTP 这个级别,协议对于发送过的请求或响应都不做持久化处理
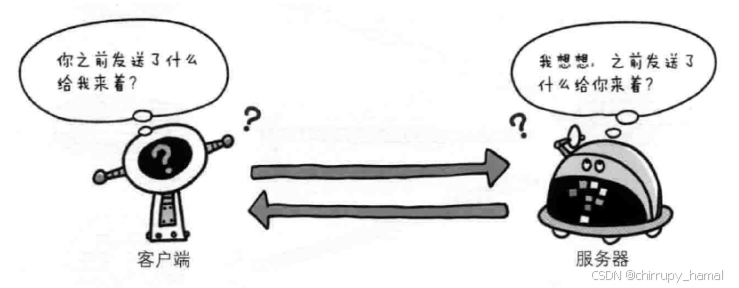
使用 HTTP 协议,每当有新的请求发送时,就会有对应的新响应产生,协议本身并不保留之前一切的请求或响应报文的信息,这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把 HTTP 协议设计成如此简单的,可是,随着 Web 的不断发展,因无状态而导致业务处理变得棘手的情况增多了,比如,用户登录到一家购物网站,即使他跳转到该站的其他页面后,也需要能继续保持登录状态,针对这个实例,网站为了能够掌握是谁送出的请求,需要保存用户的状态,HTTP/1.1 虽然是无状态协议,但为了实现期望的保持状态功能,于是引入了 Cookie 技术
Cookie 技术通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态,Cookie 会根据从服务器端发送的响应报文内的一个叫做 Set-cookie 的首部字段信息,通知客户端保存 Cookie,当下次客户端再往服务器发送请求时,客户端会自动在请求报文中加入 Cookie 值后发送出去,服务端发现客户端发送过来的 Cookie 后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息

上图展示了发生 Cookie 交互的场景,HTTP 请求报文和响应报文的内容如下:




















 1777
1777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









