



这次想讨论的话题是有关领域驱动设计,和领域驱动设计中使用贫血、失血or充血模型的。在这之前我想讨论下当前很多应用的问题,想起这个话题的起因是因为我在InfoQ上面看到这样一篇文章《Spring Web应用的最大瑕疵》,不得不说,这样的标题相当吸引人(′·ω·`)。内容和主要观点大概是这样的,现在大部分应用Spring框架的Java Web应用都相当关注单一职责原则和关注分离原则,但是在此之上却诞生了一些不太好的反模式和设计原则,比如:
- 领域模型对象只是用来存储应用的数据。(领域模型使用了贫血模型这种反模式)
- 业务逻辑位于服务层中,管理域对象的数据。
- 在服务层中,应用的每个实体对应一个服务类。
这类设计原则的应用非常广泛,我现在所在的Java Web项目就是使用这样的设计原则进行架构设计的,基本都是常见的三层或多层架构,他们大概是什么样的呢?
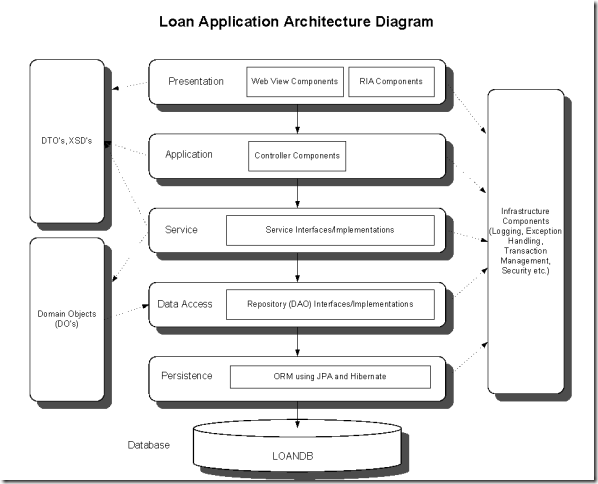
- Web层(俗称展现层吧,Presentation Layer):接收用户输入,将数据传至服务层;
- 服务层(Service Layer,可以叫Business Logic Layer):事务边界,处理业务逻辑、权限管理与授权,并与存储层通信;
- 存储层(Data access layer):与数据库进行通信,对数据进行持久化。
但是发现什么没有?问题出在了服务层,他承受了太多的职责,像事务管理、业务逻辑、权限检查等等,这违反了单一职责原则和关注分离原则,并且产生了大量的依赖和循环依赖。当业务复杂度上升时,服务层所包含的代码将会非常庞大和复杂,直接导致了测试成本的上升。
我这里正好有个例子,在现在的项目中,负责处理保险业务单的核心类中,包含了4000多行代码,它与数据库中某一关键表相关联,引用(注入)了十几个DAO。在数十个各类方法中,可以处理保单、再保、理赔等等各种不同的业务,同时它还深度依赖于hibernate,不但使用了ORM方法处理数据,甚至还直接用了HQL来获取数据。因为有众多其他服务类与他进行循环引用,项目后期这个庞然大物已经没有人敢轻易改动了,因为谁也不知道他到底都能做什么,重构更是不可能的事。
说了些服务层的坏话,那应该怎么改进呢?
- 首先,我们需要将业务逻辑从服务层移动到领域模型中,这样的好处是,服务层可以只负责应用逻辑(如数据有效性验证、授权检查、开始结束事务等),领域模型可以专门负责其相关的业务逻辑。还是以之前的保单系统来距离,架构设计时完全可以针对保单、再保、理赔等多个领域模型进行建模,相关的业务可以分别放到不同的领域模型中,一些很有可能重复的业务代码都会被集中到一处,从而降低了复制-粘贴的可能性。
- 其次,将服务类变得更小,使之只负责单一的职责。文章中有个例子,例如用户账户的CRUD和其他操作,就可以将其放到两个不同的服务类中,一个负责账户的CRUD操作,另外一个负责与用户账户相关的其他操作。
这样就能使服务类变得小巧、松散、可测试了,同时还能降低其他人理解与重用的成本。
接下来的问题就是,在实际的项目中,怎样实践这些设计原则呢?
这里有一篇《领域驱动设计和开发实践》非常值得一看,他所推崇的分层结构和上文所述类似,甚至提出了一些更细节的规则:
- 服务层需要包含应用逻辑、用户会话的管理,但不能包含领域逻辑、业务逻辑和数据访问逻辑;
- 领域层(领域对象)应该包含业务逻辑,可以处理与业务相关的会话状态.但作为商业应用的核心,应该具有良好的可移植性,不能对特定框架(如Struts、Hibernate、EJB等)产生依赖
说到这里,终于到了讨论的正题——贫血、失血和充血模型。什么是贫血失血充血模型呢?简单来说
- 失血模型:模型仅仅包含数据的定义和getter/setter方法,业务逻辑和应用逻辑都放到服务层中。这种类在java中叫POJO,在.NET中叫POCO。
- 贫血模型:贫血模型中包含了一些业务逻辑,但不包含依赖持久层的业务逻辑。这部分依赖于持久层的业务逻辑将会放到服务层中。可以看出,贫血模型中的领域对象是不依赖于持久层的。
- 充血模型:充血模型中包含了所有的业务逻辑,包括依赖于持久层的业务逻辑。所以,使用充血模型的领域层是依赖于持久层,简单表示就是UI层->服务层->领域层<->持久层
- 胀血模型:胀血模型就是把和业务逻辑不想关的其他应用逻辑(如授权、事务等)都放到领域模型中。我感觉胀血模型反而是另外一种的失血模型,因为服务层消失了,领域层干了服务层的事,到头来还是什么都没变。
可以看出来,失血模型和胀血模型都是不可取的,现在的问题是,贫血模型和充血模型哪个更加好一些。很久很久以前,人们针对这个问题进行了旷日持久的争论,最后仍然没有什么结果。这里有一些帖子可供回味:
贫血,充血模型的解释以及一些经验
总结一下最近关于domain object以及相关的讨论
双方争论的焦点主要在我上面加粗的两句话上,就是领域模型是否要依赖持久层,因为依赖持久层就意味着单元测试的展开要更加困难(无法脱离框架进行测试,原文的讨论中这里专指Hibernate),领域层就更难独立,将来也更难从应用程序中剥离出来,当然好处是业务逻辑不必混放在不同的层中,使得单一职责性体现的更好。而支持者(充血模型)认为,只要将持久层抽象出来,即可减少测试的困难性,同时适用充血模型毕竟带来了不少开发上的便利性,除了依赖持久层这一点,拥有更多好处的充血模型仍然值得选择。最后,谁也没能说服谁,关于贫血模型和充血模型的选择,更多的要靠具体的业务场景来决定,并不能说哪一种更比哪一种好。设计模式这种东西不是向来都没有什么定论么。
我个人则倾向使用充血模型,因为充血模型更加像一个设计完善的系统架构,好在计算机世界里有很多的IOC和DI框架,唯一的缺陷依赖持久层可以通过各种变通的方法绕过,随着技术的进步,一些缺陷也会被慢慢解决。我的思路是这样的:先将持久层抽象为接口,然后通过服务层将持久层注入到领域模型中,这样领域模型仅仅会依赖于持久层的接口。而这个接口,可以利用现有框架的技术进行抽象。举例来说,Java版Hibernate我了解不多,就以.NET的Entity Framework来说吧:
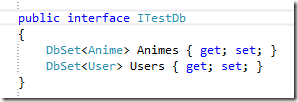
现在有这么一个DbContext,大家都懂得,DbContext和DbSet是非常不好Mock的两个类(我就是嫌麻烦而已,高手请无视),里面有两个表,一个叫Animes另一个叫Users

怎样设计接口才能使它既容易使用又可以方便测试呢?直接提取一个接口?DbSet不容易Mock的问题还是没有解决吧。
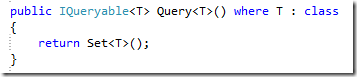
好在我们有LINQ和IQueryable<T>,随便改造一下,接口就变成了这样:

请注意Query<T>()方法,这个方法返回一个IQueryable<T>的对象,而实现了IQueryable的对象是支持LINQ操作的,也就是说,我们可以仍然可以将搜索的Expression交给真正的DbContext来做,而这个DbContext只需要简单一句话:
查询时从 from a in db.Anime.AsQueryable() 改成 from a in db.Query<Anime>(),一切都解决了。当你在单元测试中想要返回一个假的数据源的时候,直接让FakeDb.Query<T>()方法返回一个拥有假数据的List<T>.AsQueryable()就可以了。这样就实现了领域层和持久层的解耦,毕竟IQueryable是通用的嘛。
-------------------------------------
https://www.evernote.com/shard/s315/sh/a389cb28-9910-443b-8e30-4d1796dafe9d/2838ff81c0a65b966acda644ebb2300d
贫血,充血模型的解释以及一些经验
为了补大家的遗憾,在此总结下ROBBIN的领域模型的一些观点和大家的补充,在网站和演讲中,robbin将领域模型初步分为4大类:
1,失血模型
2,贫血模型
3,充血模型
4,胀血模型
那么让我们看看究竟有这些领域模型的具体内容,以及他们的优缺点:
一、失血模型
失血模型简单来说,就是domain object只有属性的getter/setter方法的纯数据类,所有的业务逻辑完全由business object来完成(又称TransactionScript),这种模型下的domain object被Martin Fowler称之为“贫血的domain object”。下面用举一个具体的代码来说明,代码来自Hibernate的caveatemptor,但经过我的改写:
一个实体类叫做Item,指的是一个拍卖项目
一个DAO接口类叫做ItemDao
一个DAO接口实现类叫做ItemDaoHibernateImpl
一个业务逻辑类叫做ItemManager(或者叫做ItemService)
java代码:
- public class Item implements Serializable {
- private Long id = null;
- private int version;
- private String name;
- private User seller;
- private String description;
- private MonetaryAmount initialPrice;
- private MonetaryAmount reservePrice;
- private Date startDate;
- private Date endDate;
- private Set categorizedItems = new HashSet();
- private Collection bids = new ArrayList();
- private Bid successfulBid;
- private ItemState state;
- private User approvedBy;
- private Date approvalDatetime;
- private Date created = new Date();
- // getter/setter方法省略不写,避免篇幅太长
- }
java代码:
- public interface ItemDao {
- public Item getItemById(Long id);
- public Collection findAll();
- public void updateItem(Item item);
- }
ItemDao定义持久化操作的接口,用于隔离持久化代码。
java代码:
- public class ItemDaoHibernateImpl implements ItemDao extends HibernateDaoSupport {
- public Item getItemById(Long id) {
- return (Item) getHibernateTemplate().load(Item.class, id);
- }
- public Collection findAll() {
- return (List) getHibernateTemplate().find("from Item");
- }
- public void updateItem(Item item) {
- getHibernateTemplate().update(item);
- }
- }
ItemDaoHibernateImpl完成具体的持久化工作,请注意,数据库资源的获取和释放是在ItemDaoHibernateImpl里面处理的,每个DAO方法调用之前打开Session,DAO方法调用之后,关闭Session。(Session放在ThreadLocal中,保证一次调用只打开关闭一次)
java代码:
- public class ItemManager {
- private ItemDao itemDao;
- public void setItemDao(ItemDao itemDao) { this.itemDao = itemDao;}
- public Bid loadItemById(Long id) {
- itemDao.loadItemById(id);
- }
- public Collection listAllItems() {
- return itemDao.findAll();
- }
- public Bid placeBid(Item item, User bidder, MonetaryAmount bidAmount,
- Bid currentMaxBid, Bid currentMinBid) throws BusinessException {
- if (currentMaxBid != null && currentMaxBid.getAmount().compareTo(bidAmount) > 0) {
- throw new BusinessException("Bid too low.");
- }
- // Auction is active
- if ( !state.equals(ItemState.ACTIVE) )
- throw new BusinessException("Auction is not active yet.");
- // Auction still valid
- if ( item.getEndDate().before( new Date() ) )
- throw new BusinessException("Can't place new bid, auction already ended.");
- // Create new Bid
- Bid newBid = new Bid(bidAmount, item, bidder);
- // Place bid for this Item
- item.getBids().add(newBid);
- itemDao.update(item); // 调用DAO完成持久化操作
- return newBid;
- }
- }
事务的管理是在ItemManger这一层完成的,ItemManager实现具体的业务逻辑。除了常见的和CRUD有关的简单逻辑之外,这里还有一个placeBid的逻辑,即项目的竞标。
以上是一个完整的第一种模型的示例代码。在这个示例中,placeBid,loadItemById,findAll等等业务逻辑统统放在ItemManager中实现,而Item只有getter/setter方法。
二、贫血模型
简单来说,就是domain ojbect包含了不依赖于持久化的领域逻辑,而那些依赖持久化的领域逻辑被分离到Service层。
Service(业务逻辑,事务封装) --> DAO ---> domain object
这也就是Martin Fowler指的rich domain object :
一个带有业务逻辑的实体类,即domain object是Item
一个DAO接口ItemDao
一个DAO实现ItemDaoHibernateImpl
一个业务逻辑对象ItemManager
java代码:
- public class Item implements Serializable {
- // 所有的属性和getter/setter方法同上,省略
- public Bid placeBid(User bidder, MonetaryAmount bidAmount,
- Bid currentMaxBid, Bid currentMinBid)
- throws BusinessException {
- // Check highest bid (can also be a different Strategy (pattern))
- if (currentMaxBid != null && currentMaxBid.getAmount().compareTo(bidAmount) > 0) {
- throw new BusinessException("Bid too low.");
- }
- // Auction is active
- if ( !state.equals(ItemState.ACTIVE) )
- throw new BusinessException("Auction is not active yet.");
- // Auction still valid
- if ( this.getEndDate().before( new Date() ) )
- throw new BusinessException("Can't place new bid, auction already ended.");
- // Create new Bid
- Bid newBid = new Bid(bidAmount, this, bidder);
- // Place bid for this Item
- this.getBids.add(newBid); // 请注意这一句,透明的进行了持久化,但是不能在这里调用ItemDao,Item不能对ItemDao产生
- 依赖!
- return newBid;
- }
- }
竞标这个业务逻辑被放入到Item中来。请注意this.getBids.add(newBid); 如果没有Hibernate或者JDO这种O/R Mapping的支持,我们是无法实现这种透明的持久化行为的。但是请注意,Item里面不能去调用ItemDAO,对ItemDAO产生依赖!
ItemDao和ItemDaoHibernateImpl的代码同上,省略。
java代码:
- public class ItemManager {
- private ItemDao itemDao;
- public void setItemDao(ItemDao itemDao) { this.itemDao = itemDao;}
- public Bid loadItemById(Long id) {
- itemDao.loadItemById(id);
- }
- public Collection listAllItems() {
- return itemDao.findAll();
- }
- public Bid placeBid(Item item, User bidder, MonetaryAmount bidAmount,
- Bid currentMaxBid, Bid currentMinBid) throws BusinessException {
- item.placeBid(bidder, bidAmount, currentMaxBid, currentMinBid);
- itemDao.update(item); // 必须显式的调用DAO,保持持久化
- }
- }
在第二种模型中,placeBid业务逻辑是放在Item中实现的,而loadItemById和findAll业务逻辑是放在ItemManager中实现的。不过值得注意的是,即使placeBid业务逻辑放在Item中,你仍然需要在ItemManager中简单的封装一层,以保证对placeBid业务逻辑进行事务的管理和持久化的触发。
这种模型是Martin Fowler所指的真正的domain model。在这种模型中,有三个业务逻辑方法:placeBid,loadItemById和findAll,现在的问题是哪个逻辑应该放在Item中,哪个逻辑应该放在ItemManager中。在我们这个例子中,placeBid放在Item中(但是ItemManager也需要对它进行简单的封装),loadItemById和findAll是放在ItemManager中的。
切分的原则是什么呢? Rod Johnson提出原则是“case by case”,可重用度高的,和domain object状态密切关联的放在Item中,可重用度低的,和domain object状态没有密切关联的放在ItemManager中。
经过上面的讨论,如何区分domain logic和business logic,我想提出一个改进的区分原则:domain logic只应该和这一个domain object的实例状态有关,而不应该和一批domain object的状态有关;当你把一个logic放到domain object中以后,这个domain object应该仍然独立于持久层框架之外(Hibernate,JDO),这个domain object仍然可以脱离持久层框架进行单元测试,这个domain object仍然是一个完备的,自包含的,不依赖于外部环境的领域对象,这种情况下,这个logic才是domain logic。
这里有一个很确定的原则:logic是否只和这个object的状态有关,如果只和这个object有关,就是domain logic;如果logic是和一批domain object的状态有关,就不是domain logic,而是business logic。
Item的placeBid这个业务逻辑方法没有显式的对持久化ItemDao接口产生依赖,所以要放在Item中。请注意,如果脱离了Hibernate这个持久化框架,Item这个domain object是可以进行单元测试的,他不依赖于Hibernate的持久化机制。它是一个独立的,可移植的,完整的,自包含的域对象。而loadItemById和findAll这两个业务逻辑方法是必须显式的对持久化ItemDao接口产生依赖,否则这个业务逻辑就无法完成。如果你要把这两个方法放在Item中,那么Item就无法脱离Hibernate框架,无法在Hibernate框架之外独立存在。
这种模型的优点:
1、各层单向依赖,结构清楚,易于实现和维护
2、设计简单易行,底层模型非常稳定
这种模型的缺点:
1、domain object的部分比较紧密依赖的持久化domain logic被分离到Service层,显得不够OO
2、Service层过于厚重
三、充血模型
充血模型和第二种模型差不多,所不同的就是如何划分业务逻辑,即认为,绝大多业务逻辑都应该被放在domain object里面(包括持久化逻辑),而Service层应该是很薄的一层,仅仅封装事务和少量逻辑,不和DAO层打交道。
Service(事务封装) ---> domain object <---> DAO
这种模型就是把第二种模型的domain object和business object合二为一了。所以ItemManager就不需要了,在这种模型下面,只有三个类,他们分别是:
Item:包含了实体类信息,也包含了所有的业务逻辑
ItemDao:持久化DAO接口类
ItemDaoHibernateImpl:DAO接口的实现类
由于ItemDao和ItemDaoHibernateImpl和上面完全相同,就省略了。
java代码:
- public class Item implements Serializable {
- // 所有的属性和getter/setter方法都省略
- private static ItemDao itemDao;
- public void setItemDao(ItemDao itemDao) {this.itemDao = itemDao;}
- public static Item loadItemById(Long id) {
- return (Item) itemDao.loadItemById(id);
- }
- public static Collection findAll() {
- return (List) itemDao.findAll();
- }
- public Bid placeBid(User bidder, MonetaryAmount bidAmount,
- Bid currentMaxBid, Bid currentMinBid)
- throws BusinessException {
- // Check highest bid (can also be a different Strategy (pattern))
- if (currentMaxBid != null && currentMaxBid.getAmount().compareTo(bidAmount) > 0) {
- throw new BusinessException("Bid too low.");
- }
- // Auction is active
- if ( !state.equals(ItemState.ACTIVE) )
- throw new BusinessException("Auction is not active yet.");
- // Auction still valid
- if ( this.getEndDate().before( new Date() ) )
- throw new BusinessException("Can't place new bid, auction already ended.");
- // Create new Bid
- Bid newBid = new Bid(bidAmount, this, bidder);
- // Place bid for this Item
- this.addBid(newBid);
- itemDao.update(this); // 调用DAO进行显式持久化
- return newBid;
- }
- }
在这种模型中,所有的业务逻辑全部都在Item中,事务管理也在Item中实现。
这种模型的优点:
1、更加符合OO的原则
2、Service层很薄,只充当Facade的角色,不和DAO打交道。
这种模型的缺点:
1、DAO和domain object形成了双向依赖,复杂的双向依赖会导致很多潜在的问题。
2、如何划分Service层逻辑和domain层逻辑是非常含混的,在实际项目中,由于设计和开发人员的水平差异,可能导致整个结构的混乱无序。
3、考虑到Service层的事务封装特性,Service层必须对所有的domain object的逻辑提供相应的事务封装方法,其结果就是Service完全重定义一遍所有的domain logic,非常烦琐,而且Service的事务化封装其意义就等于把OO的domain logic转换为过程的Service TransactionScript。该充血模型辛辛苦苦在domain层实现的OO在Service层又变成了过程式,对于Web层程序员的角度来看,和贫血模型没有什么区别了。
1.事务我是不希望由Item管理的,而是由容器或更高一层的业务类来管理。
2.如果Item不脱离持久层的管理,如JDO的pm,那么itemDao.update(this); 是不需要的,也就是说Item是在事务过程中从数据库拿出来的,并且声明周期不超出当前事务的范围。
3.如果Item是脱离持久层,也就是在Item的生命周期超出了事务的范围,那就要必须显示调用update或attach之类的持久化方法的,这种时候就应该是按robbin所说的第2种模型来做。
四、胀血模型
基于充血模型的第三个缺点,有同学提出,干脆取消Service层,只剩下domain object和DAO两层,在domain object的domain logic上面封装事务。
domain object(事务封装,业务逻辑) <---> DAO
似乎ruby on rails就是这种模型,他甚至把domain object和DAO都合并了。
该模型优点:
1、简化了分层
2、也算符合OO
该模型缺点:
1、很多不是domain logic的service逻辑也被强行放入domain object ,引起了domain ojbect模型的不稳定
2、domain object暴露给web层过多的信息,可能引起意想不到的副作用。
评价:
在这四种模型当中,失血模型和胀血模型应该是不被提倡的。而贫血模型和充血模型从技术上来说,都已经是可行的了。但是我个人仍然主张使用贫血模型。其理由:
1、参考充血模型第三个缺点,由于暴露给web层程序拿到的还是Service Transaction Script,对于web层程序员来说,底层OO意义丧失了。
2、参考充血模型第三个缺点,为了事务封装,Service层要给每个domain logic提供一个过程化封装,这对于编程来说,做了多余的工作,非
常烦琐。
3、domain object和DAO的双向依赖在做大项目中,考虑到团队成员的水平差异,很容易引入不可预知的潜在bug。
4、如何划分domain logic和service logic的标准是不确定的,往往要根据个人经验,有些人就是觉得某个业务他更加贴近domain,也有人认
为这个业务是贴近service的。由于划分标准的不确定性,带来的后果就是实际项目中会产生很多这样的争议和纠纷,不同的人会有不同的划分
方法,最后就会造成整个项目的逻辑分层混乱。这不像贫血模型中我提出的按照是否依赖持久化进行划分,这种标准是非常确定的,不会引起争议,因此团队开发中,不会产生此类问题。
5、贫血模型的domain object确实不够rich,但是我们是做项目,不是做研究,好用就行了,管它是不是那么纯的OO呢?其实我不同意firebody认为的贫血模型在设计模型和实现代码中有很大跨越的说法。一个设计模型到实现的时候,你直接得到两个类:一个实体类,一个控制类就行了,没有什么跨越。
简单评价一下:
第一种模型绝大多数人都反对,因此反对理由我也不多讲了。但遗憾的是,我观察到的实际情形是,很多使用Hibernate的公司最后都是这种模型,这里面有很大的原因是很多公司的技术水平没有达到这种层次,所以导致了这种贫血模型的出现。从这一点来说,Martin Fowler的批评声音不是太响了,而是太弱了,还需要再继续呐喊。
第二种模型就是Martin Fowler一直主张的模型,实际上也是我一直在实际项目中采用这种模型。我没有看过Martin的POEAA,之所以能够自己摸索到这种模型,也是因为从02年我已经开始思考这个问题并且寻求解决方案了,但是当时没有看到Hibernate,那时候做的一个小型项目我已经按照这种模型来做了,但是由于没有O/R Mapping的支持,写到后来又不得不全部改成贫血的domain object,项目做完以后再继续找,随后就发现了Hibernate。当然,现在很多人一开始就是用Hibernate做项目,没有经历过我经历的那个阶段。
不过我觉得这种模型仍然不够完美,因为你还是需要一个业务逻辑层来封装所有的domain logic,这显得非常罗嗦,并且业务逻辑对象的接口也不够稳定。如果不考虑业务逻辑对象的重用性的话(业务逻辑对象的可重用性也不可能好),很多人干脆就去掉了xxxManager这一层,在Web层的Action代码直接调用xxxDao,同时容器事务管理配置到Action这一层上来。Hibernate的caveatemptor就是这样架构的一个典型应用。
第三种模型是我很反对的一种模型,这种模型下面,Domain Object和DAO形成了双向依赖关系,无法脱离框架测试,并且业务逻辑层的服务也和持久层对象的状态耦合到了一起,会造成程序的高度的复杂性,很差的灵活性和糟糕的可维护性。也许将来技术进步导致的O/R Mapping管理下的domain object发展到足够的动态持久透明化的话,这种模型才会成为一个理想的选择。就像O/R Mapping的流行使得第二种模型成为了可能Martin Fowler的Domain Model,或者说我们的第二种模型难道是完美无缺的吗?当然不是,接下来我就要分析一下它的不足,以及可能的解决办法,而这些都来源于我个人的实践探索。
在第二种模型中,我们可以清楚的把这4个类分为三层:
1、实体类层,即Item,带有domain logic的domain object
2、DAO层,即ItemDao和ItemDaoHibernateImpl,抽象持久化操作的接口和实现类
3、业务逻辑层,即ItemManager,接受容器事务控制,向Web层提供统一的服务调用在这三层中我们大家可以看到,domain object和DAO都是非常稳定的层,其实原因也很简单,因为domain object是映射数据库字段的,数据库字段不会频繁变动,所以domain object也相对稳定,而面向数据库持久化编程的DAO层也不过就是CRUD而已,不会有更多的花样,所以也很稳定。
问题就在于这个充当business workflow facade的业务逻辑对象,它的变动是相当频繁的。业务逻辑对象通常都是无状态的、受事务控制的、Singleton类,我们可以考察一下业务逻辑对象都有哪几类业务逻辑方法:
第一类:DAO接口方法的代理,就是上面例子中的loadItemById方法和findAll方法。ItemManager之所以要代理这种类,目的有两个:向Web层提供统一的服务调用入口点和给持久化方法增加事务控制功能。这两点都很容易理解,你不能既给Web层程序员提供xxxManager,也给他提供xxxDao,所以你需要用xxxManager封装xxxDao,在这里,充当了一个简单代理功能;而事务控制也是持久化方法必须的,事务可能需要跨越多个DAO方法调用,所以必须放在业务逻辑层,而不能放在DAO层。
但是必须看到,对于一个典型的web应用来说,绝大多数的业务逻辑都是简单的CRUD逻辑,所以这种情况下,针对每个DAO方法,xxxManager都需要提供一个对应的封装方法,这不但是非常枯燥的,也是令人感觉非常不好的。
第二类:domain logic的方法代理。就是上面例子中placeBid方法。虽然Item已经有了placeBid方法,但是ItemManager仍然需要封装一下Item 的placeBid,然后再提供一个简单封装之后的代理方法。这和第一种情况类似,其原因也一样,也是为了给Web层提供一个统一的服务调用入口点和给隐式的持久化动作提供事务控制。同样,和第一种情况一样,针对每个domain logic方法,xxxManager都需要提供一个对应的封装方法,同样是枯燥的,令人不爽的。
第三类:需要多个domain object和DAO参与协作的business workflow。这种情况是业务逻辑对象真正应该完成的职责。
在这个简单的例子中,没有涉及到这种情况,不过大家都可以想像的出来这种应用场景,因此不必举例说明了。
通过上面的分析可以看出,只有第三类业务逻辑方法才是业务逻辑对象真正应该承担的职责,而前两类业务逻辑方法都是“无奈之举”,不得不为之的事情,不但枯燥,而且令人沮丧。
分析完了业务逻辑对象,我们再回头看一下domain object,我们要仔细考察一下domain logic的话,会发现domain logic也分为两类:
第一类:需要持久层框架隐式的实现透明持久化的domain logic,例如Item的placeBid方法中的这一句:
java代码:
- this.getBids().add(newBid);
上面已经着重提到,虽然这仅仅只是一个Java集合的添加新元素的操作,但是实际上通过事务的控制,会潜在的触发两条SQL:一条是insert一条记录到bid表,一条是更新item表相应的记录。如果我们让Item脱离Hibernate进行单元测试,它就是一个单纯的Java集合操作,如果我们把他加入到Hibernate框架中,他就会潜在的触发两条SQL,这就是隐式的依赖于持久化的domain logic。
特别请注意的一点是:在没有Hibernate/JDO这类可以实现“透明的持久化”工具出现之前,这类domain logic是无法实现的。对于这一类domain logic,业务逻辑对象必须提供相应的封装方法,以实现事务控制。
第二类:完全不依赖持久化的domain logic,例如readonly例子中的Topic,如下:
java代码:
- class Topic {
- boolean isAllowReply() {
- Calendar dueDate = Calendar.getInstance();
- dueDate.setTime(lastUpdatedTime);
- dueDate.add(Calendar.DATE, forum.timeToLive);
- Date now = new Date();
- return now.after(dueDate.getTime());
- }
- }
注意这个isAllowReply方法,他和持久化完全不发生一丁点关系。在实际的开发中,我们同样会遇到很多这种不需要持久化的业务逻辑(主要发生在日期运算、数值运算和枚举运算方面),这种domain logic不管脱离不脱离所在的框架,它的行为都是一致的。对于这种domain logic,业务逻辑层并不需要提供封装方法,它可以适用于任何场合。概括说:action做为控制器 ,service面向use case,domain object是中间稳定的一层,dao是作为下层的服务,提供持久化服务,可以被domain object所使用。
针对上面帖子中分析的业务逻辑对象的方法有三类的情况,我们在实际的项目中会遇到一些困扰。主要的困扰就是业务逻辑对象的方法会变动的相当频繁,并且业务逻辑对象的方法数量会非常庞大。针对这个问题,我所知道的有两种解决方案,我姑且称之为第二种模型的两类变种:
第一类变种就是partech的那种模型,简单的来说,就是把业务逻辑对象层和DAO层合二为一;第二类变种就是干脆取消业务逻辑层,把事务控制前推至Web层的Action层来处理,下面分别分析一下两类变种的优缺点:
第一类变种是合并业务逻辑对象和DAO层,这种设计代码简化为3个类,如下所示:
一个domain object:Item(同第二种模型的代码,省略)
一个业务层接口:ItemManager(合并原来的ItemManager方法签名和ItemDao接口而来)
一个业务层实现类:ItemManagerHibernateImpl(合并原来的ItemManager方法实现和ItemDaoHibernateImpl)
java代码:
- public interface ItemManager {
- public Item loadItemById(Long id);
- public Collection findAll();
- public void updateItem(Item item);
- public Bid placeBid(Item item, User bidder, MonetaryAmount bidAmount, Bid currentMaxBid, Bid currentMinBid) throws
- BusinessException;
- }
java代码:
- public class ItemManagerHibernateImpl implements ItemManager extends HibernateDaoSupport {
- public Item loadItemById(Long id) {
- return (Item) getHibernateTemplate().load(Item.class, id);
- }
- public Collection findAll() {
- return (List) getHibernateTemplate().find("from Item");
- }
- public void updateItem(Item item) {
- getHibernateTemplate().update(item);
- }
- public Bid placeBid(Item item, User bidder, MonetaryAmount bidAmount, Bid currentMaxBid, Bid currentMinBid) throws
- BusinessException {
- item.placeBid(bidder, bidAmount, currentMaxBid, currentMinBid);
- updateItem(item); // 确保持久化item
- }
- }
第二种模型的第一类变种把业务逻辑对象和DAO层合并到了一起。
考虑到典型的web应用中,简单的CRUD操作占据了业务逻辑的绝大多数比例,因此第一类变种的优点是:避免了业务逻辑不得不大量封装DAO接口的问题,简化了软件架构设计,节省了大量的业务层代码量。
这种方案的缺点是:把DAO接口方法和业务逻辑方法混合到了一起,显得职责不够单一化,软件分层结构不够清晰;此外这种方案仍然不得不对隐式依赖持久化的domain logic提供封装方法,未能做到彻底的简化。
总体而言,个人认为这种变种各方面权衡下来,是目前相对最为合理方案,这也是我目前项目中采用的架构。
第二种模型的第二类变种就是干脆取消ItemManager,保留原来的Item,ItemDao,ItemDaoHibernateImpl这3个类。在这种情况下把事务控制前推至Web层的Action去控制,具体来说,就是直接对Action的execute()方法进行容器事务声明。
这种方式的优点是:极大的简化了业务逻辑层,避免了业务逻辑对象不得不大量封装DAO接口方法和大量封装domain logic的问题。对于业务逻辑非常简单的项目,采用这种方案是一个非常合适的选择。
这种方式的缺点主要有3个:
1) 由于彻底取消了业务逻辑对象层,对于那些有重用需要的、多个domain object和多个DAO参与的、复杂业务逻辑流程来说,你不得不在Action中一遍又一遍的重复实现这部分代码,效率既低,也不利于软件重用。
2) Web层程序员需要对持久层机制有相当高程度的了解和掌握,必须知道什么时候应该调用什么DAO方法进行必要的持久化。
3) 事务的范围被扩大了。假设你在一个Action中,首先需要插入一条记录,然后再需要查询数据库,显示一个记录列表,对于这种情况,事务的作用范围应该是在插入记录的前后,但是现在扩大到了整个execute执行期间。如果插入动作完毕,查询动作过程中出现通往数据库服务器的网络异常,那么前面的插入动作将回滚,但是实际上我们期望的是插入应该被提交。
总体而言,这种变种的缺陷比较大,只适合在业务逻辑非常简单的小型项目中,值得一提的是Hibernate的caveatemptor就是采用这种变种的架构,大家可以参考一下。
综上所述,在采用Rich Domain Object模型的三种解决方案中(第二模型,第二模型第一变种,第二模型第二变种),我认为权衡下来,第二模型的第一变种是相对最好的解决方案,不过它仍然有一定的不足,在这里我也希望大家能够提出更好的解决方案。
,partech 提出了 实体控制对象 和 实体对象 两种不同层次的 Domain Object ,由于 Domain Object 可以依赖于 XXXFinderDAO,因此,也就不存在“大数据量问题”,因此,整个 Domain 体系,对于实际业务表述的更为完整,更为一体化。我非常倾向这种方式。
一般是这样的顺序:
Client-->Service-->D Object-->DAO-->DB
至于哪些该放在哪里,基本有这样的原则:(就是robbin的第二种了)
DO封装内在的业务逻辑
Service 封装外在于DO的业务逻辑
当然如果业务逻辑简单或者没有的话也可以:
Client-->D Object-->DAO-->DB
对于第二种的第一个变种固然是个好办法,但如Robbin所说也有缺陷如果有多个Servcie要调用DAO的话,就有问题了。合并也意味中不能很好的重用。
说到底就是粒度的问题,分得细重用好,但类多、结构复杂、繁琐。分得粗(干脆用一个类干所有的事)重用差,但类少、结构简单。

















 9864
9864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









